 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSCAR: Open-Set CAD Retrieval from a Language Prompt and a Single Image
Jan 12, 20266D object pose estimation plays a crucial role in scene understanding for applications such as robotics and augmented reality. To support the needs of ever-changing object sets in such context, modern zero-shot object pose estimators were developed to not require object-specific training but only rely on CAD models. Such models are hard to obtain once deployed, and a continuously changing and growing set of objects makes it harder to reliably identify the instance model of interest. To address this challenge, we introduce an Open-Set CAD Retrieval from a Language Prompt and a Single Image (OSCAR), a novel training-free method that retrieves a matching object model from an unlabeled 3D object database. During onboarding, OSCAR generates multi-view renderings of database models and annotates them with descriptive captions using an image captioning model. At inference, GroundedSAM detects the queried object in the input image, and multi-modal embeddings are computed for both the Region-of-Interest and the database captions. OSCAR employs a two-stage retrieval: text-based filtering using CLIP identifies candidate models, followed by image-based refinement using DINOv2 to select the most visually similar object. In our experiments we demonstrate that OSCAR outperforms all state-of-the-art methods on the cross-domain 3D model retrieval benchmark MI3DOR. Furthermore, we demonstrate OSCAR's direct applicability in automating object model sourcing for 6D object pose estimation. We propose using the most similar object model for pose estimation if the exact instance is not available and show that OSCAR achieves an average precision of 90.48\% during object retrieval on the YCB-V object dataset. Moreover, we demonstrate that the most similar object model can be utilized for pose estimation using Megapose achieving better results than a reconstruction-based approach.
Phys-Liquid: A Physics-Informed Dataset for Estimating 3D Geometry and Volume of Transparent Deformable Liquids
Nov 14, 2025
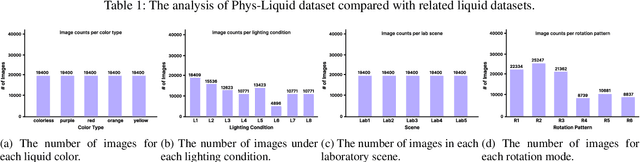

Estimating the geometric and volumetric properties of transparent deformable liquids is challenging due to optical complexities and dynamic surface deformations induced by container movements. Autonomous robots performing precise liquid manipulation tasks, such as dispensing, aspiration, and mixing, must handle containers in ways that inevitably induce these deformations, complicating accurate liquid state assessment. Current datasets lack comprehensive physics-informed simulation data representing realistic liquid behaviors under diverse dynamic scenarios. To bridge this gap, we introduce Phys-Liquid, a physics-informed dataset comprising 97,200 simulation images and corresponding 3D meshes, capturing liquid dynamics across multiple laboratory scenes, lighting conditions, liquid colors, and container rotations. To validate the realism and effectiveness of Phys-Liquid, we propose a four-stage reconstruction and estimation pipeline involving liquid segmentation, multi-view mask generation, 3D mesh reconstruction, and real-world scaling. Experimental results demonstrate improved accuracy and consistency in reconstructing liquid geometry and volume, outperforming existing benchmarks. The dataset and associated validation methods facilitate future advancements in transparent liquid perception tasks. The dataset and code are available at https://dualtransparency.github.io/Phys-Liquid/.
