 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Training of Hybrid CNN-CRF Models for Stereo
May 03, 2017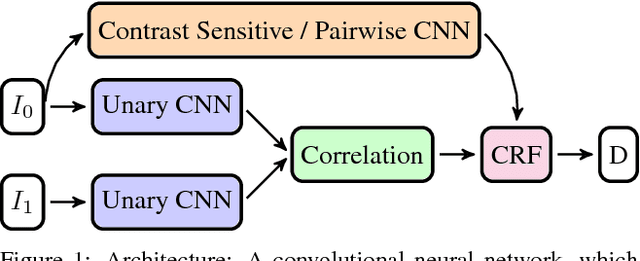
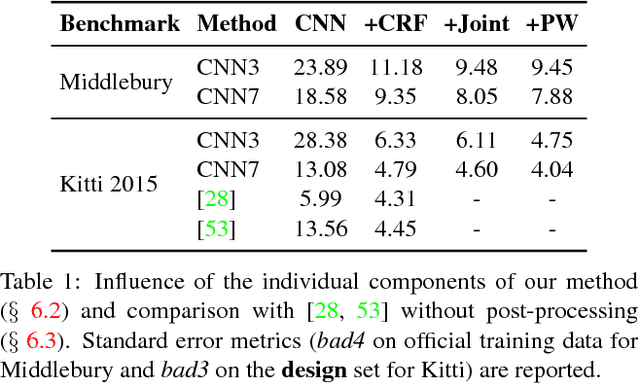

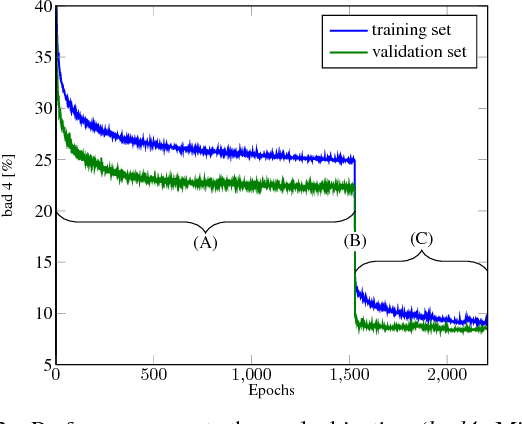
We propose a novel and principled hybrid CNN+CRF model for stereo estimation. Our model allows to exploit the advantages of both, convolutional neural networks (CNNs) and conditional random fields (CRFs) in an unified approach. The CNNs compute expressive features for matching and distinctive color edges, which in turn are used to compute the unary and binary costs of the CRF. For inference, we apply a recently proposed highly parallel dual block descent algorithm which only needs a small fixed number of iterations to compute a high-quality approximate minimizer. As the main contribution of the paper, we propose a theoretically sound method based on the structured output support vector machine (SSVM) to train the hybrid CNN+CRF model on large-scale data end-to-end. Our trained models perform very well despite the fact that we are using shallow CNNs and do not apply any kind of post-processing to the final output of the CRF. We evaluate our combined models on challenging stereo benchmarks such as Middlebury 2014 and Kitti 2015 and also investigate the performance of each individual component.
Real-Time Panoramic Tracking for Event Cameras
Mar 21, 2017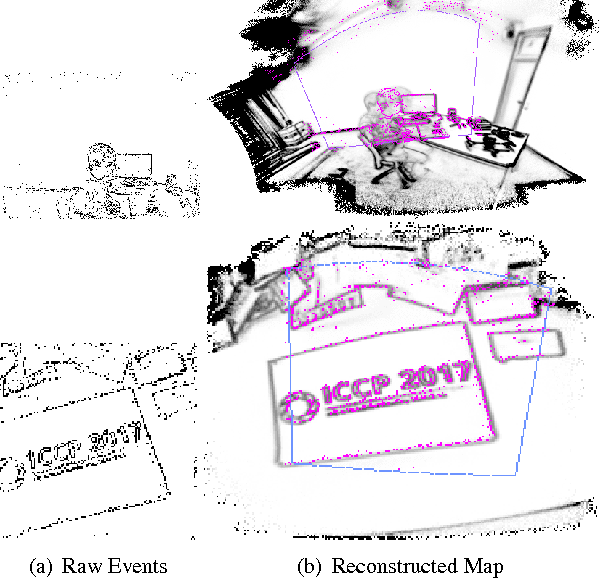

