 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Object Learning for 6D Pose Estimation Using a Few Cluttered Images
May 07, 2020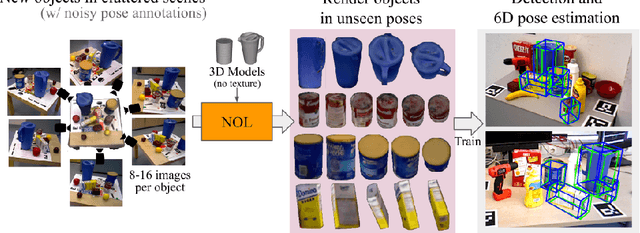
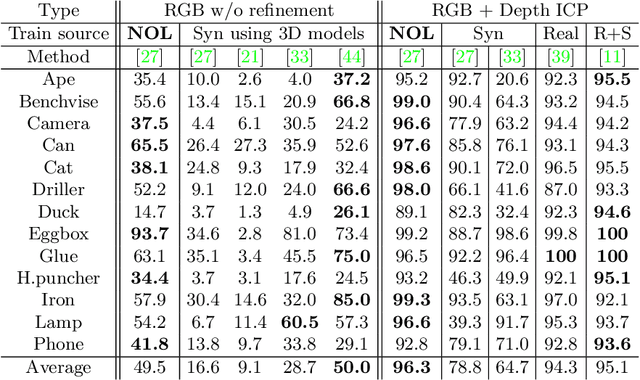
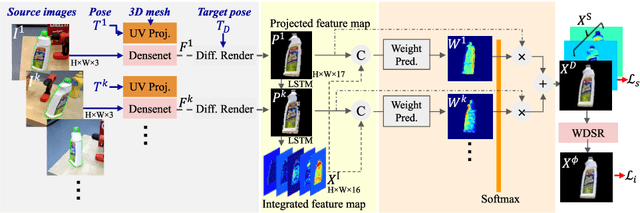

Recent methods for 6D pose estimation of objects assume either textured 3D models or real images that cover the entire range of target poses. However, it is difficult to obtain textured 3D models and annotate the poses of objects in real scenarios. This paper proposes a method, Neural Object Learning (NOL), that creates synthetic images of objects in arbitrary poses by combining only a few observations from cluttered images. A novel refinement step is proposed to align inaccurate poses of objects in source images, which results in better quality images. Evaluations performed on two public datasets show that the rendered images created by NOL lead to state-of-the-art performance in comparison to methods that use 10 times the number of real images. Evaluations on our new dataset show multiple objects can be trained and recognized simultaneously using a sequence of a fixed scene.
Unsupervised Domain Adaptation through Inter-modal Rotation for RGB-D Object Recognition
Apr 21, 2020
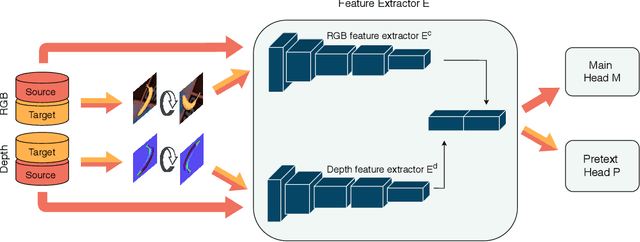


Unsupervised Domain Adaptation (DA) exploits the supervision of a label-rich source dataset to make predictions on an unlabeled target dataset by aligning the two data distributions. In robotics, DA is used to take advantage of automatically generated synthetic data, that come with "free" annotation, to make effective predictions on real data. However, existing DA methods are not designed to cope with the multi-modal nature of RGB-D data, which are widely used in robotic vision. We propose a novel RGB-D DA method that reduces the synthetic-to-real domain shift by exploiting the inter-modal relation between the RGB and depth image. Our method consists of training a convolutional neural network to solve, in addition to the main recognition task, the pretext task of predicting the relative rotation between the RGB and depth image. To evaluate our method and encourage further research in this area, we define two benchmark datasets for object categorization and instance recognition. With extensive experiments, we show the benefits of leveraging the inter-modal relations for RGB-D DA.
DGCM-Net: Dense Geometrical Correspondence Matching Network for Incremental Experience-based Robotic Grasping
Jan 15, 2020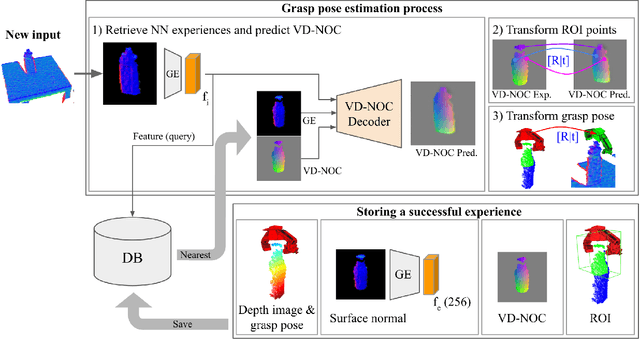