ReFlow6D: Refraction-Guided Transparent Object 6D Pose Estimation via Intermediate Representation Learning
Dec 30, 2024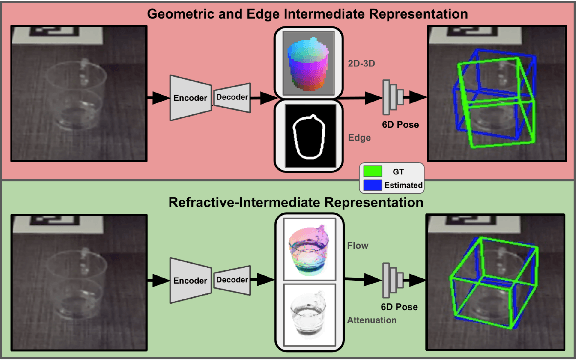
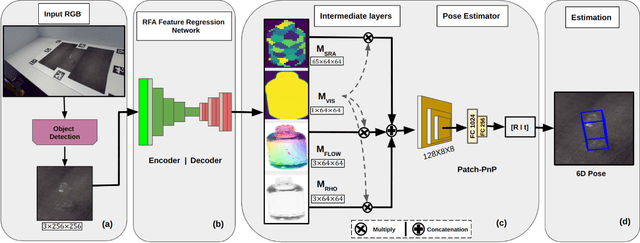


Transparent objects are ubiquitous in daily life, making their perception and robotics manipulation important. However, they present a major challenge due to their distinct refractive and reflective properties when it comes to accurately estimating the 6D pose. To solve this, we present ReFlow6D, a novel method for transparent object 6D pose estimation that harnesses the refractive-intermediate representation. Unlike conventional approaches, our method leverages a feature space impervious to changes in RGB image space and independent of depth information. Drawing inspiration from image matting, we model the deformation of the light path through transparent objects, yielding a unique object-specific intermediate representation guided by light refraction that is independent of the environment in which objects are observed. By integrating these intermediate features into the pose estimation network, we show that ReFlow6D achieves precise 6D pose estimation of transparent objects, using only RGB images as input. Our method further introduces a novel transparent object compositing loss, fostering the generation of superior refractive-intermediate features. Empirical evaluations show that our approach significantly outperforms state-of-the-art methods on TOD and Trans32K-6D datasets. Robot grasping experiments further demonstrate that ReFlow6D's pose estimation accuracy effectively translates to real-world robotics task. The source code is available at: https://github.com/StoicGilgamesh/ReFlow6D and https://github.com/StoicGilgamesh/matting_rendering.
STAR: Shape-focused Texture Agnostic Representations for Improved Object Detection and 6D Pose Estimation
Feb 07, 2024



Recent advances in machine learning have greatly benefited object detection and 6D pose estimation for robotic grasping. However, textureless and metallic objects still pose a significant challenge due to fewer visual cues and the texture bias of CNNs. To address this issue, we propose a texture-agnostic approach that focuses on learning from CAD models and emphasizes object shape features. To achieve a focus on learning shape features, the textures are randomized during the rendering of the training data. By treating the texture as noise, the need for real-world object instances or their final appearance during training data generation is eliminated. The TLESS and ITODD datasets, specifically created for industrial settings in robotics and featuring textureless and metallic objects, were used for evaluation. Texture agnosticity also increases the robustness against image perturbations such as imaging noise, motion blur, and brightness changes, which are common in robotics applications. Code and datasets are publicly available at github.com/hoenigpeter/randomized_texturing.
ZS6D: Zero-shot 6D Object Pose Estimation using Vision Transformers
Sep 21, 2023



As robotic systems increasingly encounter complex and unconstrained real-world scenarios, there is a demand to recognize diverse objects. The state-of-the-art 6D object pose estimation methods rely on object-specific training and therefore do not generalize to unseen objects. Recent novel object pose estimation methods are solving this issue using task-specific fine-tuned CNNs for deep template matching. This adaptation for pose estimation still requires expensive data rendering and training procedures. MegaPose for example is trained on a dataset consisting of two million images showing 20,000 different objects to reach such generalization capabilities. To overcome this shortcoming we introduce ZS6D, for zero-shot novel object 6D pose estimation. Visual descriptors, extracted using pre-trained Vision Transformers (ViT), are used for matching rendered templates against query images of objects and for establishing local correspondences. These local correspondences enable deriving geometric correspondences and are used for estimating the object's 6D pose with RANSAC-based PnP. This approach showcases that the image descriptors extracted by pre-trained ViTs are well-suited to achieve a notable improvement over two state-of-the-art novel object 6D pose estimation methods, without the need for task-specific fine-tuning. Experiments are performed on LMO, YCBV, and TLESS. In comparison to one of the two methods we improve the Average Recall on all three datasets and compared to the second method we improve on two datasets.
