 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrospective Tips: Large Language Model for In-Context Decision Making
Paper and Code
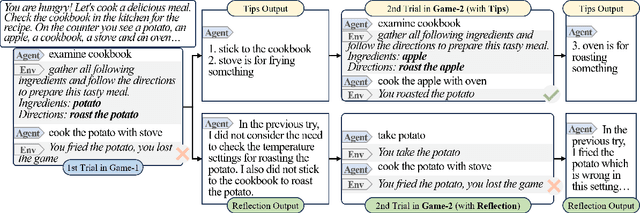

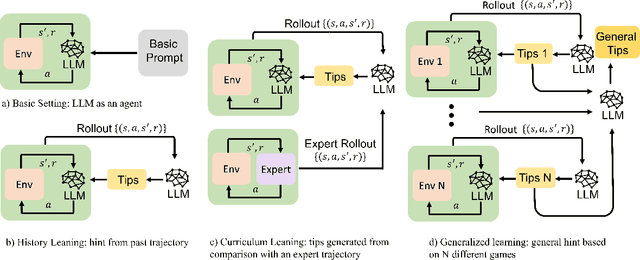

The emergence of large language models (LLMs) has substantially influenced natural language processing, demonstrating exceptional results across various tasks. In this study, we employ ``Introspective Tips" to facilitate LLMs in self-optimizing their decision-making. By introspectively examining trajectories, LLM refines its policy by generating succinct and valuable tips. Our method enhances the agent's performance in both few-shot and zero-shot learning situations by considering three essential scenarios: learning from the agent's past experiences, integrating expert demonstrations, and generalizing across diverse games. Importantly, we accomplish these improvements without fine-tuning the LLM parameters; rather, we adjust the prompt to generalize insights from the three aforementioned situations. Our framework not only supports but also emphasizes the advantage of employing LLM in in-contxt decision-making. Experiments involving over 100 games in TextWorld illustrate the superior performance of our approach.