 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Convolutional Fusion for RGB-D Object Recognition
Paper and Code
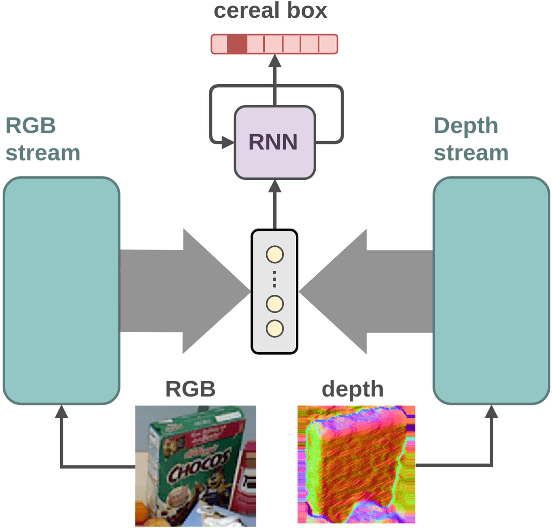
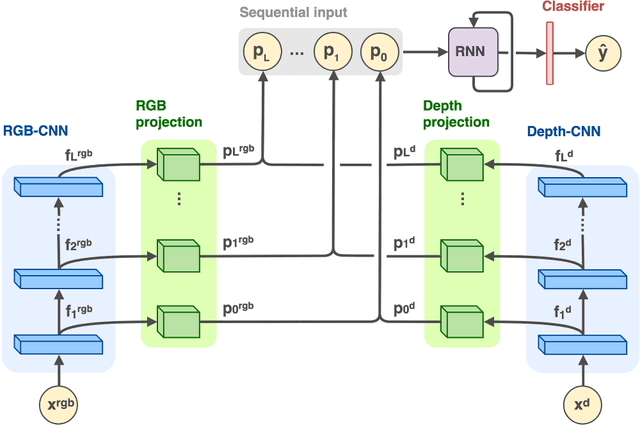
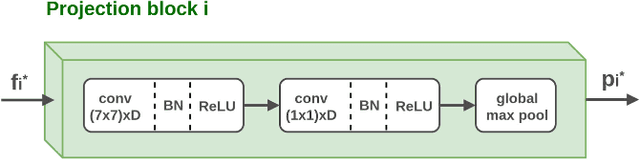
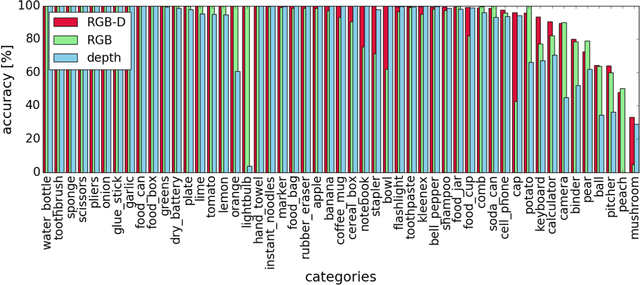
Providing machines with the ability to recognize objects like humans has always been one of the primary goals of machine vision. The introduction of RGB-D cameras has paved the way for a significant leap forward in this direction thanks to the rich information provided by these sensors. However, the machine vision community still lacks an effective method to synergically use the RGB and depth data to improve object recognition. In order to take a step in this direction, we introduce a novel end-to-end architecture for RGB-D object recognition called recurrent convolutional fusion (RCFusion). Our method generates compact and highly discriminative multi-modal features by combining complementary RGB and depth information representing different levels of abstraction. Extensive experiments on two popular datasets, RGB-D Object Dataset and JHUIT-50, show that RCFusion significantly outperforms state-of-the-art approaches in both the object categorization and instance recognition tasks.