Challenges for Monocular 6D Object Pose Estimation in Robotics
Jul 22, 2023



Object pose estimation is a core perception task that enables, for example, object grasping and scene understanding. The widely available, inexpensive and high-resolution RGB sensors and CNNs that allow for fast inference based on this modality make monocular approaches especially well suited for robotics applications. We observe that previous surveys on object pose estimation establish the state of the art for varying modalities, single- and multi-view settings, and datasets and metrics that consider a multitude of applications. We argue, however, that those works' broad scope hinders the identification of open challenges that are specific to monocular approaches and the derivation of promising future challenges for their application in robotics. By providing a unified view on recent publications from both robotics and computer vision, we find that occlusion handling, novel pose representations, and formalizing and improving category-level pose estimation are still fundamental challenges that are highly relevant for robotics. Moreover, to further improve robotic performance, large object sets, novel objects, refractive materials, and uncertainty estimates are central, largely unsolved open challenges. In order to address them, ontological reasoning, deformability handling, scene-level reasoning, realistic datasets, and the ecological footprint of algorithms need to be improved.
Self-supervised Vision Transformers for 3D Pose Estimation of Novel Objects
May 31, 2023



Object pose estimation is important for object manipulation and scene understanding. In order to improve the general applicability of pose estimators, recent research focuses on providing estimates for novel objects, that is objects unseen during training. Such works use deep template matching strategies to retrieve the closest template connected to a query image. This template retrieval implicitly provides object class and pose. Despite the recent success and improvements of Vision Transformers over CNNs for many vision tasks, the state of the art uses CNN-based approaches for novel object pose estimation. This work evaluates and demonstrates the differences between self-supervised CNNs and Vision Transformers for deep template matching. In detail, both