 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoSeg: Unsupervised Semantic Image Segmentation with Mutual Information Maximization
Oct 07, 2021
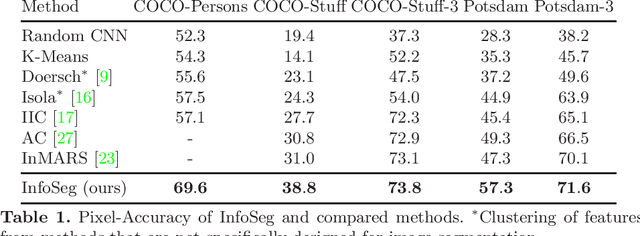
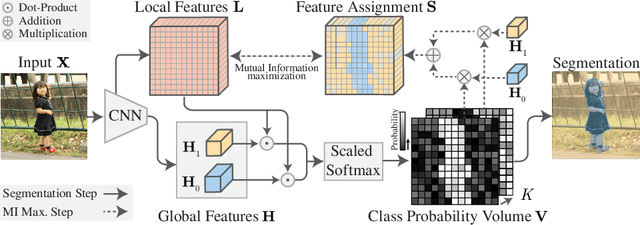

We propose a novel method for unsupervised semantic image segmentation based on mutual information maximization between local and global high-level image features. The core idea of our work is to leverage recent progress in self-supervised image representation learning. Representation learning methods compute a single high-level feature capturing an entire image. In contrast, we compute multiple high-level features, each capturing image segments of one particular semantic class. To this end, we propose a novel two-step learning procedure comprising a segmentation and a mutual information maximization step. In the first step, we segment images based on local and global features. In the second step, we maximize the mutual information between local features and high-level features of their respective class. For training, we provide solely unlabeled images and start from random network initialization. For quantitative and qualitative evaluation, we use established benchmarks, and COCO-Persons, whereby we introduce the latter in this paper as a challenging novel benchmark. InfoSeg significantly outperforms the current state-of-the-art, e.g., we achieve a relative increase of 26% in the Pixel Accuracy metric on the COCO-Stuff dataset.
BP-MVSNet: Belief-Propagation-Layers for Multi-View-Stereo
Oct 23, 2020
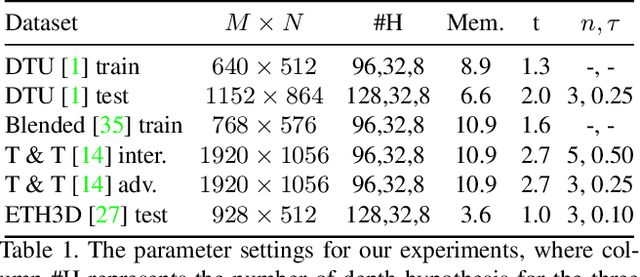
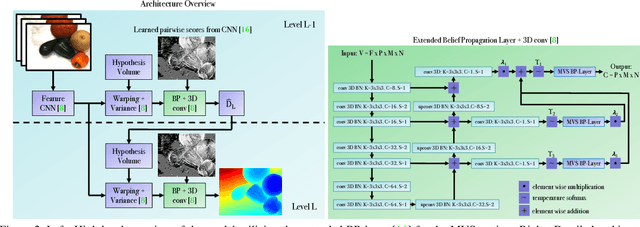
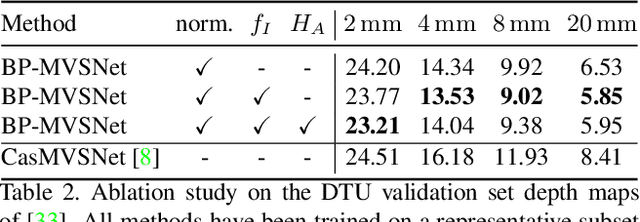
In this work, we propose BP-MVSNet, a convolutional neural network (CNN)-based Multi-View-Stereo (MVS) method that uses a differentiable Conditional Random Field (CRF) layer for regularization. To this end, we propose to extend the BP layer and add what is necessary to successfully use it in the MVS setting. We therefore show how we can calculate a normalization based on the expected 3D error, which we can then use to normalize the label jumps in the CRF. This is required to make the BP layer invariant to different scales in the MVS setting. In order to also enable fractional label jumps, we propose a differentiable interpolation step, which we embed into the computation of the pairwise term. These extensions allow us to integrate the BP layer into a multi-scale MVS network, where we continuously improve a rough initial estimate until we get high quality depth maps as a result. We evaluate the proposed BP-MVSNet in an ablation study and conduct extensive experiments on the DTU, Tanks and Temples and ETH3D data sets. The experiments show that we can significantly outperform the baseline and achieve state-of-the-art results.