This article presents a method for grasping novel objects by learning from experience. Successful attempts are remembered and then used to guide future grasps such that more reliable grasping is achieved over time. To generalise the learned experience to unseen objects, we introduce the dense geometric correspondence matching network (DGCM-Net). This applies metric learning to encode objects with similar geometry nearby in feature space. Retrieving relevant experience for an unseen object is thus a nearest neighbour search with the encoded feature maps. DGCM-Net also reconstructs 3D-3D correspondences using the view-dependent normalised object coordinate space to transform grasp configurations from retrieved samples to unseen objects. In comparison to baseline methods, our approach achieves an equivalent grasp success rate. However, the baselines are significantly improved when fusing the knowledge from experience with their grasp proposal strategy. Offline experiments with a grasping dataset highlight the capability to generalise within and between object classes as well as to improve success rate over time from increasing experience. Lastly, by learning task-relevant grasps, our approach can prioritise grasps that enable the functional use of objects.
Pix2Pose: Pixel-Wise Coordinate Regression of Objects for 6D Pose Estimation
Aug 20, 2019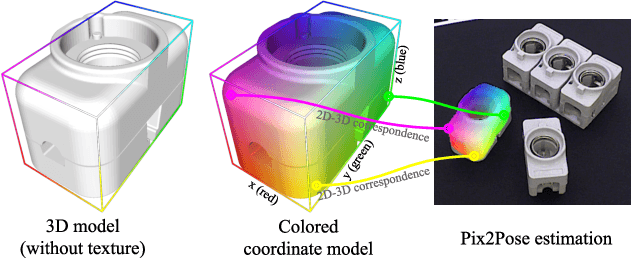
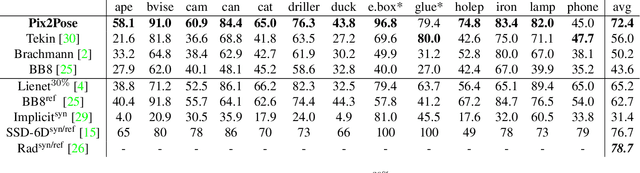
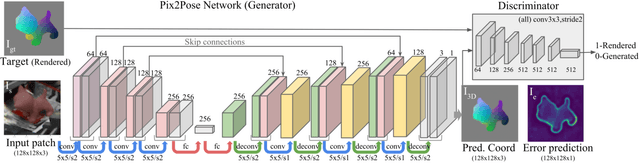
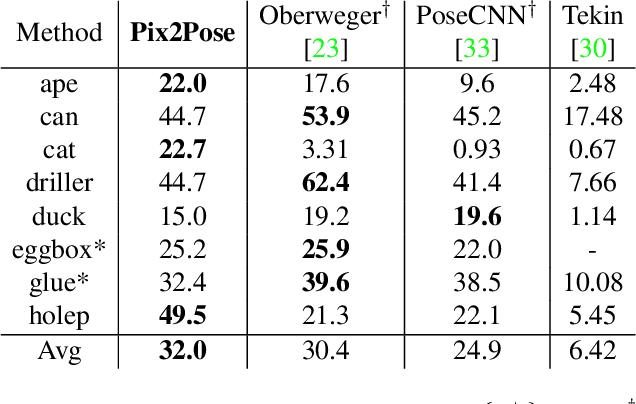
Estimating the 6D pose of objects using only RGB images remains challenging because of problems such as occlusion and symmetries. It is also difficult to construct 3D models with precise texture without expert knowledge or specialized scanning devices. To address these problems, we propose a novel pose estimation method, Pix2Pose, that predicts the 3D coordinates of each object pixel without textured models. An auto-encoder architecture is designed to estimate the 3D coordinates and expected errors per pixel. These pixel-wise predictions are then used in multiple stages to form 2D-3D correspondences to directly compute poses with the PnP algorithm with RANSAC iterations. Our method is robust to occlusion by leveraging recent achievements in generative adversarial training to precisely recover occluded parts. Furthermore, a novel loss function, the transformer loss, is proposed to handle symmetric objects by guiding predictions to the closest symmetric pose. Evaluations on three different benchmark datasets containing symmetric and occluded objects show our method outperforms the state of the art using only RGB images.