 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Image Rotation for Open Set Domain Adaptation
Jul 24, 2020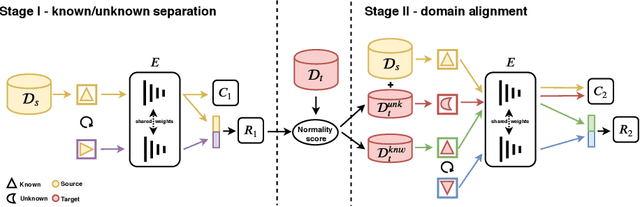

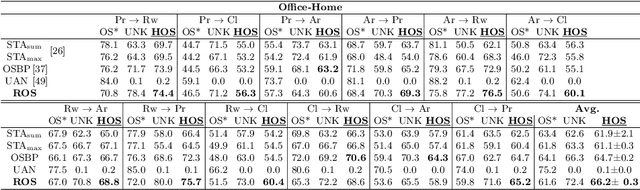

Open Set Domain Adaptation (OSDA) bridges the domain gap between a labeled source domain and an unlabeled target domain, while also rejecting target classes that are not present in the source. To avoid negative transfer, OSDA can be tackled by first separating the known/unknown target samples and then aligning known target samples with the source data. We propose a novel method to addresses both these problems using the self-supervised task of rotation recognition. Moreover, we assess the performance with a new open set metric that properly balances the contribution of recognizing the known classes and rejecting the unknown samples. Comparative experiments with existing OSDA methods on the standard Office-31 and Office-Home benchmarks show that: (i) our method outperforms its competitors, (ii) reproducibility for this field is a crucial issue to tackle, (iii) our metric provides a reliable tool to allow fair open set evaluation.
Unsupervised Domain Adaptation through Inter-modal Rotation for RGB-D Object Recognition
Apr 21, 2020
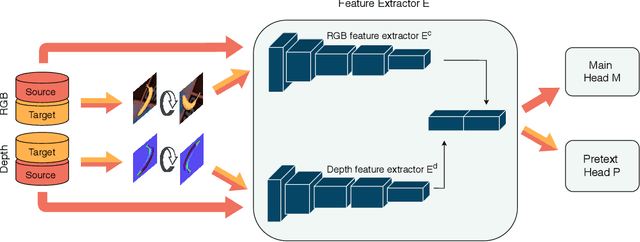


Unsupervised Domain Adaptation (DA) exploits the supervision of a label-rich source dataset to make predictions on an unlabeled target dataset by aligning the two data distributions. In robotics, DA is used to take advantage of automatically generated synthetic data, that come with "free" annotation, to make effective predictions on real data. However, existing DA methods are not designed to cope with the multi-modal nature of RGB-D data, which are widely used in robotic vision. We propose a novel RGB-D DA method that reduces the synthetic-to-real domain shift by exploiting the inter-modal relation between the RGB and depth image. Our method consists of training a convolutional neural network to solve, in addition to the main recognition task, the pretext task of predicting the relative rotation between the RGB and depth image. To evaluate our method and encourage further research in this area, we define two benchmark datasets for object categorization and instance recognition. With extensive experiments, we show the benefits of leveraging the inter-modal relations for RGB-D DA.
A recurrent multi-scale approach to RBG-D Object Recognition
Sep 05, 2018
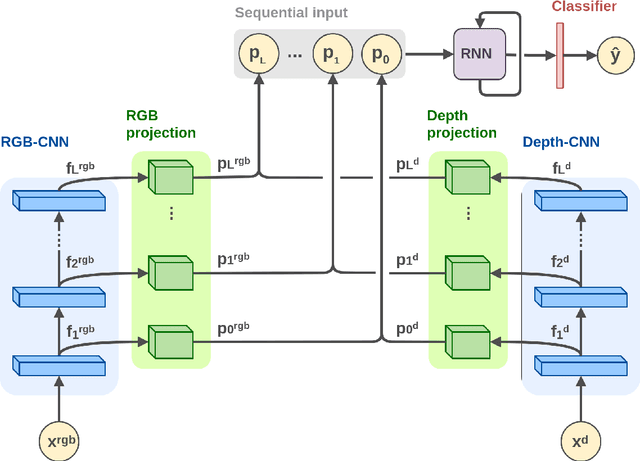
Technological development aims to produce generations of increasingly efficient robots able to perform complex tasks. This requires considerable efforts, from the scientific community, to find new algorithms that solve computer vision problems, such as object recognition. The diffusion of RGB-D cameras directed the study towards the research of new architectures able to exploit the RGB and Depth information. The project that is developed in this thesis concerns the realization of a new end-to-end architecture for the recognition of RGB-D objects called RCFusion. Our method generates compact and highly discriminative multi-modal features by combining complementary RGB and depth information representing different levels of abstraction. We evaluate our method on standard object recognition datasets, RGB-D Object Dataset and JHUIT-50. The experiments performed show that our method outperforms the existing approaches and establishes new state-of-the-art results for both datasets.
Multimodal Deep Domain Adaptation
Jul 31, 2018