Frame-To-Frame Consistent Semantic Segmentation
Aug 27, 2020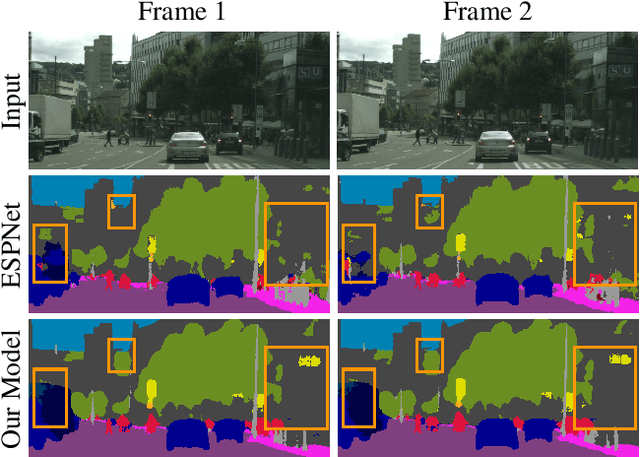
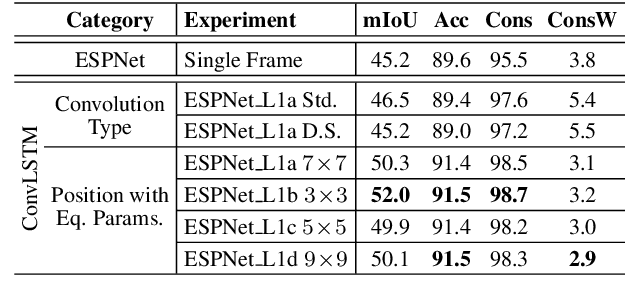
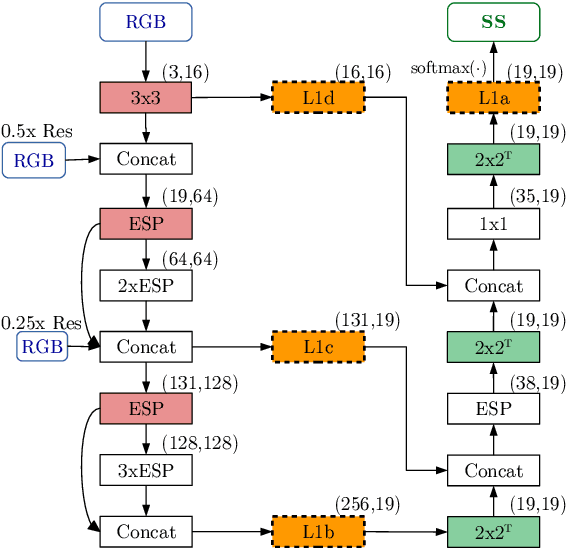

In this work, we aim for temporally consistent semantic segmentation throughout frames in a video. Many semantic segmentation algorithms process images individually which leads to an inconsistent scene interpretation due to illumination changes, occlusions and other variations over time. To achieve a temporally consistent prediction, we train a convolutional neural network (CNN) which propagates features through consecutive frames in a video using a convolutional long short term memory (ConvLSTM) cell. Besides the temporal feature propagation, we penalize inconsistencies in our loss function. We show in our experiments that the performance improves when utilizing video information compared to single frame prediction. The mean intersection over union (mIoU) metric on the Cityscapes validation set increases from 45.2 % for the single frames to 57.9 % for video data after implementing the ConvLSTM to propagate features trough time on the ESPNet. Most importantly, inconsistency decreases from 4.5 % to 1.3 % which is a reduction by 71.1 %. Our results indicate that the added temporal information produces a frame-to-frame consistent and more accurate image understanding compared to single frame processing. Code and videos are available at https://github.com/mrebol/f2f-consistent-semantic-segmentation
Belief Propagation Reloaded: Learning BP-Layers for Labeling Problems
Mar 13, 2020

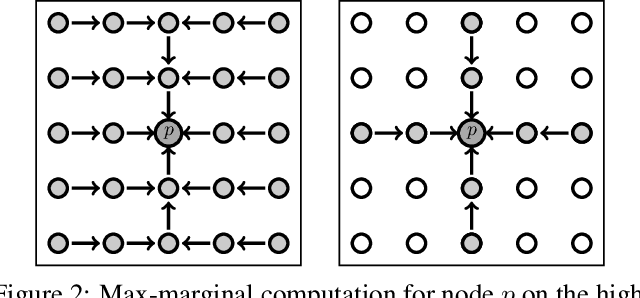
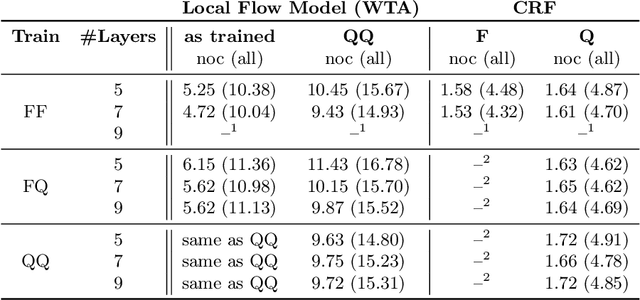
