 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEven Faster SNN Simulation with Lazy+Event-driven Plasticity and Shared Atomics
Jul 08, 2021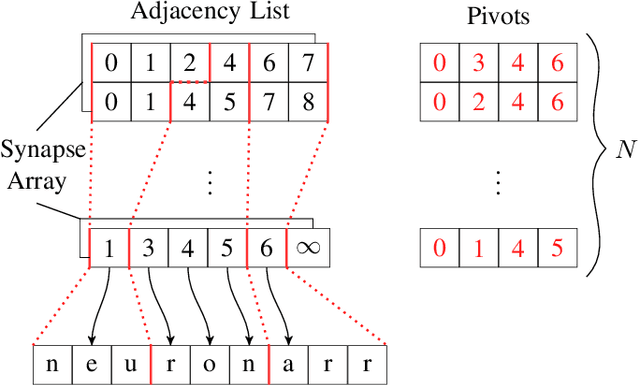


We present two novel optimizations that accelerate clock-based spiking neural network (SNN) simulators. The first one targets spike timing dependent plasticity (STDP). It combines lazy- with event-driven plasticity and efficiently facilitates the computation of pre- and post-synaptic spikes using bitfields and integer intrinsics. It offers higher bandwidth than event-driven plasticity alone and achieves a 1.5x-2x speedup over our closest competitor. The second optimization targets spike delivery. We partition our graph representation in a way that bounds the number of neurons that need be updated at any given time which allows us to perform said update in shared memory instead of global memory. This is 2x-2.5x faster than our closest competitor. Both optimizations represent the final evolutionary stages of years of iteration on STDP and spike delivery inside "Spice" (/spaIk/), our state of the art SNN simulator. The proposed optimizations are not exclusive to our graph representation or pipeline but are applicable to a multitude of simulator designs. We evaluate our performance on three well-established models and compare ourselves against three other state of the art simulators.
Multi-GPU SNN Simulation with Perfect Static Load Balancing
