 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrackAgent: 6D Object Tracking via Reinforcement Learning
Jul 28, 2023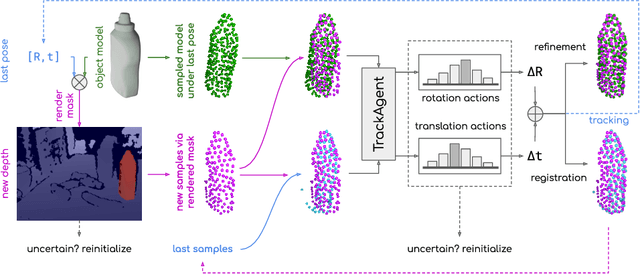


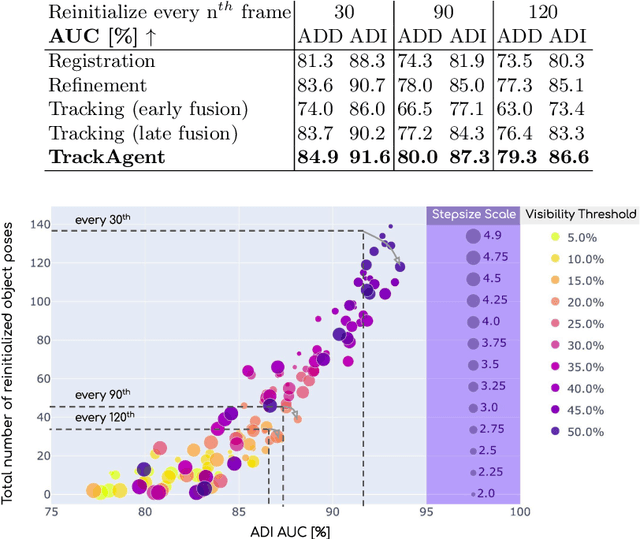
Tracking an object's 6D pose, while either the object itself or the observing camera is moving, is important for many robotics and augmented reality applications. While exploiting temporal priors eases this problem, object-specific knowledge is required to recover when tracking is lost. Under the tight time constraints of the tracking task, RGB(D)-based methods are often conceptionally complex or rely on heuristic motion models. In comparison, we propose to simplify object tracking to a reinforced point cloud (depth only) alignment task. This allows us to train a streamlined approach from scratch with limited amounts of sparse 3D point clouds, compared to the large datasets of diverse RGBD sequences required in previous works. We incorporate temporal frame-to-frame registration with object-based recovery by frame-to-model refinement using a reinforcement learning (RL) agent that jointly solves for both objectives. We also show that the RL agent's uncertainty and a rendering-based mask propagation are effective reinitialization triggers.
COPE: End-to-end trainable Constant Runtime Object Pose Estimation
Aug 22, 2022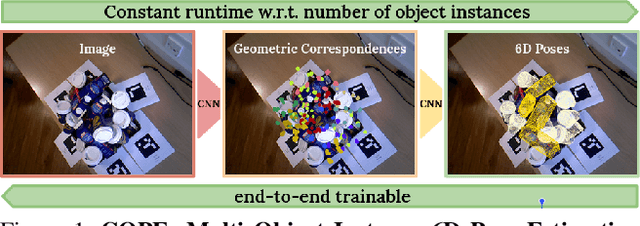

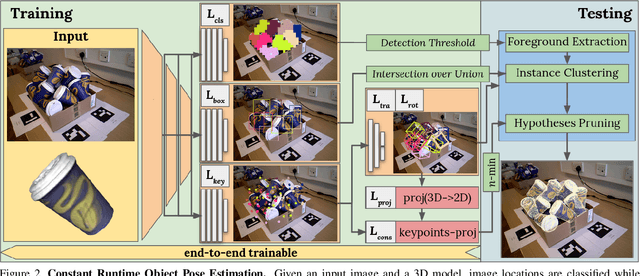
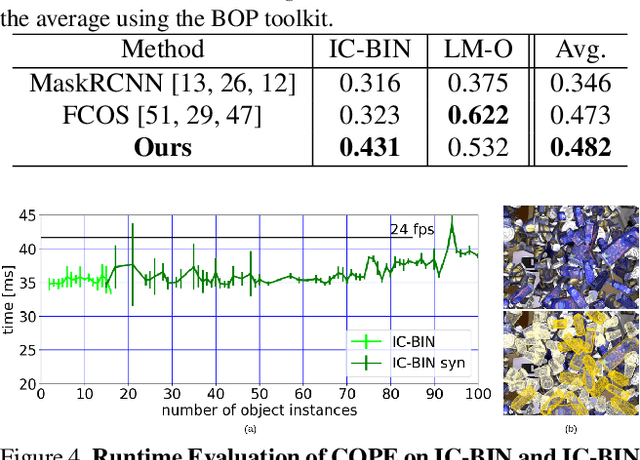
State-of-the-art object pose estimation handles multiple instances in a test image by using multi-model formulations: detection as a first stage and then separately trained networks per object for 2D-3D geometric correspondence prediction as a second stage. Poses are subsequently estimated using the Perspective-n-Points algorithm at runtime. Unfortunately, multi-model formulations are slow and do not scale well with the number of object instances involved. Recent approaches show that direct 6D object pose estimation is feasible when derived from the aforementioned