types of approaches are trained using contrastive learning to match training images against rendered templates of isolated objects. At test time, such templates are matched against query images of known and novel objects under challenging settings, such as clutter, occlusion and object symmetries, using masked cosine similarity. The presented results not only demonstrate that Vision Transformers improve in matching accuracy over CNNs, but also that for some cases pre-trained Vision Transformers do not need fine-tuning to do so. Furthermore, we highlight the differences in optimization and network architecture when comparing these two types of network for deep template matching.
Open Challenges for Monocular Single-shot 6D Object Pose Estimation
Feb 23, 2023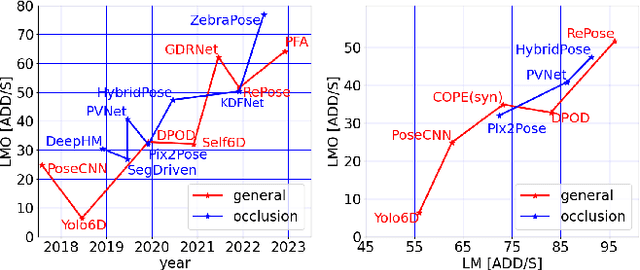
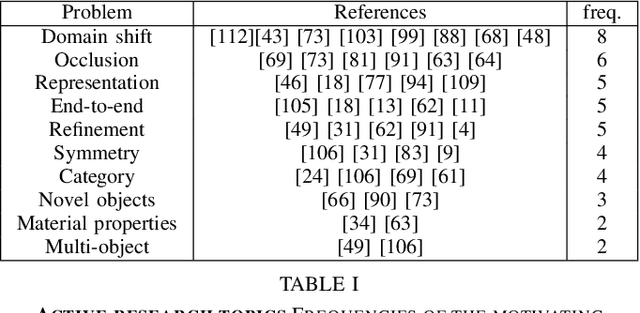
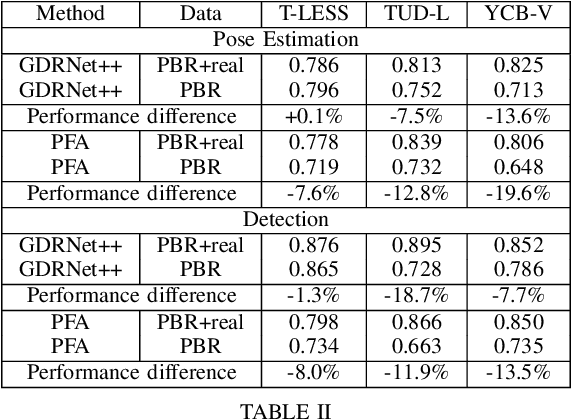
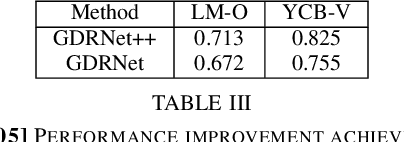
Object pose estimation is a non-trivial task that enables robotic manipulation, bin picking, augmented reality, and scene understanding, to name a few use cases. Monocular object pose estimation gained considerable momentum with the rise of high-performing deep learning-based solutions and is particularly interesting for the community since sensors are inexpensive and inference is fast. Prior works establish the comprehensive state of the art for diverse pose estimation problems. Their broad scopes make it difficult to identify promising future directions. We narrow down the scope to the problem of single-shot monocular 6D object pose estimation, which is commonly used in robotics, and thus are able to identify such trends. By reviewing recent publications in robotics and computer vision, the state of the art is established at the union of both fields. Following that, we identify promising research directions in order to help researchers to formulate relevant research ideas and effectively advance the state of the art. Findings include that methods are sophisticated enough to overcome the domain shift and that occlusion handling is a fundamental challenge. We also highlight problems such as novel object pose estimation and challenging materials handling as central challenges to advance robotics.
Sim2Real 3D Object Classification using Spherical Kernel Point Convolution and a Deep Center Voting Scheme
