 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoSeg: Unsupervised Semantic Image Segmentation with Mutual Information Maximization
Paper and Code
Oct 07, 2021
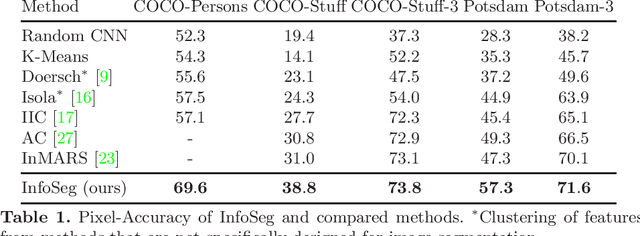
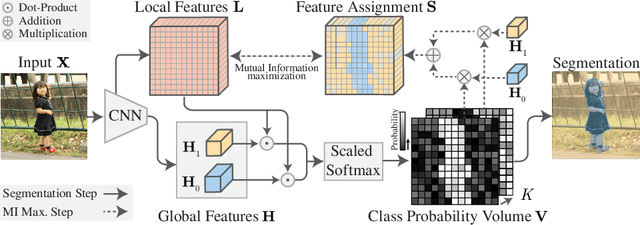

We propose a novel method for unsupervised semantic image segmentation based on mutual information maximization between local and global high-level image features. The core idea of our work is to leverage recent progress in self-supervised image representation learning. Representation learning methods compute a single high-level feature capturing an entire image. In contrast, we compute multiple high-level features, each capturing image segments of one particular semantic class. To this end, we propose a novel two-step learning procedure comprising a segmentation and a mutual information maximization step. In the first step, we segment images based on local and global features. In the second step, we maximize the mutual information between local features and high-level features of their respective class. For training, we provide solely unlabeled images and start from random network initialization. For quantitative and qualitative evaluation, we use established benchmarks, and COCO-Persons, whereby we introduce the latter in this paper as a challenging novel benchmark. InfoSeg significantly outperforms the current state-of-the-art, e.g., we achieve a relative increase of 26% in the Pixel Accuracy metric on the COCO-Stuff dataset.