geometric correspondences. We present an approach that learns an intermediate geometric representation of multiple objects to directly regress 6D poses of all instances in a test image. The inherent end-to-end trainability overcomes the requirement of separately processing individual object instances. By calculating the mutual Intersection-over-Unions, pose hypotheses are clustered into distinct instances, which achieves negligible runtime overhead with respect to the number of object instances. Results on multiple challenging standard datasets show that the pose estimation performance is superior to single-model state-of-the-art approaches despite being more than ~35 times faster. We additionally provide an analysis showing real-time applicability (>24 fps) for images where more than 90 object instances are present. Further results show the advantage of supervising geometric-correspondence-based object pose estimation with the 6D pose.
SporeAgent: Reinforced Scene-level Plausibility for Object Pose Refinement
Jan 01, 2022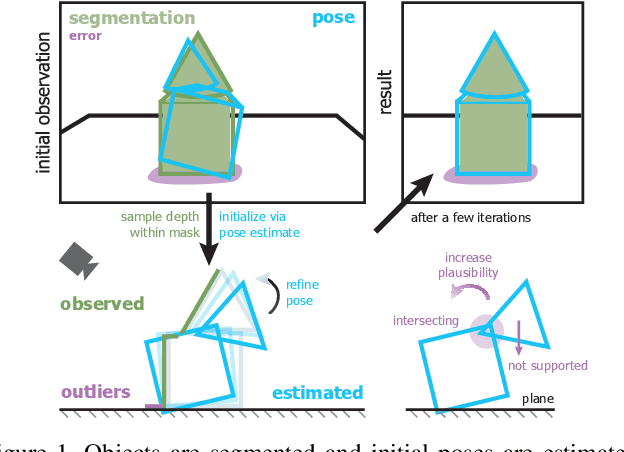

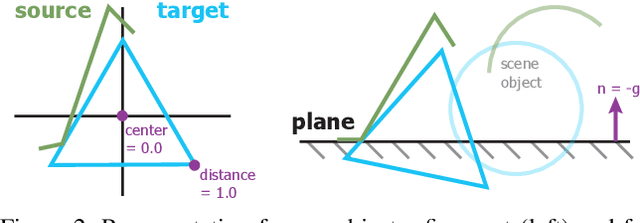
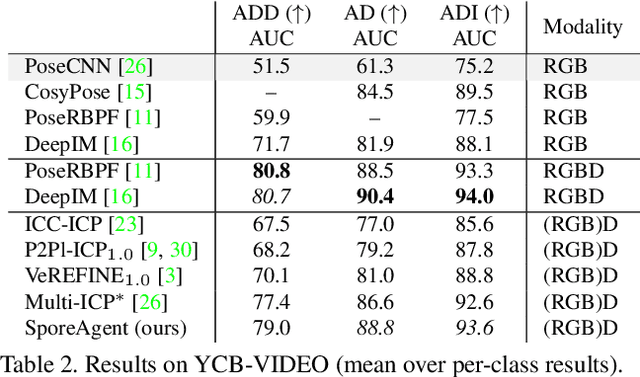
Observational noise, inaccurate segmentation and ambiguity due to symmetry and occlusion lead to inaccurate object pose estimates. While depth- and RGB-based pose refinement approaches increase the accuracy of the resulting pose estimates, they are susceptible to ambiguity in the observation as they consider visual alignment. We propose to leverage the fact that we often observe static, rigid scenes. Thus, the objects therein need to be under physically plausible poses. We show that considering plausibility reduces ambiguity and, in consequence, allows poses to be more accurately predicted in cluttered environments. To this end, we extend a recent RL-based registration approach towards iterative refinement of object poses. Experiments on the LINEMOD and YCB-VIDEO datasets demonstrate the state-of-the-art performance of our depth-based refinement approach.
