 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecond Competition on Presentation Attack Detection on ID Card
Jul 27, 2025This work summarises and reports the results of the second Presentation Attack Detection competition on ID cards. This new version includes new elements compared to the previous one. (1) An automatic evaluation platform was enabled for automatic benchmarking; (2) Two tracks were proposed in order to evaluate algorithms and datasets, respectively; and (3) A new ID card dataset was shared with Track 1 teams to serve as the baseline dataset for the training and optimisation. The Hochschule Darmstadt, Fraunhofer-IGD, and Facephi company jointly organised this challenge. 20 teams were registered, and 74 submitted models were evaluated. For Track 1, the "Dragons" team reached first place with an Average Ranking and Equal Error rate (EER) of AV-Rank of 40.48% and 11.44% EER, respectively. For the more challenging approach in Track 2, the "Incode" team reached the best results with an AV-Rank of 14.76% and 6.36% EER, improving on the results of the first edition of 74.30% and 21.87% EER, respectively. These results suggest that PAD on ID cards is improving, but it is still a challenging problem related to the number of images, especially of bona fide images.
Detecting Facial Image Manipulations with Multi-Layer CNN Models
Dec 09, 2024



The rapid evolution of digital image manipulation techniques poses significant challenges for content verification, with models such as stable diffusion and mid-journey producing highly realistic, yet synthetic, images that can deceive human perception. This research develops and evaluates convolutional neural networks (CNNs) specifically tailored for the detection of these manipulated images. The study implements a comparative analysis of three progressively complex CNN architectures, assessing their ability to classify and localize manipulations across various facial image modifications. Regularization and optimization techniques were systematically incorporated to improve feature extraction and performance. The results indicate that the proposed models achieve an accuracy of up to 76\% in distinguishing manipulated images from genuine ones, surpassing traditional approaches. This research not only highlights the potential of CNNs in enhancing the robustness of digital media verification tools, but also provides insights into effective architectural adaptations and training strategies for low-computation environments. Future work will build on these findings by extending the architectures to handle more diverse manipulation techniques and integrating multi-modal data for improved detection capabilities.
First Competition on Presentation Attack Detection on ID Card
Aug 31, 2024



This paper summarises the Competition on Presentation Attack Detection on ID Cards (PAD-IDCard) held at the 2024 International Joint Conference on Biometrics (IJCB2024). The competition attracted a total of ten registered teams, both from academia and industry. In the end, the participating teams submitted five valid submissions, with eight models to be evaluated by the organisers. The competition presented an independent assessment of current state-of-the-art algorithms. Today, no independent evaluation on cross-dataset is available; therefore, this work determined the state-of-the-art on ID cards. To reach this goal, a sequestered test set and baseline algorithms were used to evaluate and compare all the proposals. The sequestered test dataset contains ID cards from four different countries. In summary, a team that chose to be "Anonymous" reached the best average ranking results of 74.80%, followed very closely by the "IDVC" team with 77.65%.
SqueezeFacePoseNet: Lightweight Face Verification Across Different Poses for Mobile Platforms
Jul 16, 2020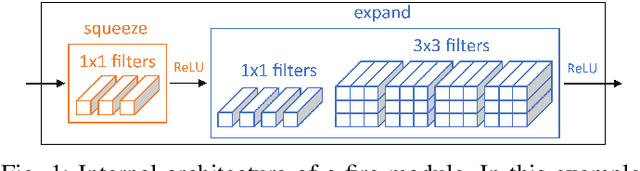


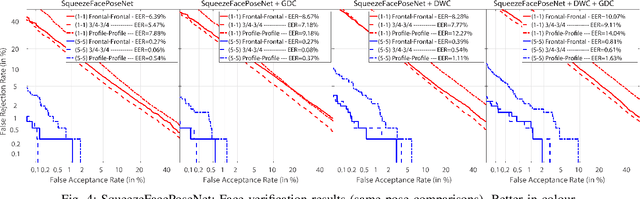
Virtual applications through mobile platforms are one of the most critical and ever-growing fields in AI, where ubiquitous and real-time person authentication has become critical after the breakthrough of all services provided via mobile devices. In this context, face verification technologies can provide reliable and robust user authentication, given the availability of cameras in these devices, as well as their widespread use in everyday applications. The rapid development of deep Convolutional Neural Networks has resulted in many accurate face verification architectures. However, their typical size (hundreds of megabytes) makes them infeasible to be incorporated in downloadable mobile applications where the entire file typically may not exceed 100 Mb. Accordingly, we address the challenge of developing a lightweight face recognition network of just a few megabytes that can operate with sufficient accuracy in comparison to much larger models. The network also should be able to operate under different poses, given the variability naturally observed in uncontrolled environments where mobile devices are typically used. In this paper, we adapt the lightweight SqueezeNet model, of just 4.4MB, to effectively provide cross-pose face recognition. After trained on the MS-Celeb-1M and VGGFace2 databases, our model achieves an EER of 1.23% on the difficult frontal vs. profile comparison, and0.54% on profile vs. profile images. Under less extreme variations involving frontal images in any of the enrolment/query images pair, EER is pushed down to<0.3%, and the FRR at FAR=0.1%to less than 1%. This makes our light model suitable for face recognition where at least acquisition of the enrolment image can be controlled. At the cost of a slight degradation in performance, we also test an even lighter model (of just 2.5MB) where regular convolutions are replaced with depth-wise separable convolutions.