 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniFC: Rethinking Federated Clustering via Lossless and Secure Distance Reconstruction
May 19, 2025Federated clustering (FC) aims to discover global cluster structures across decentralized clients without sharing raw data, making privacy preservation a fundamental requirement. There are two critical challenges: (1) privacy leakage during collaboration, and (2) robustness degradation due to aggregation of proxy information from non-independent and identically distributed (Non-IID) local data, leading to inaccurate or inconsistent global clustering. Existing solutions typically rely on model-specific local proxies, which are sensitive to data heterogeneity and inherit inductive biases from their centralized counterparts, thus limiting robustness and generality. We propose Omni Federated Clustering (OmniFC), a unified and model-agnostic framework. Leveraging Lagrange coded computing, our method enables clients to share only encoded data, allowing exact reconstruction of the global distance matrix--a fundamental representation of sample relationships--without leaking private information, even under client collusion. This construction is naturally resilient to Non-IID data distributions. This approach decouples FC from model-specific proxies, providing a unified extension mechanism applicable to diverse centralized clustering methods. Theoretical analysis confirms both reconstruction fidelity and privacy guarantees, while comprehensive experiments demonstrate OmniFC's superior robustness, effectiveness, and generality across various benchmarks compared to state-of-the-art methods. Code will be released.
CCFC++: Enhancing Federated Clustering through Feature Decorrelation
Feb 20, 2024In federated clustering, multiple data-holding clients collaboratively group data without exchanging raw data. This field has seen notable advancements through its marriage with contrastive learning, exemplified by Cluster-Contrastive Federated Clustering (CCFC). However, CCFC suffers from heterogeneous data across clients, leading to poor and unrobust performance. Our study conducts both empirical and theoretical analyses to understand the impact of heterogeneous data on CCFC. Findings indicate that increased data heterogeneity exacerbates dimensional collapse in CCFC, evidenced by increased correlations across multiple dimensions of the learned representations. To address this, we introduce a decorrelation regularizer to CCFC. Benefiting from the regularizer, the improved method effectively mitigates the detrimental effects of data heterogeneity, and achieves superior performance, as evidenced by a marked increase in NMI scores, with the gain reaching as high as 0.32 in the most pronounced case.
CCFC: Bridging Federated Clustering and Contrastive Learning
Jan 12, 2024
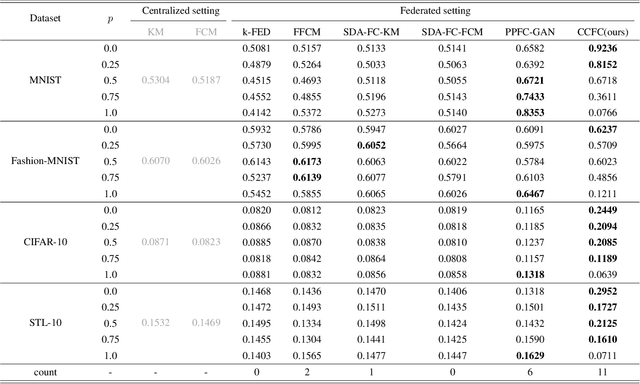
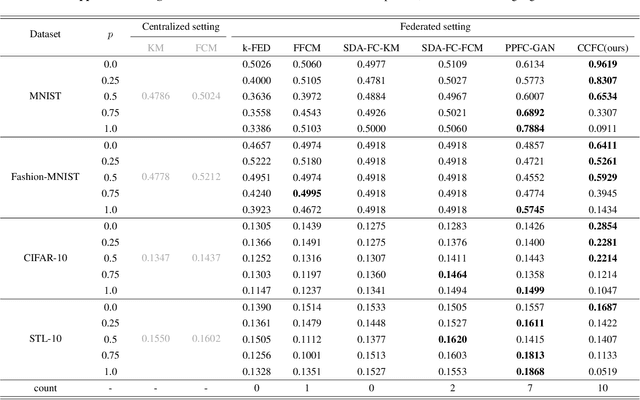
Federated clustering, an essential extension of centralized clustering for federated scenarios, enables multiple data-holding clients to collaboratively group data while keeping their data locally. In centralized scenarios, clustering driven by representation learning has made significant advancements in handling high-dimensional complex data. However, the combination of federated clustering and representation learning remains underexplored. To bridge this, we first tailor a cluster-contrastive model for learning clustering-friendly representations. Then, we harness this model as the foundation for proposing a new federated clustering method, named cluster-contrastive federated clustering (CCFC). Benefiting from representation learning, the clustering performance of CCFC even double those of the best baseline methods in some cases. Compared to the most related baseline, the benefit results in substantial NMI score improvements of up to 0.4155 on the most conspicuous case. Moreover, CCFC also shows superior performance in handling device failures from a practical viewpoint.
