 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Object Detection in Complex Backgrounds with Multi-Scale Attention and Global Relation Modeling
Mar 04, 2026Small object detection under complex backgrounds remains a challenging task due to severe feature degradation, weak semantic representation, and inaccurate localization caused by downsampling operations and background interference. Existing detection frameworks are mainly designed for general objects and often fail to explicitly address the unique characteristics of small objects, such as limited structural cues and strong sensitivity to localization errors. In this paper, we propose a multi-level feature enhancement and global relation modeling framework tailored for small object detection. Specifically, a Residual Haar Wavelet Downsampling module is introduced to preserve fine-grained structural details by jointly exploiting spatial-domain convolutional features and frequency-domain representations. To enhance global semantic awareness and suppress background noise, a Global Relation Modeling module is employed to capture long-range dependencies at high-level feature stages. Furthermore, a Cross-Scale Hybrid Attention module is designed to establish sparse and aligned interactions across multi-scale features, enabling effective fusion of high-resolution details and high-level semantic information with reduced computational overhead. Finally, a Center-Assisted Loss is incorporated to stabilize training and improve localization accuracy for small objects. Extensive experiments conducted on the large-scale RGBT-Tiny benchmark demonstrate that the proposed method consistently outperforms existing state-of-the-art detectors under both IoU-based and scale-adaptive evaluation metrics. These results validate the effectiveness and robustness of the proposed framework for small object detection in complex environments.
Driver Assistant: Persuading Drivers to Adjust Secondary Tasks Using Large Language Models
Aug 07, 2025Level 3 automated driving systems allows drivers to engage in secondary tasks while diminishing their perception of risk. In the event of an emergency necessitating driver intervention, the system will alert the driver with a limited window for reaction and imposing a substantial cognitive burden. To address this challenge, this study employs a Large Language Model (LLM) to assist drivers in maintaining an appropriate attention on road conditions through a "humanized" persuasive advice. Our tool leverages the road conditions encountered by Level 3 systems as triggers, proactively steering driver behavior via both visual and auditory routes. Empirical study indicates that our tool is effective in sustaining driver attention with reduced cognitive load and coordinating secondary tasks with takeover behavior. Our work provides insights into the potential of using LLMs to support drivers during multi-task automated driving.
StepFun-Prover Preview: Let's Think and Verify Step by Step
Jul 27, 2025We present StepFun-Prover Preview, a large language model designed for formal theorem proving through tool-integrated reasoning. Using a reinforcement learning pipeline that incorporates tool-based interactions, StepFun-Prover can achieve strong performance in generating Lean 4 proofs with minimal sampling. Our approach enables the model to emulate human-like problem-solving strategies by iteratively refining proofs based on real-time environment feedback. On the miniF2F-test benchmark, StepFun-Prover achieves a pass@1 success rate of $70.0\%$. Beyond advancing benchmark performance, we introduce an end-to-end training framework for developing tool-integrated reasoning models, offering a promising direction for automated theorem proving and Math AI assistant.
OmniFC: Rethinking Federated Clustering via Lossless and Secure Distance Reconstruction
May 19, 2025Federated clustering (FC) aims to discover global cluster structures across decentralized clients without sharing raw data, making privacy preservation a fundamental requirement. There are two critical challenges: (1) privacy leakage during collaboration, and (2) robustness degradation due to aggregation of proxy information from non-independent and identically distributed (Non-IID) local data, leading to inaccurate or inconsistent global clustering. Existing solutions typically rely on model-specific local proxies, which are sensitive to data heterogeneity and inherit inductive biases from their centralized counterparts, thus limiting robustness and generality. We propose Omni Federated Clustering (OmniFC), a unified and model-agnostic framework. Leveraging Lagrange coded computing, our method enables clients to share only encoded data, allowing exact reconstruction of the global distance matrix--a fundamental representation of sample relationships--without leaking private information, even under client collusion. This construction is naturally resilient to Non-IID data distributions. This approach decouples FC from model-specific proxies, providing a unified extension mechanism applicable to diverse centralized clustering methods. Theoretical analysis confirms both reconstruction fidelity and privacy guarantees, while comprehensive experiments demonstrate OmniFC's superior robustness, effectiveness, and generality across various benchmarks compared to state-of-the-art methods. Code will be released.