It has been proposed by many researchers that combining deep neural networks with graphical models can create more efficient and better regularized composite models. The main difficulties in implementing this in practice are associated with a discrepancy in suitable learning objectives as well as with the necessity of approximations for the inference. In this work we take one of the simplest inference methods, a truncated max-product Belief Propagation, and add what is necessary to make it a proper component of a deep learning model: We connect it to learning formulations with losses on marginals and compute the backprop operation. This BP-Layer can be used as the final or an intermediate block in convolutional neural networks (CNNs), allowing us to design a hierarchical model composing BP inference and CNNs at different scale levels. The model is applicable to a range of dense prediction problems, is well-trainable and provides parameter-efficient and robust solutions in stereo, optical flow and semantic segmentation.
Learned Collaborative Stereo Refinement
Jul 31, 2019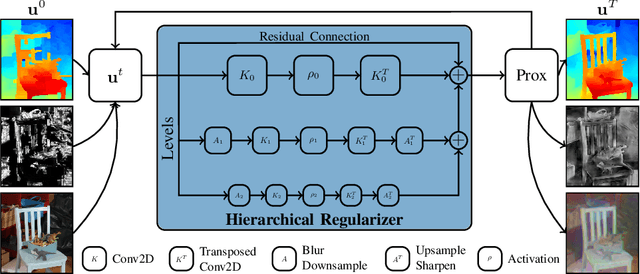

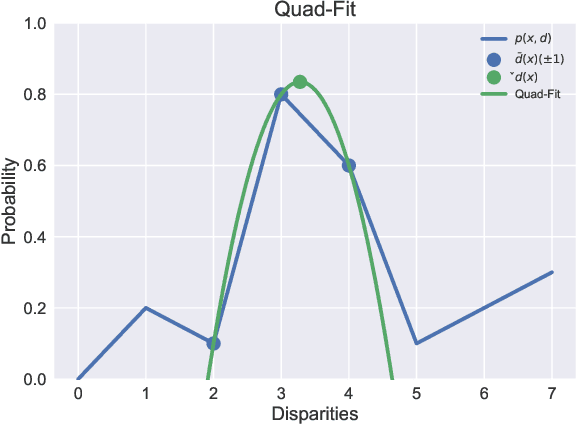

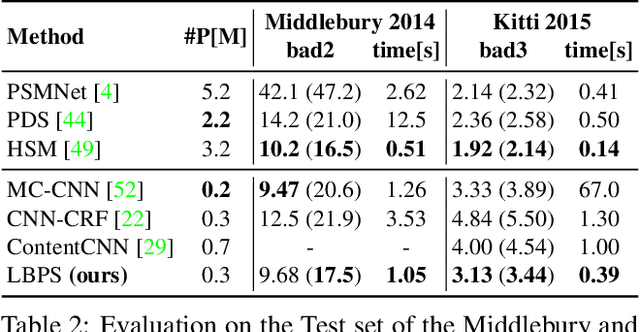
In this work, we propose a learning-based method to denoise and refine disparity maps of a given stereo method. The proposed variational network arises naturally from unrolling the iterates of a proximal gradient method applied to a variational energy defined in a joint disparity, color, and confidence image space. Our method allows to learn a robust collaborative regularizer leveraging the joint statistics of the color image, the confidence map and the disparity map. Due to the variational structure of our method, the individual steps can be easily visualized, thus enabling interpretability of the method. We can therefore provide interesting insights into how our method refines and denoises disparity maps. The efficiency of our method is demonstrated by the publicly available stereo benchmarks Middlebury 2014 and Kitti 2015.
