 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositive Pair Distillation Considered Harmful: Continual Meta Metric Learning for Lifelong Object Re-Identification
Oct 04, 2022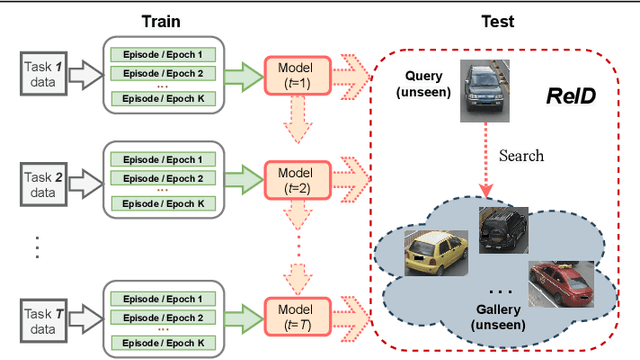
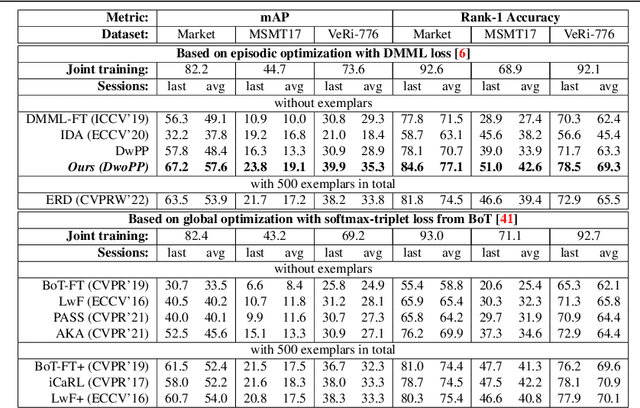
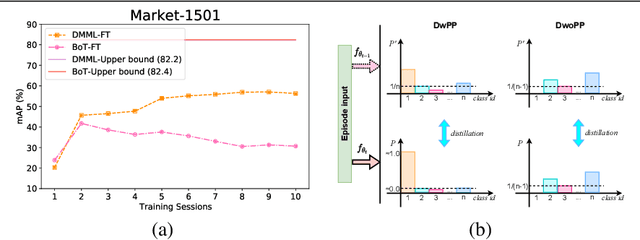

Lifelong object re-identification incrementally learns from a stream of re-identification tasks. The objective is to learn a representation that can be applied to all tasks and that generalizes to previously unseen re-identification tasks. The main challenge is that at inference time the representation must generalize to previously unseen identities. To address this problem, we apply continual meta metric learning to lifelong object re-identification. To prevent forgetting of previous tasks, we use knowledge distillation and explore the roles of positive and negative pairs. Based on our observation that the distillation and metric losses are antagonistic, we propose to remove positive pairs from distillation to robustify model updates. Our method, called Distillation without Positive Pairs (DwoPP), is evaluated on extensive intra-domain experiments on person and vehicle re-identification datasets, as well as inter-domain experiments on the LReID benchmark. Our experiments demonstrate that DwoPP significantly outperforms the state-of-the-art. The code is here: https://github.com/wangkai930418/DwoPP_code
Incremental Meta-Learning via Episodic Replay Distillation for Few-Shot Image Recognition
Nov 11, 2021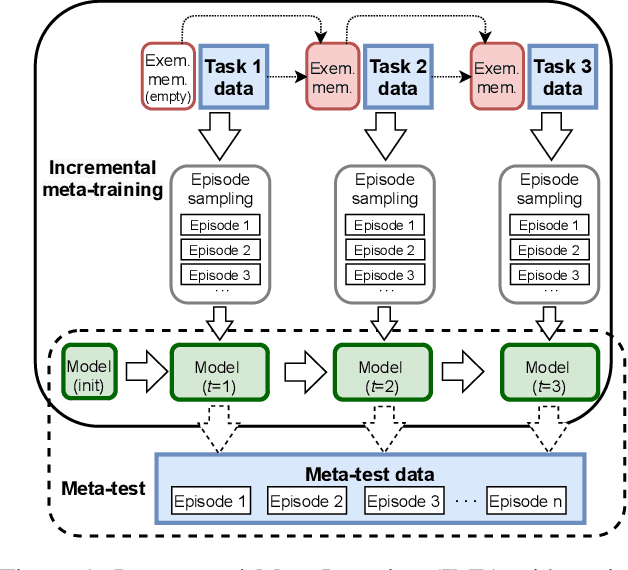
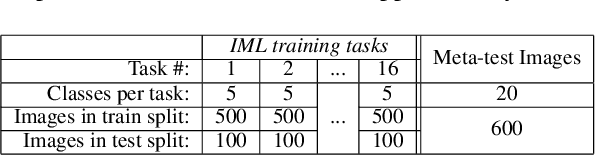
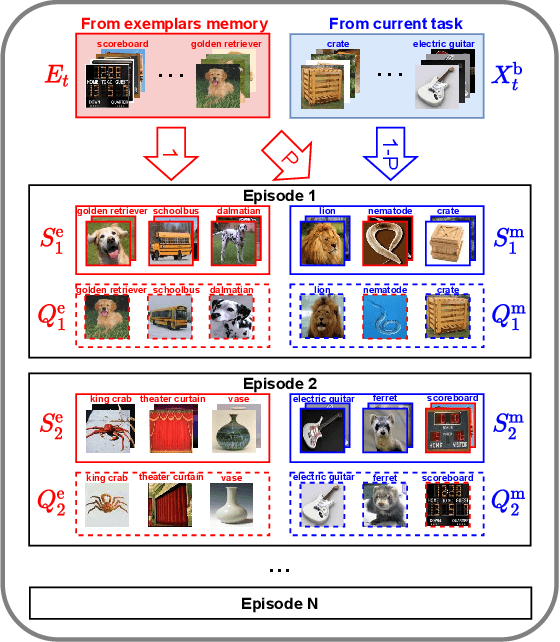
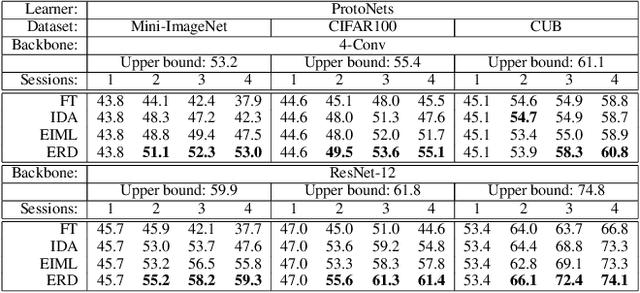
Most meta-learning approaches assume the existence of a very large set of labeled data available for episodic meta-learning of base knowledge. This contrasts with the more realistic continual learning paradigm in which data arrives incrementally in the form of tasks containing disjoint classes. In this paper we consider this problem of Incremental Meta-Learning (IML) in which classes are presented incrementally in discrete tasks. We propose an approach to IML, which we call Episodic Replay Distillation (ERD), that mixes classes from the current task with class exemplars from previous tasks when sampling episodes for meta-learning. These episodes are then used for knowledge distillation to minimize catastrophic forgetting. Experiments on four datasets demonstrate that ERD surpasses the state-of-the-art. In particular, on the more challenging one-shot, long task sequence incremental meta-learning scenarios, we reduce the gap between IML and the joint-training upper bound from 3.5% / 10.1% / 13.4% with the current state-of-the-art to 2.6% / 2.9% / 5.0% with our method on Tiered-ImageNet / Mini-ImageNet / CIFAR100, respectively.