Feb 09, 2021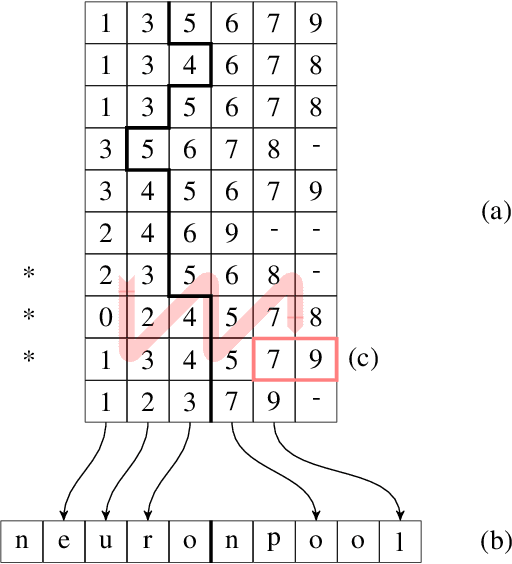
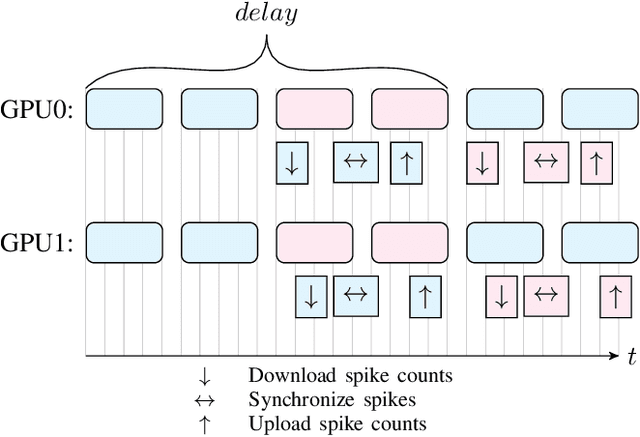
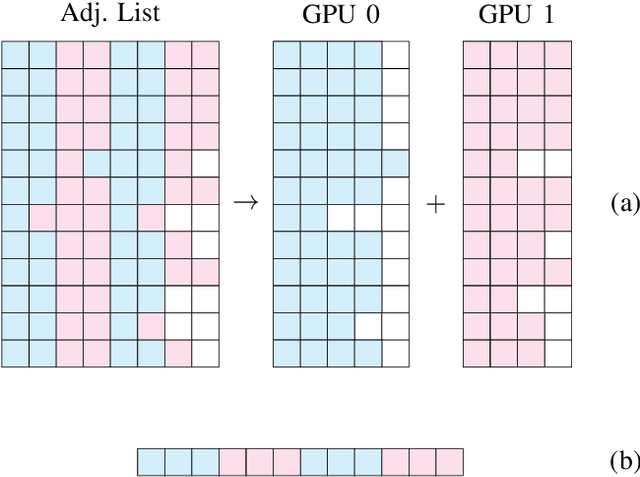
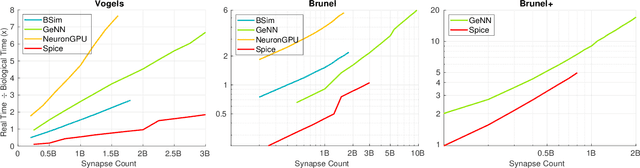
We present a SNN simulator which scales to millions of neurons, billions of synapses, and 8 GPUs. This is made possible by 1) a novel, cache-aware spike transmission algorithm 2) a model parallel multi-GPU distribution scheme and 3) a static, yet very effective load balancing strategy. The simulator further features an easy to use API and the ability to create custom models. We compare the proposed simulator against two state of the art ones on a series of benchmarks using three well-established models. We find that our simulator is faster, consumes less memory, and scales linearly with the number of GPUs.
Faster and Simpler SNN Simulation with Work Queues
Dec 17, 2019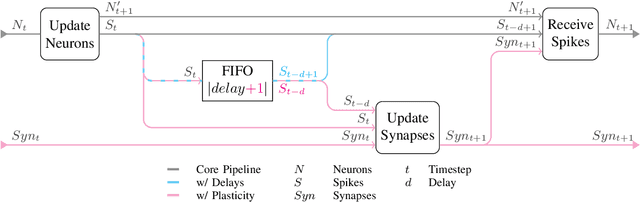


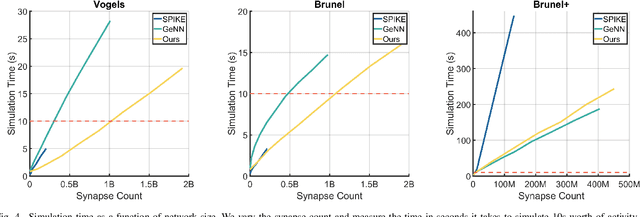
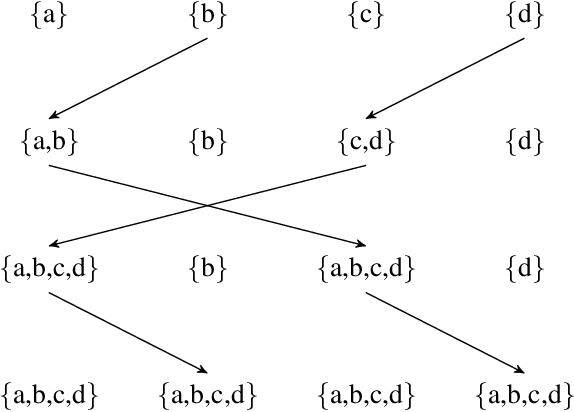
We present a clock-driven Spiking Neural Network simulator which is up to 3x faster than the state of the art while, at the same time, being more general and requiring less programming effort on both the user's and maintainer's side. This is made possible by designing our pipeline around "work queues" which act as interfaces between stages and greatly reduce implementation complexity. We evaluate our work using three well-established SNN models on a series of benchmarks.