Federated deep clustering with GAN-based data synthesis
Nov 30, 2022Clustering has been extensively studied in centralized settings, but relatively unexplored in federated ones that data are distributed among multiple clients and can only be kept local at the clients. The necessity to invest more resources in improving federated clustering methods is twofold: 1) The performance of supervised federated learning models can benefit from clustering. 2) It is non-trivial to extend centralized ones to perform federated clustering tasks. In centralized settings, various deep clustering methods that perform dimensionality reduction and clustering jointly have achieved great success. To obtain high-quality cluster information, it is natural but non-trivial to extend these methods to federated settings. For this purpose, we propose a simple but effective federated deep clustering method. It requires only one communication round between the central server and clients, can run asynchronously, and can handle device failures. Moreover, although most studies have highlighted adverse effects of the non-independent and identically distributed (non-IID) data across clients, experimental results indicate that the proposed method can significantly benefit from this scenario.
Federated clustering with GAN-based data synthesis
Oct 29, 2022



Federated clustering is an adaptation of centralized clustering in the federated settings, which aims to cluster data based on a global similarity measure while keeping all data local. The key here is how to construct a global similarity measure without sharing private data. To handle this, k-FED and federated fuzzy c-means (FFCM) respectively adapted K-means and fuzzy c-means to the federated learning settings, which aim to construct $K$ global cluster centroids by running K-means on a set of all local cluster centroids. However, the constructed global cluster centroids may be fragile and be sensitive to different non-independent and identically distributed (Non-IID) levels among clients. To handle this, we propose a simple but effective federated clustering framework with GAN-based data synthesis, which is called synthetic data aided federated clustering (SDA-FC). It outperforms k-FED and FFCM in terms of effectiveness and robustness, requires only one communication round, can run asynchronously, and can handle device failures. Moreover, although NMI is a far more commonly used metric than Kappa, empirical results indicate that Kappa is a more reliable one.
Selective clustering ensemble based on kappa and F-score
Apr 23, 2022
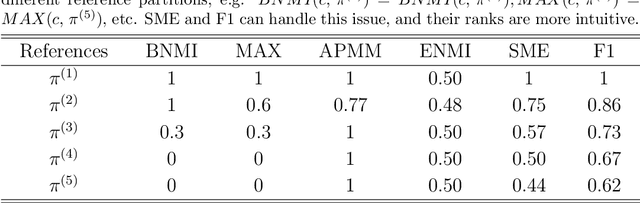
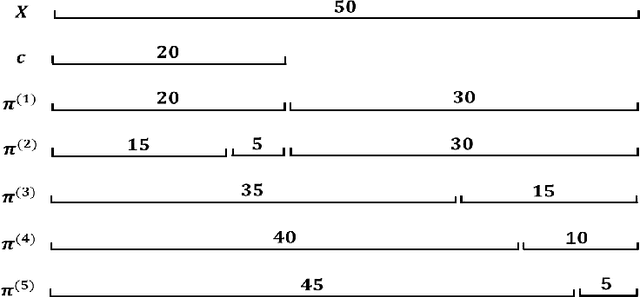
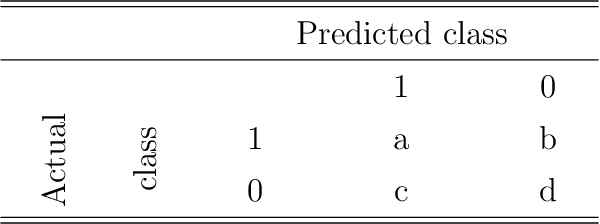
Clustering ensemble has an impressive performance in improving the accuracy and robustness of partition results and has received much attention in recent years. Selective clustering ensemble (SCE) can further improve the ensemble performance by selecting base partitions or clusters in according to diversity and stability. However, there is a conflict between diversity and stability, and how to make the trade-off between the two is challenging. The key here is how to evaluate the quality of the base partitions and clusters. In this paper, we propose a new evaluation method for partitions and clusters using kappa and F-score, leading to a new SCE method, which uses kappa to select informative base partitions and uses F-score to weight clusters based on stability. The effectiveness and efficiency of the proposed method is empirically validated over real datasets.