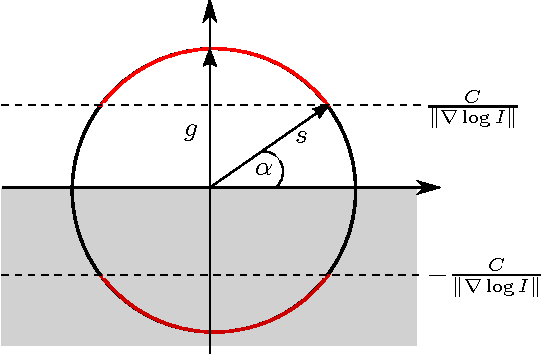
Event cameras are a paradigm shift in camera technology. Instead of full frames, the sensor captures a sparse set of events caused by intensity changes. Since only the changes are transferred, those cameras are able to capture quick movements of objects in the scene or of the camera itself. In this work we propose a novel method to perform camera tracking of event cameras in a panoramic setting with three degrees of freedom. We propose a direct camera tracking formulation, similar to state-of-the-art in visual odometry. We show that the minimal information needed for simultaneous tracking and mapping is the spatial position of events, without using the appearance of the imaged scene point. We verify the robustness to fast camera movements and dynamic objects in the scene on a recently proposed dataset and self-recorded sequences.
PetroSurf3D - A Dataset for high-resolution 3D Surface Segmentation
Mar 01, 2017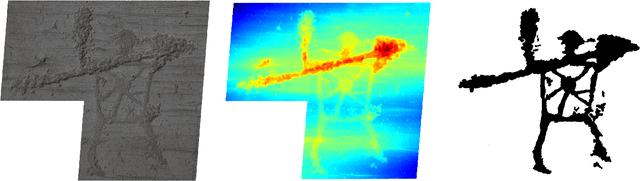
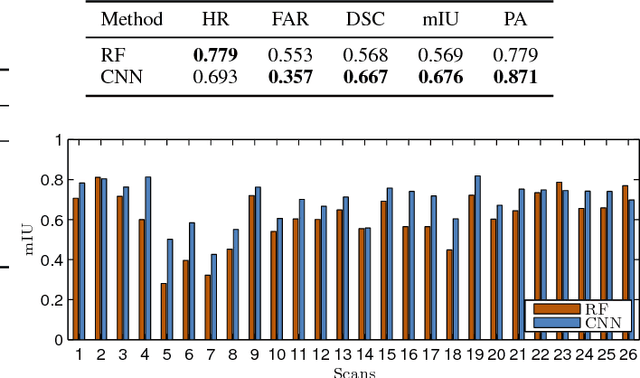

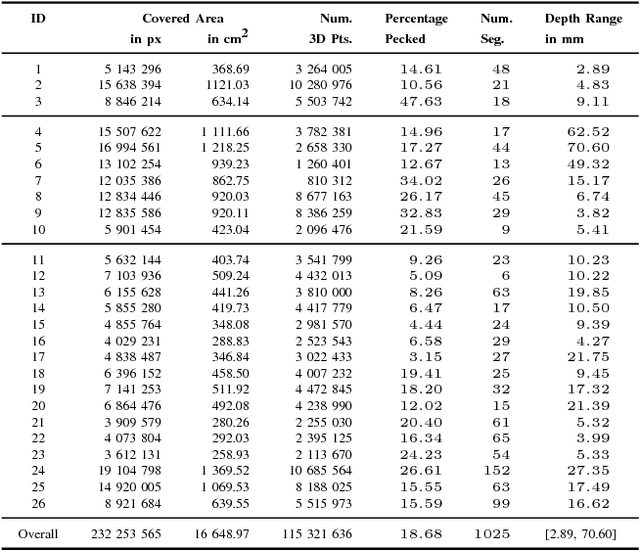
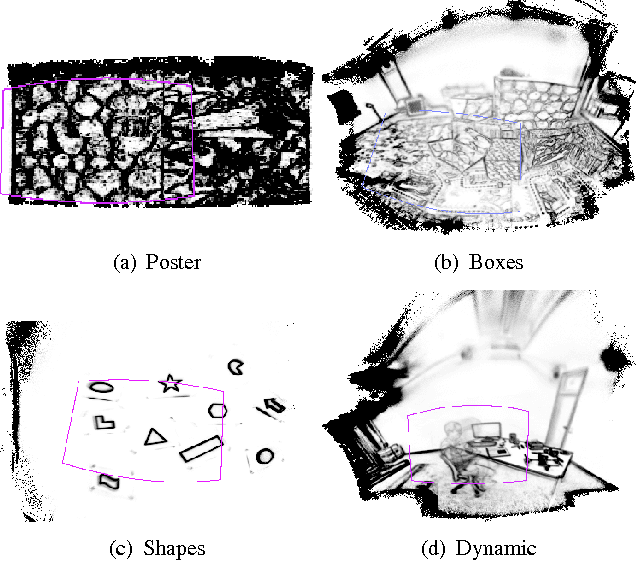
The development of powerful 3D scanning hardware and reconstruction algorithms has strongly promoted the generation of 3D surface reconstructions in different domains. An area of special interest for such 3D reconstructions is the cultural heritage domain, where surface reconstructions are generated to digitally preserve historical artifacts. While reconstruction quality nowadays is sufficient in many cases, the robust analysis (e.g. segmentation, matching, and classification) of reconstructed 3D data is still an open topic. In this paper, we target the automatic and interactive segmentation of high-resolution 3D surface reconstructions from the archaeological domain. To foster research in this field, we introduce a fully annotated and publicly available large-scale 3D surface dataset including high-resolution meshes, depth maps and point clouds as a novel benchmark dataset to the community. We provide baseline results for our existing random forest-based approach and for the first time investigate segmentation with convolutional neural networks (CNNs) on the data. Results show that both approaches have complementary strengths and weaknesses and that the provided dataset represents a challenge for future research.
Real-Time Intensity-Image Reconstruction for Event Cameras Using Manifold Regularisation
Aug 04, 2016