CCFC++: Enhancing Federated Clustering through Feature Decorrelation
Feb 20, 2024In federated clustering, multiple data-holding clients collaboratively group data without exchanging raw data. This field has seen notable advancements through its marriage with contrastive learning, exemplified by Cluster-Contrastive Federated Clustering (CCFC). However, CCFC suffers from heterogeneous data across clients, leading to poor and unrobust performance. Our study conducts both empirical and theoretical analyses to understand the impact of heterogeneous data on CCFC. Findings indicate that increased data heterogeneity exacerbates dimensional collapse in CCFC, evidenced by increased correlations across multiple dimensions of the learned representations. To address this, we introduce a decorrelation regularizer to CCFC. Benefiting from the regularizer, the improved method effectively mitigates the detrimental effects of data heterogeneity, and achieves superior performance, as evidenced by a marked increase in NMI scores, with the gain reaching as high as 0.32 in the most pronounced case.
CCFC: Bridging Federated Clustering and Contrastive Learning
Jan 12, 2024
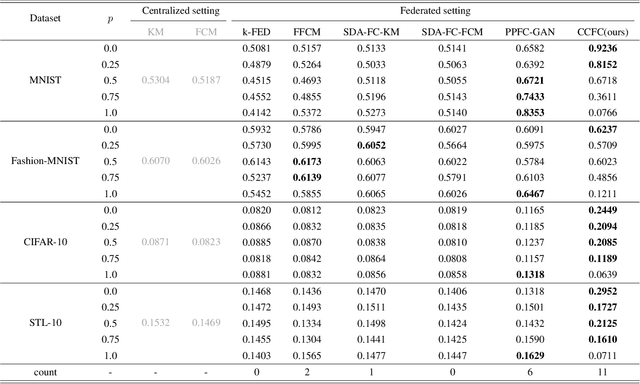
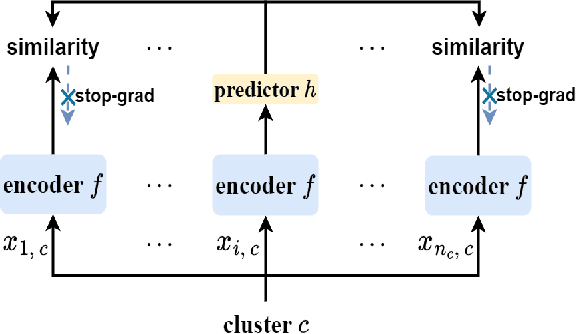
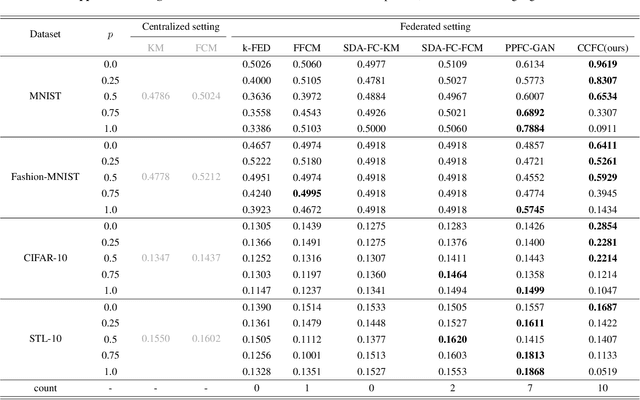
Federated clustering, an essential extension of centralized clustering for federated scenarios, enables multiple data-holding clients to collaboratively group data while keeping their data locally. In centralized scenarios, clustering driven by representation learning has made significant advancements in handling high-dimensional complex data. However, the combination of federated clustering and representation learning remains underexplored. To bridge this, we first tailor a cluster-contrastive model for learning clustering-friendly representations. Then, we harness this model as the foundation for proposing a new federated clustering method, named cluster-contrastive federated clustering (CCFC). Benefiting from representation learning, the clustering performance of CCFC even double those of the best baseline methods in some cases. Compared to the most related baseline, the benefit results in substantial NMI score improvements of up to 0.4155 on the most conspicuous case. Moreover, CCFC also shows superior performance in handling device failures from a practical viewpoint.
