 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining YOLO: Leveraging Grad-CAM to Explain Object Detections
Nov 22, 2022


We investigate the problem of explainability for visual object detectors. Specifically, we demonstrate on the example of the YOLO object detector how to integrate Grad-CAM into the model architecture and analyze the results. We show how to compute attribution-based explanations for individual detections and find that the normalization of the results has a great impact on their interpretation.
Multimodal Detection of Information Disorder from Social Media
May 31, 2021
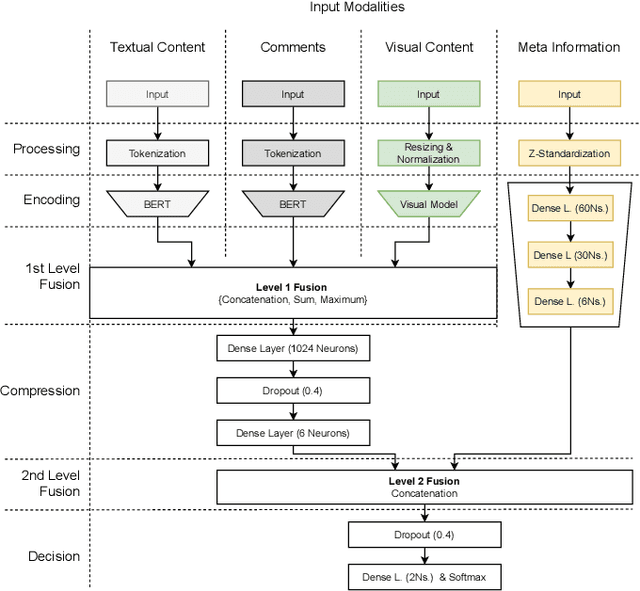
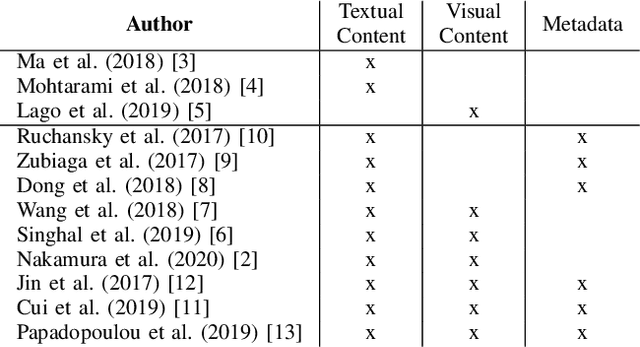
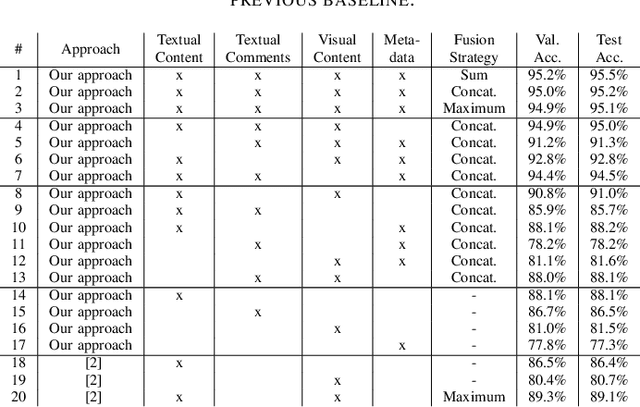
Social media is accompanied by an increasing proportion of content that provides fake information or misleading content, known as information disorder. In this paper, we study the problem of multimodal fake news detection on a largescale multimodal dataset. We propose a multimodal network architecture that enables different levels and types of information fusion. In addition to the textual and visual content of a posting, we further leverage secondary information, i.e. user comments and metadata. We fuse information at multiple levels to account for the specific intrinsic structure of the modalities. Our results show that multimodal analysis is highly effective for the task and all modalities contribute positively when fused properly.