 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMURAUER: Mapping Unlabeled Real Data for Label AUstERity
Paper and Code
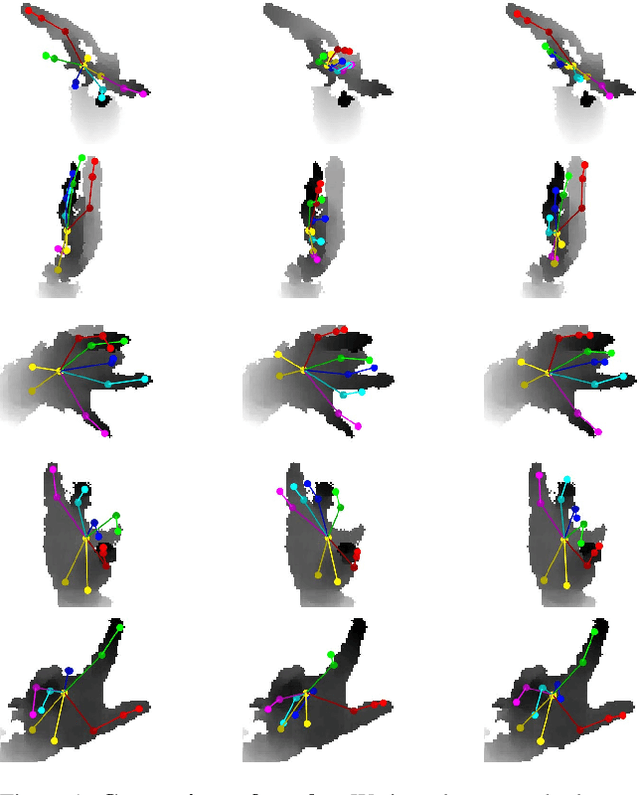
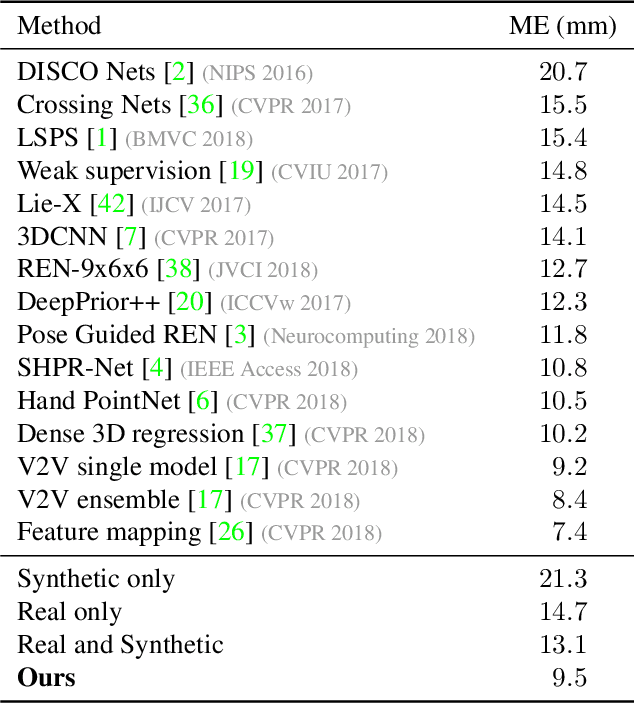
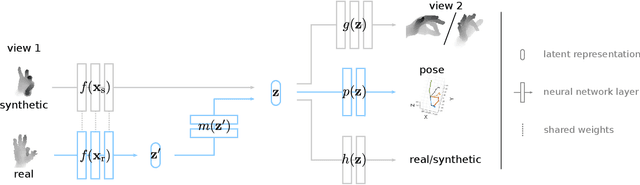
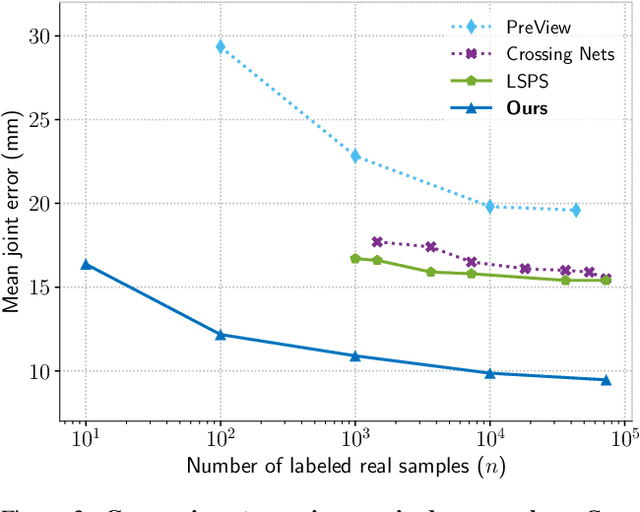
Data labeling for learning 3D hand pose estimation models is a huge effort. Readily available, accurately labeled synthetic data has the potential to reduce the effort. However, to successfully exploit synthetic data, current state-of-the-art methods still require a large amount of labeled real data. In this work, we remove this requirement by learning to map from the features of real data to the features of synthetic data mainly using a large amount of synthetic and unlabeled real data. We exploit unlabeled data using two auxiliary objectives, which enforce that (i) the mapped representation is pose specific and (ii) at the same time, the distributions of real and synthetic data are aligned. While pose specifity is enforced by a self-supervisory signal requiring that the representation is predictive for the appearance from different views, distributions are aligned by an adversarial term. In this way, we can significantly improve the results of the baseline system, which does not use unlabeled data and outperform many recent approaches already with about 1% of the labeled real data. This presents a step towards faster deployment of learning based hand pose estimation, making it accessible for a larger range of applications.