 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Fusion for End-to-End RGB-T Tracking
Paper and Code
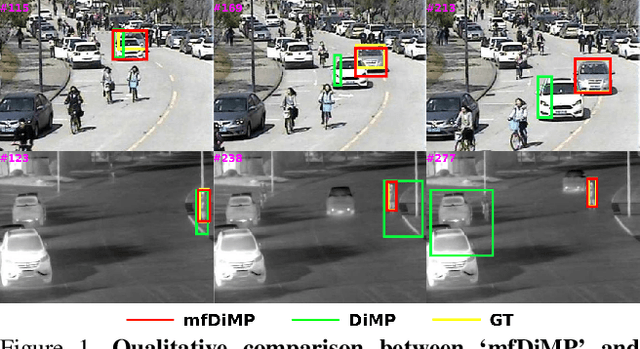
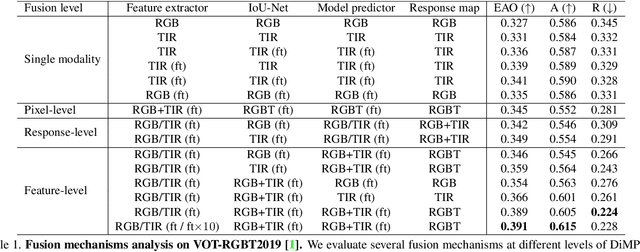
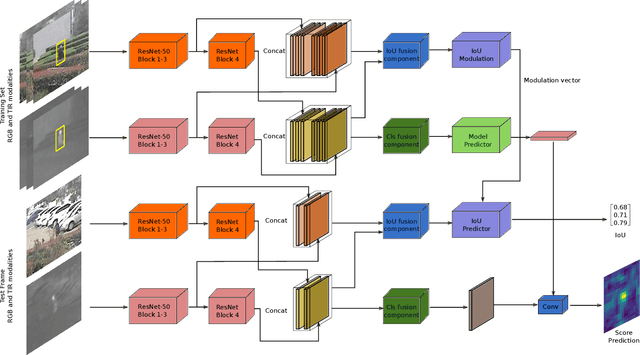
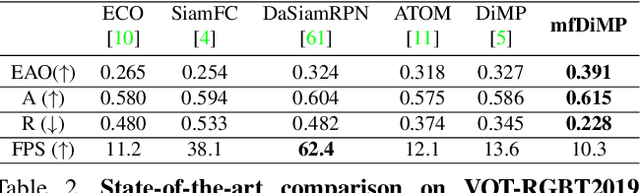
We propose an end-to-end tracking framework for fusing the RGB and TIR modalities in RGB-T tracking. Our baseline tracker is DiMP (Discriminative Model Prediction), which employs a carefully designed target prediction network trained end-to-end using a discriminative loss. We analyze the effectiveness of modality fusion in each of the main components in DiMP, i.e. feature extractor, target estimation network, and classifier. We consider several fusion mechanisms acting at different levels of the framework, including pixel-level, feature-level and response-level. Our tracker is trained in an end-to-end manner, enabling the components to learn how to fuse the information from both modalities. As data to train our model, we generate a large-scale RGB-T dataset by considering an annotated RGB tracking dataset (GOT-10k) and synthesizing paired TIR images using an image-to-image translation approach. We perform extensive experiments on VOT-RGBT2019 dataset and RGBT210 dataset, evaluating each type of modality fusing on each model component. The results show that the proposed fusion mechanisms improve the performance of the single modality counterparts. We obtain our best results when fusing at the feature-level on both the IoU-Net and the model predictor, obtaining an EAO score of 0.391 on VOT-RGBT2019 dataset. With this fusion mechanism we achieve the state-of-the-art performance on RGBT210 dataset.