ClusterDDPM: An EM clustering framework with Denoising Diffusion Probabilistic Models
Dec 13, 2023Variational autoencoder (VAE) and generative adversarial networks (GAN) have found widespread applications in clustering and have achieved significant success. However, the potential of these approaches may be limited due to VAE's mediocre generation capability or GAN's well-known instability during adversarial training. In contrast, denoising diffusion probabilistic models (DDPMs) represent a new and promising class of generative models that may unlock fresh dimensions in clustering. In this study, we introduce an innovative expectation-maximization (EM) framework for clustering using DDPMs. In the E-step, we aim to derive a mixture of Gaussian priors for the subsequent M-step. In the M-step, our focus lies in learning clustering-friendly latent representations for the data by employing the conditional DDPM and matching the distribution of latent representations to the mixture of Gaussian priors. We present a rigorous theoretical analysis of the optimization process in the M-step, proving that the optimizations are equivalent to maximizing the lower bound of the Q function within the vanilla EM framework under certain constraints. Comprehensive experiments validate the advantages of the proposed framework, showcasing superior performance in clustering, unsupervised conditional generation and latent representation learning.
Introspective Tips: Large Language Model for In-Context Decision Making
May 19, 2023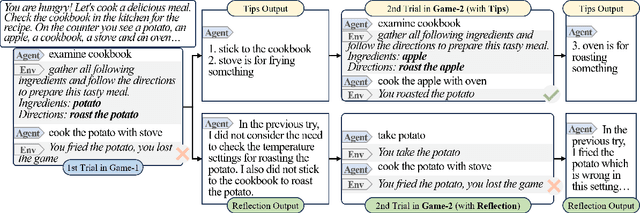

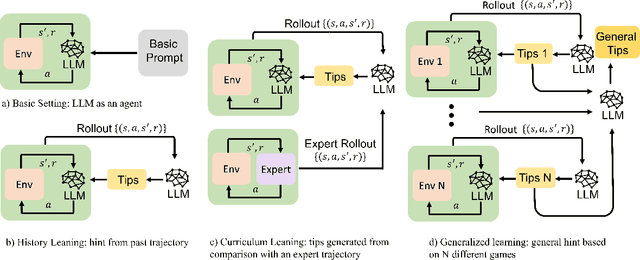

The emergence of large language models (LLMs) has substantially influenced natural language processing, demonstrating exceptional results across various tasks. In this study, we employ ``Introspective Tips" to facilitate LLMs in self-optimizing their decision-making. By introspectively examining trajectories, LLM refines its policy by generating succinct and valuable tips. Our method enhances the agent's performance in both few-shot and zero-shot learning situations by considering three essential scenarios: learning from the agent's past experiences, integrating expert demonstrations, and generalizing across diverse games. Importantly, we accomplish these improvements without fine-tuning the LLM parameters; rather, we adjust the prompt to generalize insights from the three aforementioned situations. Our framework not only supports but also emphasizes the advantage of employing LLM in in-contxt decision-making. Experiments involving over 100 games in TextWorld illustrate the superior performance of our approach.
NoiseTrans: Point Cloud Denoising with Transformers
Apr 24, 2023



Point clouds obtained from capture devices or 3D reconstruction techniques are often noisy and interfere with downstream tasks. The paper aims to recover the underlying surface of noisy point clouds. We design a novel model, NoiseTrans, which uses transformer encoder architecture for point cloud denoising. Specifically, we obtain structural similarity of point-based point clouds with the assistance of the transformer's core self-attention mechanism. By expressing the noisy point cloud as a set of unordered vectors, we convert point clouds into point embeddings and employ Transformer to generate clean point clouds. To make the Transformer preserve details when sensing the point cloud, we design the Local Point Attention to prevent the point cloud from being over-smooth. In addition, we also propose sparse encoding, which enables the Transformer to better perceive the structural relationships of the point cloud and improve the denoising performance. Experiments show that our model outperforms state-of-the-art methods in various datasets and noise environments.
