 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPE: Temporal Attention-based Probabilistic human pose and shape Estimation
Apr 29, 2023Reconstructing 3D human pose and shape from monocular videos is a well-studied but challenging problem. Common challenges include occlusions, the inherent ambiguities in the 2D to 3D mapping and the computational complexity of video processing. Existing methods ignore the ambiguities of the reconstruction and provide a single deterministic estimate for the 3D pose. In order to address these issues, we present a Temporal Attention based Probabilistic human pose and shape Estimation method (TAPE) that operates on an RGB video. More specifically, we propose to use a neural network to encode video frames to temporal features using an attention-based neural network. Given these features, we output a per-frame but temporally-informed probability distribution for the human pose using Normalizing Flows. We show that TAPE outperforms state-of-the-art methods in standard benchmarks and serves as an effective video-based prior for optimization-based human pose and shape estimation. Code is available at: https: //github.com/nikosvasilik/TAPE
Multi-view Image-based Hand Geometry Refinement using Differentiable Monte Carlo Ray Tracing
Jul 12, 2021
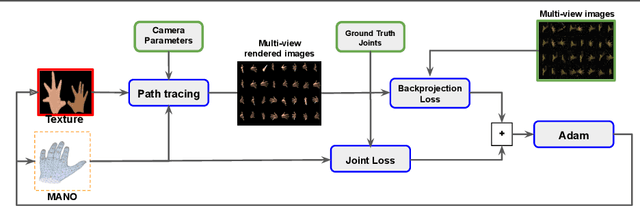
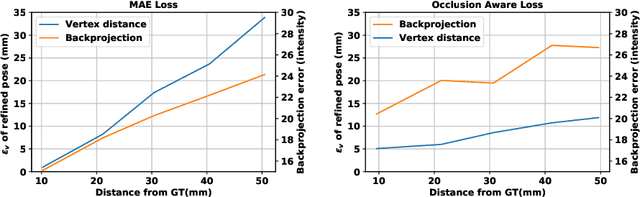
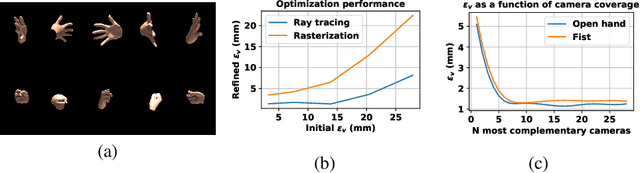
The amount and quality of datasets and tools available in the research field of hand pose and shape estimation act as evidence to the significant progress that has been made. We find that there is still room for improvement in both fronts, and even beyond. Even the datasets of the highest quality, reported to date, have shortcomings in annotation. There are tools in the literature that can assist in that direction and yet they have not been considered, so far. To demonstrate how these gaps can be bridged, we employ such a publicly available, multi-camera dataset of hands (InterHand2.6M), and perform effective image-based refinement to improve on the imperfect ground truth annotations, yielding a better dataset. The image-based refinement is achieved through raytracing, a method that has not been employed so far to relevant problems and is hereby shown to be superior to the approximative alternatives that have been employed in the past. To tackle the lack of reliable ground truth, we resort to realistic synthetic data, to show that the improvement we induce is indeed significant, qualitatively, and quantitatively, too.
H-GAN: the power of GANs in your Hands
Apr 21, 2021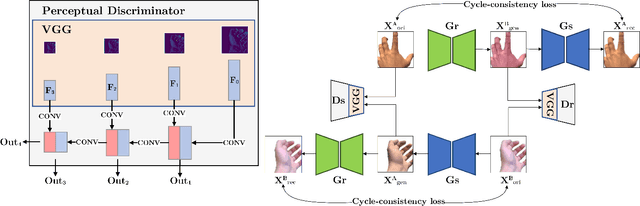
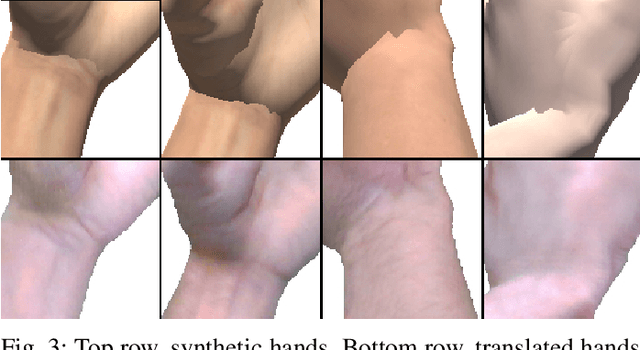
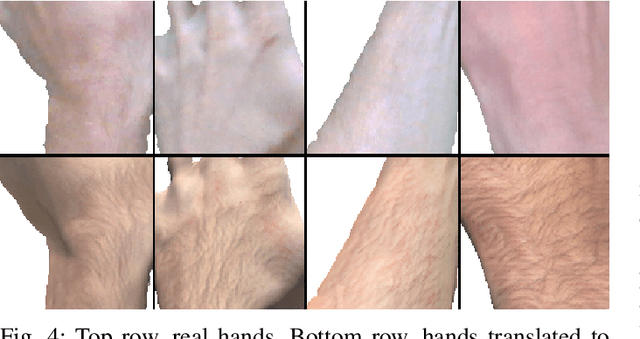
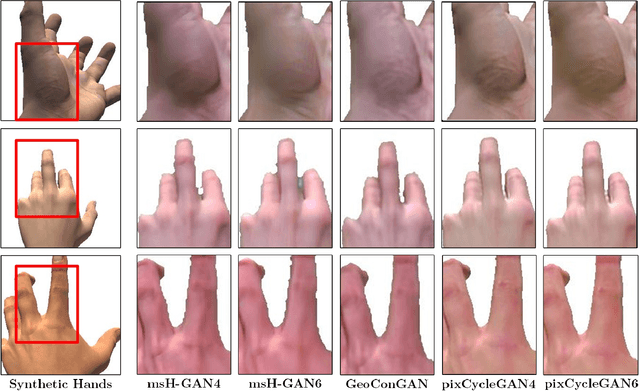
We present HandGAN (H-GAN), a cycle-consistent adversarial learning approach implementing multi-scale perceptual discriminators. It is designed to translate synthetic images of hands to the real domain. Synthetic hands provide complete ground-truth annotations, yet they are not representative of the target distribution of real-world data. We strive to provide the perfect blend of a realistic hand appearance with synthetic annotations. Relying on image-to-image translation, we improve the appearance of synthetic hands to approximate the statistical distribution underlying a collection of real images of hands. H-GAN tackles not only the cross-domain tone mapping but also structural differences in localized areas such as shading discontinuities. Results are evaluated on a qualitative and quantitative basis improving previous works. Furthermore, we relied on the hand classification task to claim our generated hands are statistically similar to the real domain of hands.