Risk-Averse Biased Human Policies in Assistive Multi-Armed Bandit Settings
Apr 12, 2021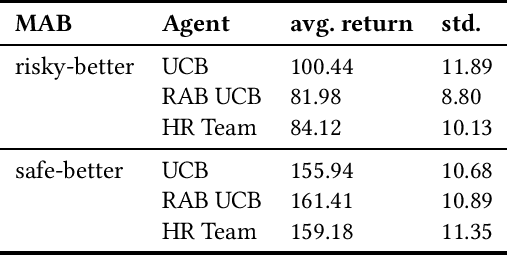
Assistive multi-armed bandit problems can be used to model team situations between a human and an autonomous system like a domestic service robot. To account for human biases such as the risk-aversion described in the Cumulative Prospect Theory, the setting is expanded to using observable rewards. When robots leverage knowledge about the risk-averse human model they eliminate the bias and make more rational choices. We present an algorithm that increases the utility value of such human-robot teams. A brief evaluation indicates that arbitrary reward functions can be handled.
ReAgent: Point Cloud Registration using Imitation and Reinforcement Learning
Mar 28, 2021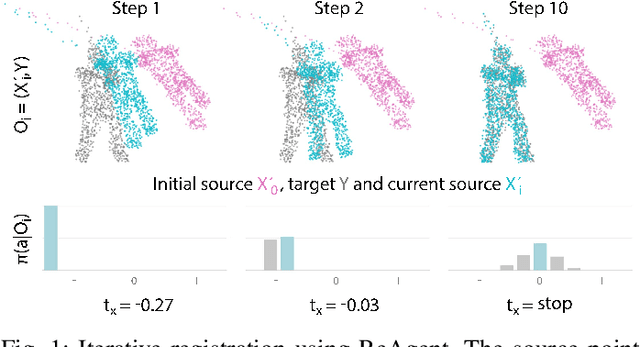
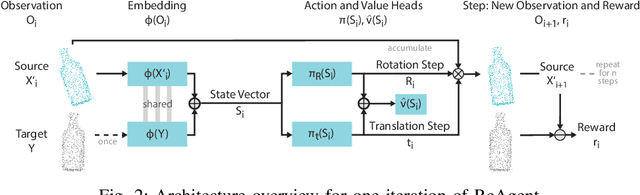
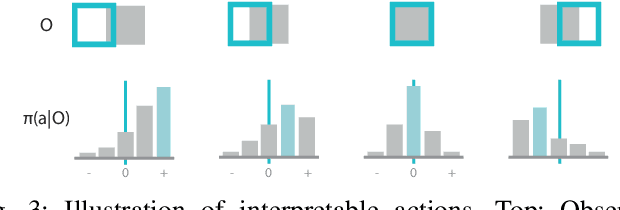
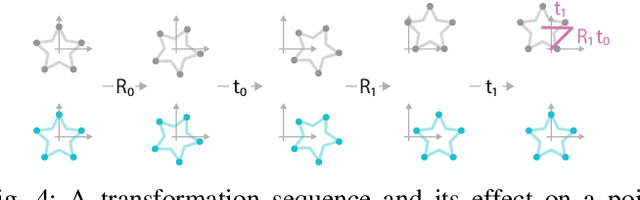
Point cloud registration is a common step in many 3D computer vision tasks such as object pose estimation, where a 3D model is aligned to an observation. Classical registration methods generalize well to novel domains but fail when given a noisy observation or a bad initialization. Learning-based methods, in contrast, are more robust but lack in generalization capacity. We propose to consider iterative point cloud registration as a reinforcement learning task and, to this end, present a novel registration agent (ReAgent). We employ imitation learning to initialize its discrete registration policy based on a steady expert policy. Integration with policy optimization, based on our proposed alignment reward, further improves the agent's registration performance. We compare our approach to classical and learning-based registration methods on both ModelNet40 (synthetic) and ScanObjectNN (real data) and show that our ReAgent achieves state-of-the-art accuracy. The lightweight architecture of the agent, moreover, enables reduced inference time as compared to related approaches. In addition, we apply our method to the object pose estimation task on real data (LINEMOD), outperforming state-of-the-art pose refinement approaches.