Conservative State Value Estimation for Offline Reinforcement Learning
Feb 14, 2023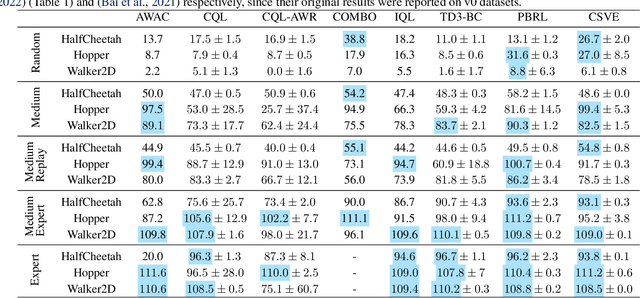
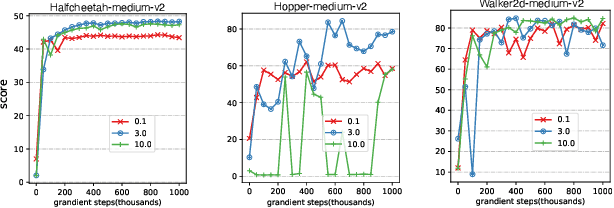
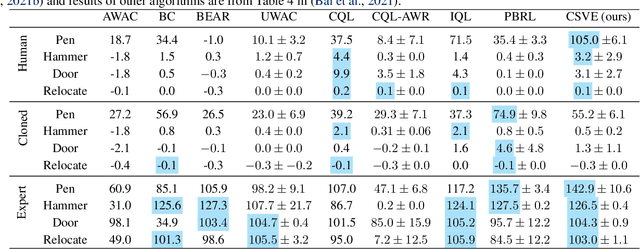
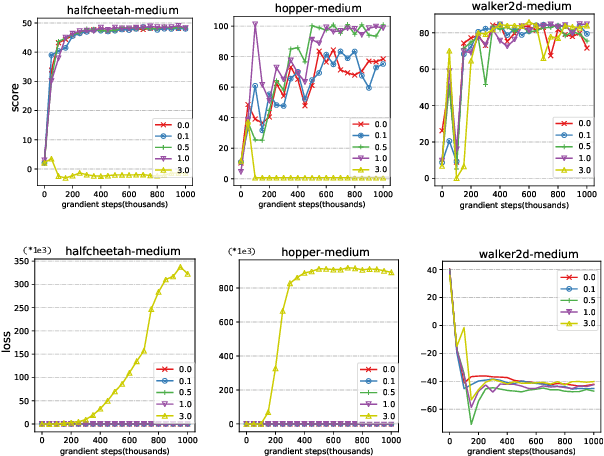
Offline reinforcement learning faces a significant challenge of value over-estimation due to the distributional drift between the dataset and the current learned policy, leading to learning failure in practice. The common approach is to incorporate a penalty term to reward or value estimation in the Bellman iterations. Meanwhile, to avoid extrapolation on out-of-distribution (OOD) states and actions, existing methods focus on conservative Q-function estimation. In this paper, we propose Conservative State Value Estimation (CSVE), a new approach that learns conservative V-function via directly imposing penalty on OOD states. Compared to prior work, CSVE allows more effective in-data policy optimization with conservative value guarantees. Further, we apply CSVE and develop a practical actor-critic algorithm in which the critic does the conservative value estimation by additionally sampling and penalizing the states \emph{around} the dataset, and the actor applies advantage weighted updates extended with state exploration to improve the policy. We evaluate in classic continual control tasks of D4RL, showing that our method performs better than the conservative Q-function learning methods and is strongly competitive among recent SOTA methods.