Mar 10, 2021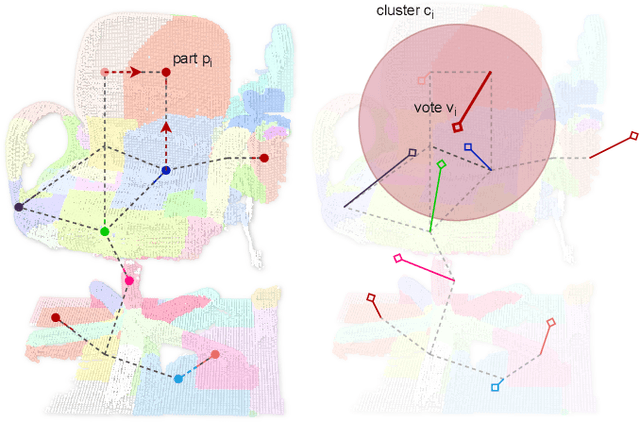
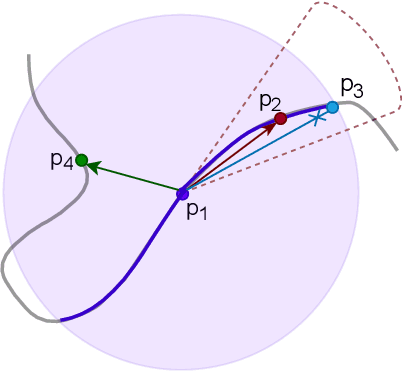
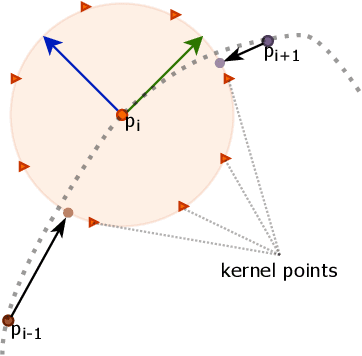
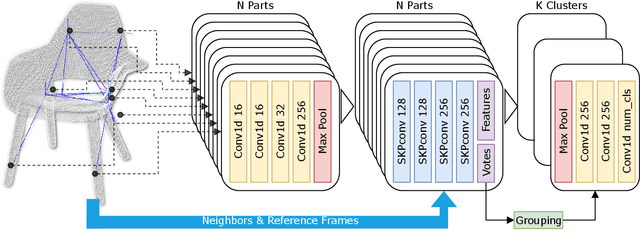
While object semantic understanding is essential for most service robotic tasks, 3D object classification is still an open problem. Learning from artificial 3D models alleviates the cost of annotation necessary to approach this problem, but most methods still struggle with the differences existing between artificial and real 3D data. We conjecture that the cause of those issue is the fact that many methods learn directly from point coordinates, instead of the shape, as the former is hard to center and to scale under variable occlusions reliably. We introduce spherical kernel point convolutions that directly exploit the object surface, represented as a graph, and a voting scheme to limit the impact of poor segmentation on the classification results. Our proposed approach improves upon state-of-the-art methods by up to 36% when transferring from artificial objects to real objects.
Addressing the Sim2Real Gap in Robotic 3D Object Classification
Oct 28, 2019
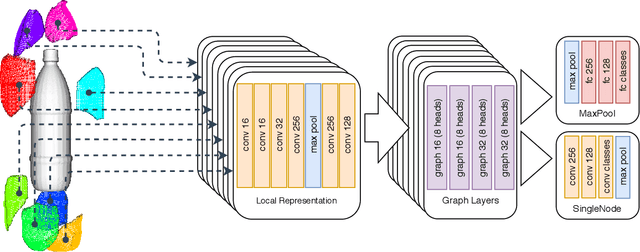

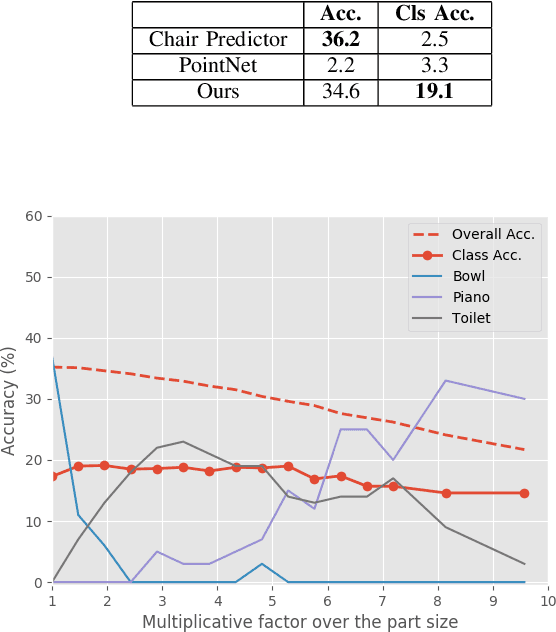
Object classification with 3D data is an essential component of any scene understanding method. It has gained significant interest in a variety of communities, most notably in robotics and computer graphics. While the advent of deep learning has progressed the field of 3D object classification, most work using this data type are solely evaluated on CAD model datasets. Consequently, current work does not address the discrepancies existing between real and artificial data. In this work, we examine this gap in a robotic context by specifically addressing the problem of classification when transferring from artificial CAD models to real reconstructed objects. This is performed by training on ModelNet (CAD models) and evaluating on ScanNet (reconstructed objects). We show that standard methods do not perform well in this task. We thus introduce a method that carefully samples object parts that are reproducible under various transformations and hence robust. Using graph convolution to classify the composed graph of parts, our method significantly improves upon the baseline.