Sim2Real 3D Object Classification using Spherical Kernel Point Convolution and a Deep Center Voting Scheme
Mar 10, 2021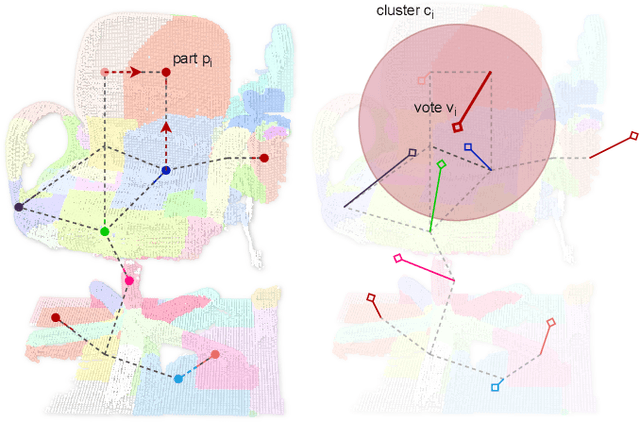
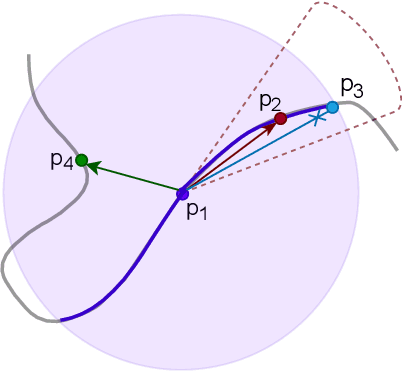
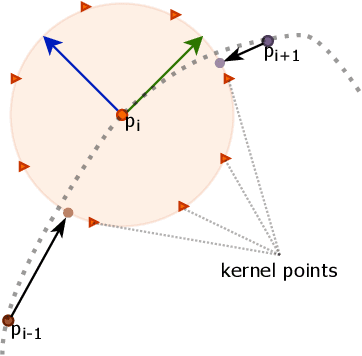
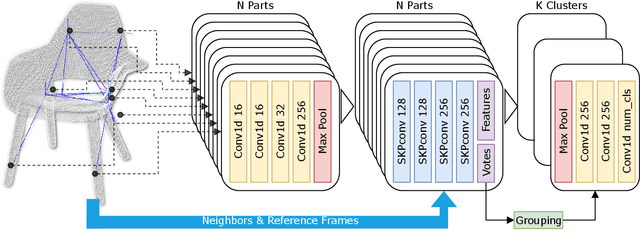
While object semantic understanding is essential for most service robotic tasks, 3D object classification is still an open problem. Learning from artificial 3D models alleviates the cost of annotation necessary to approach this problem, but most methods still struggle with the differences existing between artificial and real 3D data. We conjecture that the cause of those issue is the fact that many methods learn directly from point coordinates, instead of the shape, as the former is hard to center and to scale under variable occlusions reliably. We introduce spherical kernel point convolutions that directly exploit the object surface, represented as a graph, and a voting scheme to limit the impact of poor segmentation on the classification results. Our proposed approach improves upon state-of-the-art methods by up to 36% when transferring from artificial objects to real objects.