Self-Supervised Learning for Stereo Reconstruction on Aerial Images
Jul 29, 2019
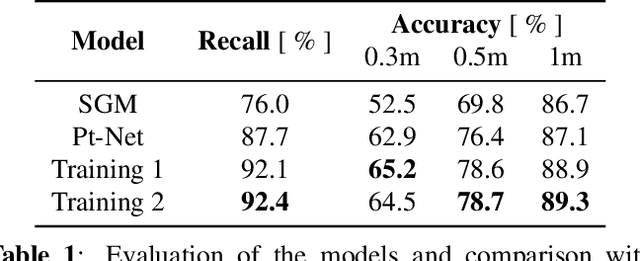
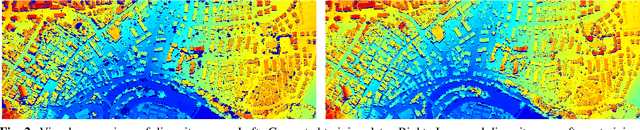
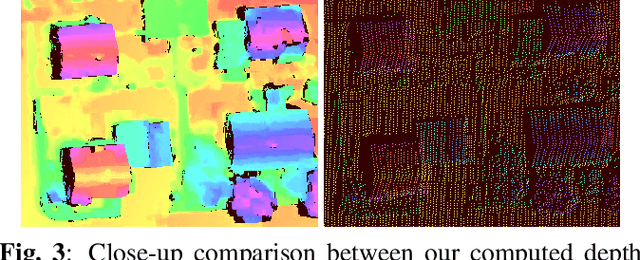
Recent developments established deep learning as an inevitable tool to boost the performance of dense matching and stereo estimation. On the downside, learning these networks requires a substantial amount of training data to be successful. Consequently, the application of these models outside of the laboratory is far from straight forward. In this work we propose a self-supervised training procedure that allows us to adapt our network to the specific (imaging) characteristics of the dataset at hand, without the requirement of external ground truth data. We instead generate interim training data by running our intermediate network on the whole dataset, followed by conservative outlier filtering. Bootstrapped from a pre-trained version of our hybrid CNN-CRF model, we alternate the generation of training data and network training. With this simple concept we are able to lift the completeness and accuracy of the pre-trained version significantly. We also show that our final model compares favorably to other popular stereo estimation algorithms on an aerial dataset.
Learning Energy Based Inpainting for Optical Flow
Nov 09, 2018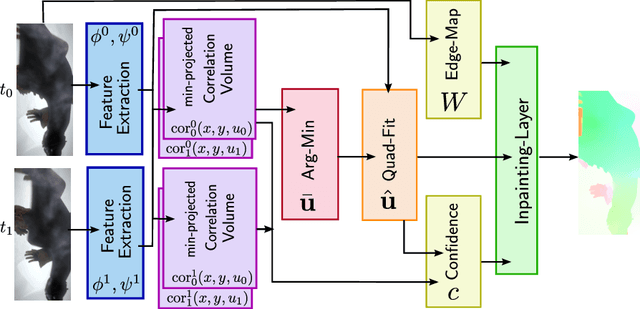


Modern optical flow methods are often composed of a cascade of many independent steps or formulated as a black box neural network that is hard to interpret and analyze. In this work we seek for a plain, interpretable, but learnable solution. We propose a novel inpainting based algorithm that approaches the problem in three steps: feature selection and matching, selection of supporting points and energy based inpainting. To facilitate the inference we propose an optimization layer that allows to backpropagate through 10K iterations of a first-order method without any numerical or memory problems. Compared to recent state-of-the-art networks, our modular CNN is very lightweight and competitive with other, more involved, inpainting based methods.
