 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-based generation of Histopathological Whole Slide Images at a Gigapixel scale
Nov 14, 2023We present a novel diffusion-based approach to generate synthetic histopathological Whole Slide Images (WSIs) at an unprecedented gigapixel scale. Synthetic WSIs have many potential applications: They can augment training datasets to enhance the performance of many computational pathology applications. They allow the creation of synthesized copies of datasets that can be shared without violating privacy regulations. Or they can facilitate learning representations of WSIs without requiring data annotations. Despite this variety of applications, no existing deep-learning-based method generates WSIs at their typically high resolutions. Mainly due to the high computational complexity. Therefore, we propose a novel coarse-to-fine sampling scheme to tackle image generation of high-resolution WSIs. In this scheme, we increase the resolution of an initial low-resolution image to a high-resolution WSI. Particularly, a diffusion model sequentially adds fine details to images and increases their resolution. In our experiments, we train our method with WSIs from the TCGA-BRCA dataset. Additionally to quantitative evaluations, we also performed a user study with pathologists. The study results suggest that our generated WSIs resemble the structure of real WSIs.
InfoSeg: Unsupervised Semantic Image Segmentation with Mutual Information Maximization
Oct 07, 2021
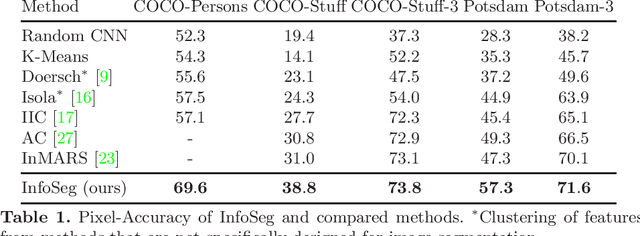
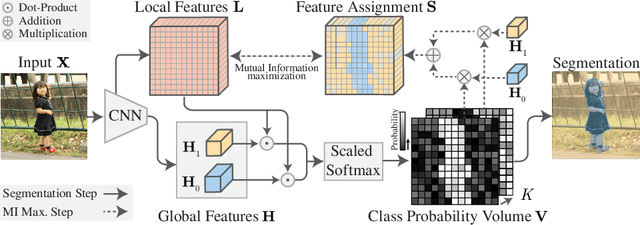

We propose a novel method for unsupervised semantic image segmentation based on mutual information maximization between local and global high-level image features. The core idea of our work is to leverage recent progress in self-supervised image representation learning. Representation learning methods compute a single high-level feature capturing an entire image. In contrast, we compute multiple high-level features, each capturing image segments of one particular semantic class. To this end, we propose a novel two-step learning procedure comprising a segmentation and a mutual information maximization step. In the first step, we segment images based on local and global features. In the second step, we maximize the mutual information between local features and high-level features of their respective class. For training, we provide solely unlabeled images and start from random network initialization. For quantitative and qualitative evaluation, we use established benchmarks, and COCO-Persons, whereby we introduce the latter in this paper as a challenging novel benchmark. InfoSeg significantly outperforms the current state-of-the-art, e.g., we achieve a relative increase of 26% in the Pixel Accuracy metric on the COCO-Stuff dataset.