Event cameras or neuromorphic cameras mimic the human perception system as they measure the per-pixel intensity change rather than the actual intensity level. In contrast to traditional cameras, such cameras capture new information about the scene at MHz frequency in the form of sparse events. The high temporal resolution comes at the cost of losing the familiar per-pixel intensity information. In this work we propose a variational model that accurately models the behaviour of event cameras, enabling reconstruction of intensity images with arbitrary frame rate in real-time. Our method is formulated on a per-event-basis, where we explicitly incorporate information about the asynchronous nature of events via an event manifold induced by the relative timestamps of events. In our experiments we verify that solving the variational model on the manifold produces high-quality images without explicitly estimating optical flow.
Solving Dense Image Matching in Real-Time using Discrete-Continuous Optimization
Jan 23, 2016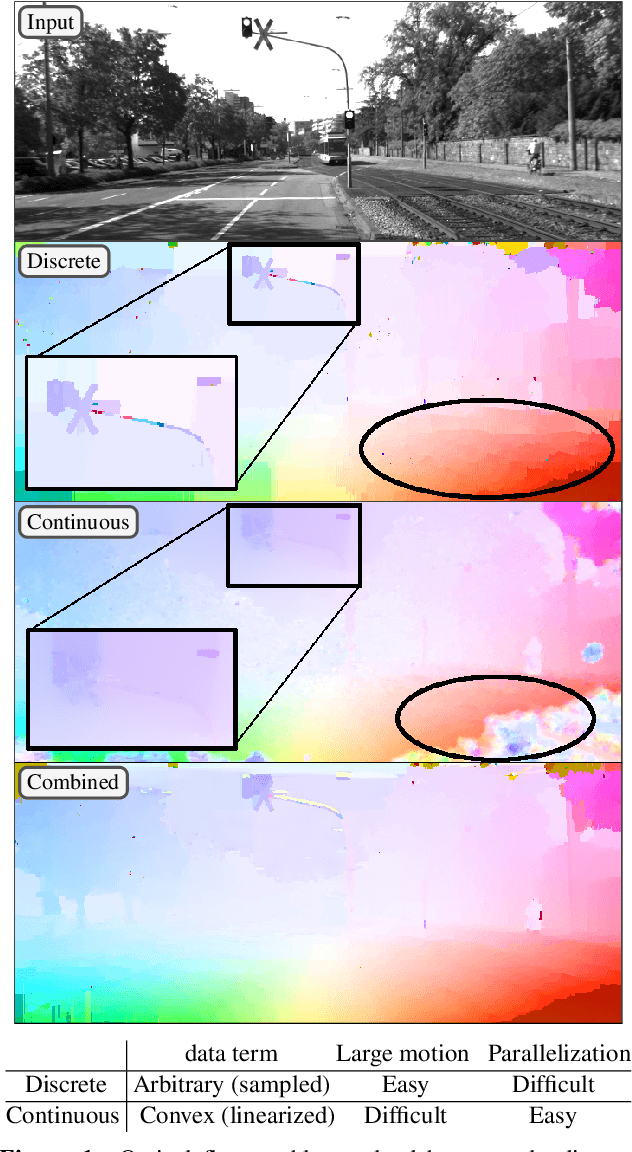


Dense image matching is a fundamental low-level problem in Computer Vision, which has received tremendous attention from both discrete and continuous optimization communities. The goal of this paper is to combine the advantages of discrete and continuous optimization in a coherent framework. We devise a model based on energy minimization, to be optimized by both discrete and continuous algorithms in a consistent way. In the discrete setting, we propose a novel optimization algorithm that can be massively parallelized. In the continuous setting we tackle the problem of non-convex regularizers by a formulation based on differences of convex functions. The resulting hybrid discrete-continuous algorithm can be efficiently accelerated by modern GPUs and we demonstrate its real-time performance for the applications of dense stereo matching and optical flow.