PyraPose: Feature Pyramids for Fast and Accurate Object Pose Estimation under Domain Shift
Oct 30, 2020



Object pose estimation enables robots to understand and interact with their environments. Training with synthetic data is necessary in order to adapt to novel situations. Unfortunately, pose estimation under domain shift, i.e., training on synthetic data and testing in the real world, is challenging. Deep learning-based approaches currently perform best when using encoder-decoder networks but typically do not generalize to new scenarios with different scene characteristics. We argue that patch-based approaches, instead of encoder-decoder networks, are more suited for synthetic-to-real transfer because local to global object information is better represented. To that end, we present a novel approach based on a specialized feature pyramid network to compute multi-scale features for creating pose hypotheses on different feature map resolutions in parallel. Our single-shot pose estimation approach is evaluated on multiple standard datasets and outperforms the state of the art by up to 35%. We also perform grasping experiments in the real world to demonstrate the advantage of using synthetic data to generalize to novel environments.
Neural Object Learning for 6D Pose Estimation Using a Few Cluttered Images
May 07, 2020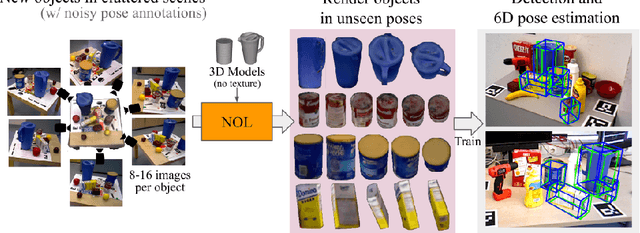
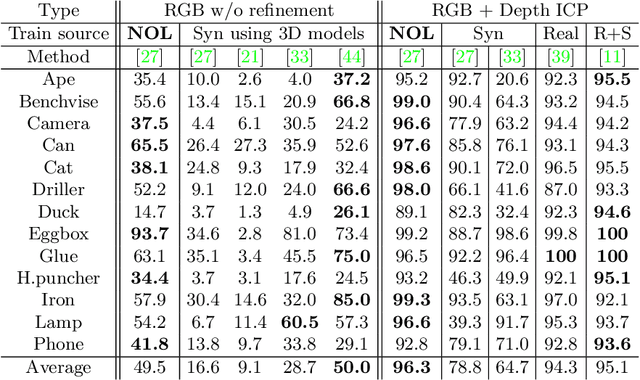
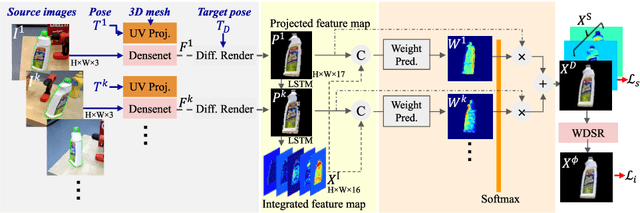

Recent methods for 6D pose estimation of objects assume either textured 3D models or real images that cover the entire range of target poses. However, it is difficult to obtain textured 3D models and annotate the poses of objects in real scenarios. This paper proposes a method, Neural Object Learning (NOL), that creates synthetic images of objects in arbitrary poses by combining only a few observations from cluttered images. A novel refinement step is proposed to align inaccurate poses of objects in source images, which results in better quality images. Evaluations performed on two public datasets show that the rendered images created by NOL lead to state-of-the-art performance in comparison to methods that use 10 times the number of real images. Evaluations on our new dataset show multiple objects can be trained and recognized simultaneously using a sequence of a fixed scene.