Scalable Full Flow with Learned Binary Descriptors
Jul 20, 2017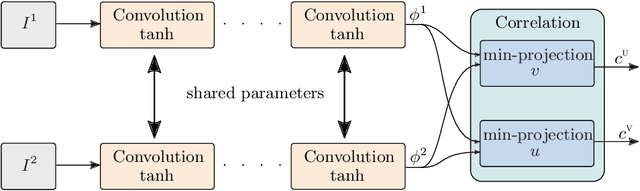
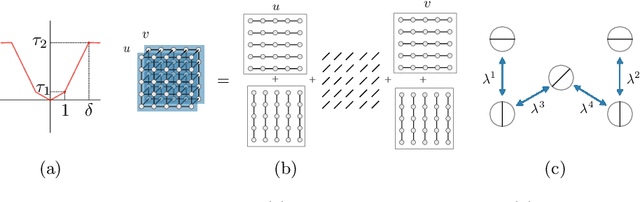

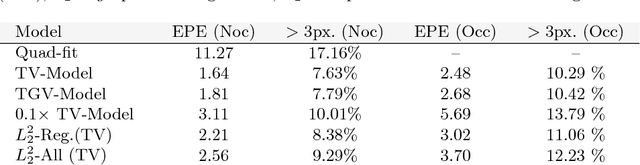
We propose a method for large displacement optical flow in which local matching costs are learned by a convolutional neural network (CNN) and a smoothness prior is imposed by a conditional random field (CRF). We tackle the computation- and memory-intensive operations on the 4D cost volume by a min-projection which reduces memory complexity from quadratic to linear and binary descriptors for efficient matching. This enables evaluation of the cost on the fly and allows to perform learning and CRF inference on high resolution images without ever storing the 4D cost volume. To address the problem of learning binary descriptors we propose a new hybrid learning scheme. In contrast to current state of the art approaches for learning binary CNNs we can compute the exact non-zero gradient within our model. We compare several methods for training binary descriptors and show results on public available benchmarks.
End-to-End Training of Hybrid CNN-CRF Models for Stereo
May 03, 2017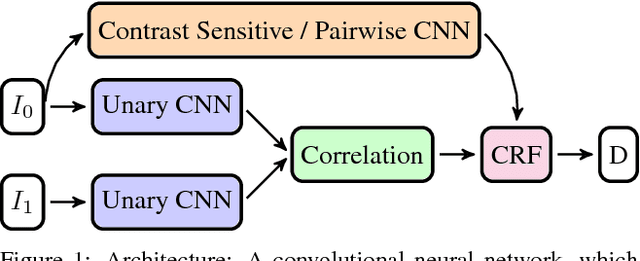
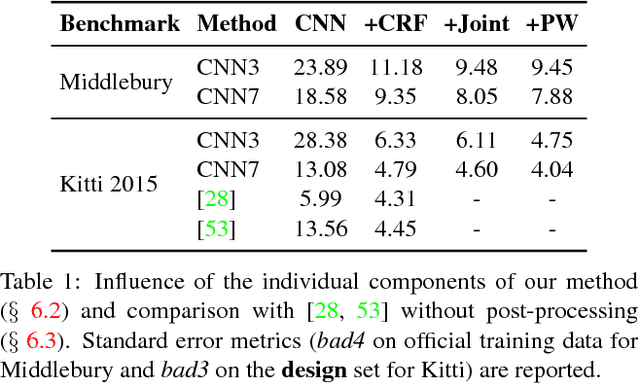

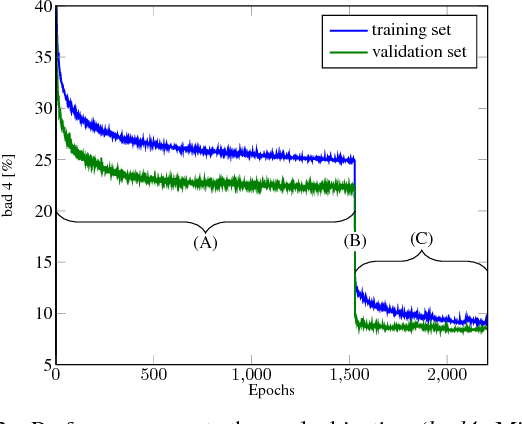
We propose a novel and principled hybrid CNN+CRF model for stereo estimation. Our model allows to exploit the advantages of both, convolutional neural networks (CNNs) and conditional random fields (CRFs) in an unified approach. The CNNs compute expressive features for matching and distinctive color edges, which in turn are used to compute the unary and binary costs of the CRF. For inference, we apply a recently proposed highly parallel dual block descent algorithm which only needs a small fixed number of iterations to compute a high-quality approximate minimizer. As the main contribution of the paper, we propose a theoretically sound method based on the structured output support vector machine (SSVM) to train the hybrid CNN+CRF model on large-scale data end-to-end. Our trained models perform very well despite the fact that we are using shallow CNNs and do not apply any kind of post-processing to the final output of the CRF. We evaluate our combined models on challenging stereo benchmarks such as Middlebury 2014 and Kitti 2015 and also investigate the performance of each individual component.