Typically a classifier trained on a given dataset (source domain) does not performs well if it is tested on data acquired in a different setting (target domain). This is the problem that domain adaptation (DA) tries to overcome and, while it is a well explored topic in computer vision, it is largely ignored in robotic vision where usually visual classification methods are trained and tested in the same domain. Robots should be able to deal with unknown environments, recognize objects and use them in the correct way, so it is important to explore the domain adaptation scenario also in this context. The goal of the project is to define a benchmark and a protocol for multi-modal domain adaptation that is valuable for the robot vision community. With this purpose some of the state-of-the-art DA methods are selected: Deep Adaptation Network (DAN), Domain Adversarial Training of Neural Network (DANN), Automatic Domain Alignment Layers (AutoDIAL) and Adversarial Discriminative Domain Adaptation (ADDA). Evaluations have been done using different data types: RGB only, depth only and RGB-D over the following datasets, designed for the robotic community: RGB-D Object Dataset (ROD), Web Object Dataset (WOD), Autonomous Robot Indoor Dataset (ARID), Big Berkeley Instance Recognition Dataset (BigBIRD) and Active Vision Dataset. Although progresses have been made on the formulation of effective adaptation algorithms and more realistic object datasets are available, the results obtained show that, training a sufficiently good object classifier, especially in the domain adaptation scenario, is still an unsolved problem. Also the best way to combine depth with RGB informations to improve the performance is a point that needs to be investigated more.
Recurrent Convolutional Fusion for RGB-D Object Recognition
Jul 12, 2018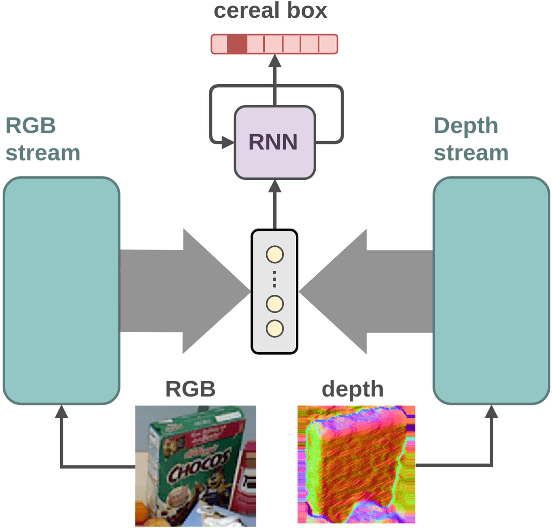
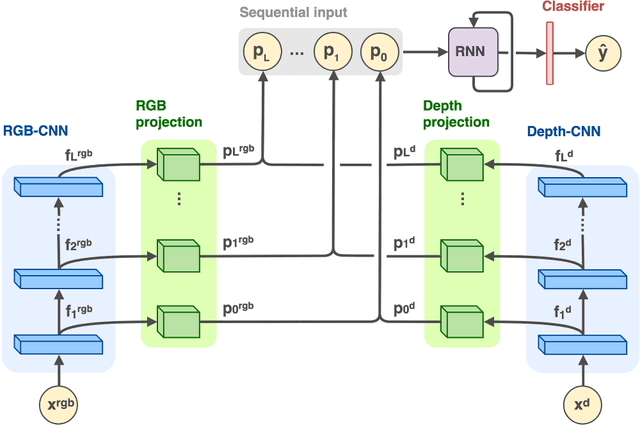
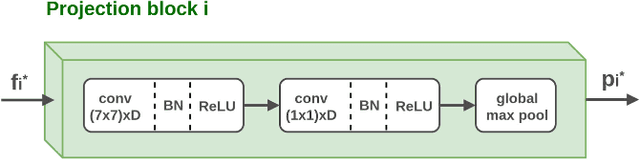
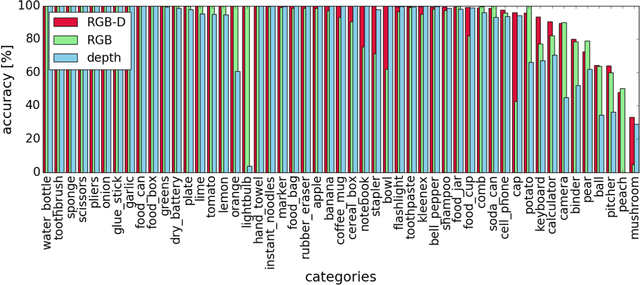
Providing machines with the ability to recognize objects like humans has always been one of the primary goals of machine vision. The introduction of RGB-D cameras has paved the way for a significant leap forward in this direction thanks to the rich information provided by these sensors. However, the machine vision community still lacks an effective method to synergically use the RGB and depth data to improve object recognition. In order to take a step in this direction, we introduce a novel end-to-end architecture for RGB-D object recognition called recurrent convolutional fusion (RCFusion). Our method generates compact and highly discriminative multi-modal features by combining complementary RGB and depth information representing different levels of abstraction. Extensive experiments on two popular datasets, RGB-D Object Dataset and JHUIT-50, show that RCFusion significantly outperforms state-of-the-art approaches in both the object categorization and instance recognition tasks.
Recognizing Objects In-the-wild: Where Do We Stand?
May 22, 2018



The ability to recognize objects is an essential skill for a robotic system acting in human-populated environments. Despite decades of effort from the robotic and vision research communities, robots are still missing good visual perceptual systems, preventing the use of autonomous agents for real-world applications. The progress is slowed down by the lack of a testbed able to accurately represent the world perceived by the robot in-the-wild. In order to fill this gap, we introduce a large-scale, multi-view object dataset collected with an RGB-D camera mounted on a mobile robot. The dataset embeds the challenges faced by a robot in a real-life application and provides a useful tool for validating object recognition algorithms. Besides describing the characteristics of the dataset, the paper evaluates the performance of a collection of well-established deep convolutional networks on the new dataset and analyzes the transferability of deep representations from Web images to robotic data. Despite the promising results obtained with such representations, the experiments demonstrate that object classification with real-life robotic data is far from being solved. Finally, we provide a comparative study to analyze and highlight the open challenges in robot vision, explaining the discrepancies in the performance.