DGCM-Net: Dense Geometrical Correspondence Matching Network for Incremental Experience-based Robotic Grasping
Jan 15, 2020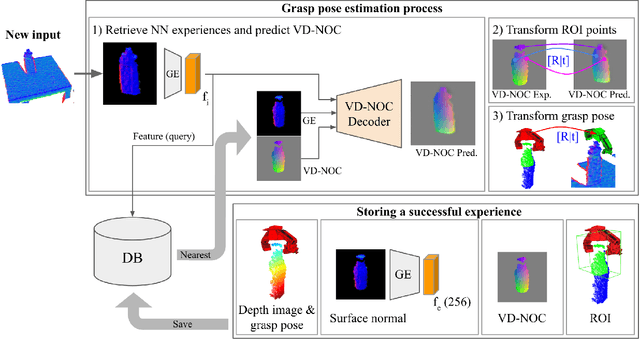



This article presents a method for grasping novel objects by learning from experience. Successful attempts are remembered and then used to guide future grasps such that more reliable grasping is achieved over time. To generalise the learned experience to unseen objects, we introduce the dense geometric correspondence matching network (DGCM-Net). This applies metric learning to encode objects with similar geometry nearby in feature space. Retrieving relevant experience for an unseen object is thus a nearest neighbour search with the encoded feature maps. DGCM-Net also reconstructs 3D-3D correspondences using the view-dependent normalised object coordinate space to transform grasp configurations from retrieved samples to unseen objects. In comparison to baseline methods, our approach achieves an equivalent grasp success rate. However, the baselines are significantly improved when fusing the knowledge from experience with their grasp proposal strategy. Offline experiments with a grasping dataset highlight the capability to generalise within and between object classes as well as to improve success rate over time from increasing experience. Lastly, by learning task-relevant grasps, our approach can prioritise grasps that enable the functional use of objects.
Addressing the Sim2Real Gap in Robotic 3D Object Classification
Oct 28, 2019
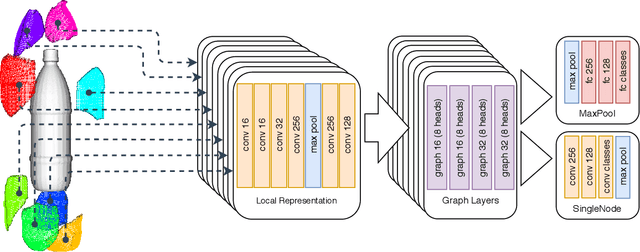

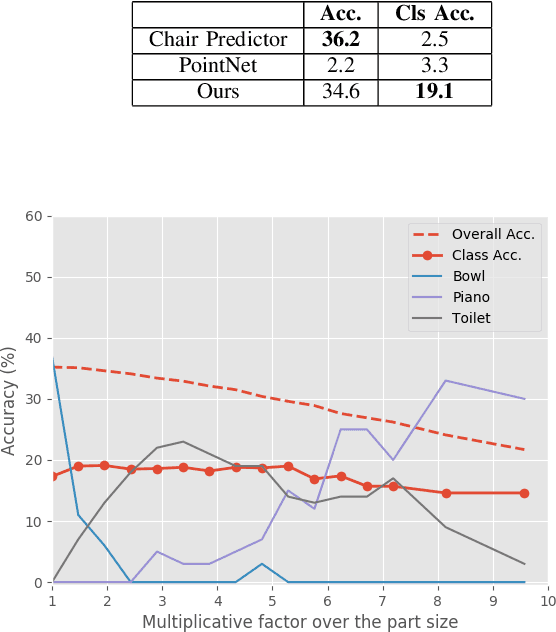
Object classification with 3D data is an essential component of any scene understanding method. It has gained significant interest in a variety of communities, most notably in robotics and computer graphics. While the advent of deep learning has progressed the field of 3D object classification, most work using this data type are solely evaluated on CAD model datasets. Consequently, current work does not address the discrepancies existing between real and artificial data. In this work, we examine this gap in a robotic context by specifically addressing the problem of classification when transferring from artificial CAD models to real reconstructed objects. This is performed by training on ModelNet (CAD models) and evaluating on ScanNet (reconstructed objects). We show that standard methods do not perform well in this task. We thus introduce a method that carefully samples object parts that are reproducible under various transformations and hence robust. Using graph convolution to classify the composed graph of parts, our method significantly improves upon the baseline.