 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSCAR: Open-Set CAD Retrieval from a Language Prompt and a Single Image
Jan 12, 20266D object pose estimation plays a crucial role in scene understanding for applications such as robotics and augmented reality. To support the needs of ever-changing object sets in such context, modern zero-shot object pose estimators were developed to not require object-specific training but only rely on CAD models. Such models are hard to obtain once deployed, and a continuously changing and growing set of objects makes it harder to reliably identify the instance model of interest. To address this challenge, we introduce an Open-Set CAD Retrieval from a Language Prompt and a Single Image (OSCAR), a novel training-free method that retrieves a matching object model from an unlabeled 3D object database. During onboarding, OSCAR generates multi-view renderings of database models and annotates them with descriptive captions using an image captioning model. At inference, GroundedSAM detects the queried object in the input image, and multi-modal embeddings are computed for both the Region-of-Interest and the database captions. OSCAR employs a two-stage retrieval: text-based filtering using CLIP identifies candidate models, followed by image-based refinement using DINOv2 to select the most visually similar object. In our experiments we demonstrate that OSCAR outperforms all state-of-the-art methods on the cross-domain 3D model retrieval benchmark MI3DOR. Furthermore, we demonstrate OSCAR's direct applicability in automating object model sourcing for 6D object pose estimation. We propose using the most similar object model for pose estimation if the exact instance is not available and show that OSCAR achieves an average precision of 90.48\% during object retrieval on the YCB-V object dataset. Moreover, we demonstrate that the most similar object model can be utilized for pose estimation using Megapose achieving better results than a reconstruction-based approach.
Sim2Real Transfer for Vision-Based Grasp Verification
May 05, 2025The verification of successful grasps is a crucial aspect of robot manipulation, particularly when handling deformable objects. Traditional methods relying on force and tactile sensors often struggle with deformable and non-rigid objects. In this work, we present a vision-based approach for grasp verification to determine whether the robotic gripper has successfully grasped an object. Our method employs a two-stage architecture; first YOLO-based object detection model to detect and locate the robot's gripper and then a ResNet-based classifier determines the presence of an object. To address the limitations of real-world data capture, we introduce HSR-GraspSynth, a synthetic dataset designed to simulate diverse grasping scenarios. Furthermore, we explore the use of Visual Question Answering capabilities as a zero-shot baseline to which we compare our model. Experimental results demonstrate that our approach achieves high accuracy in real-world environments, with potential for integration into grasping pipelines. Code and datasets are publicly available at https://github.com/pauamargant/HSR-GraspSynth .
LLM-Empowered Embodied Agent for Memory-Augmented Task Planning in Household Robotics
Apr 30, 2025
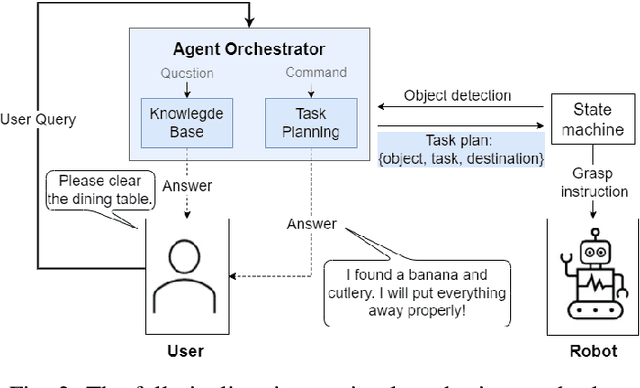
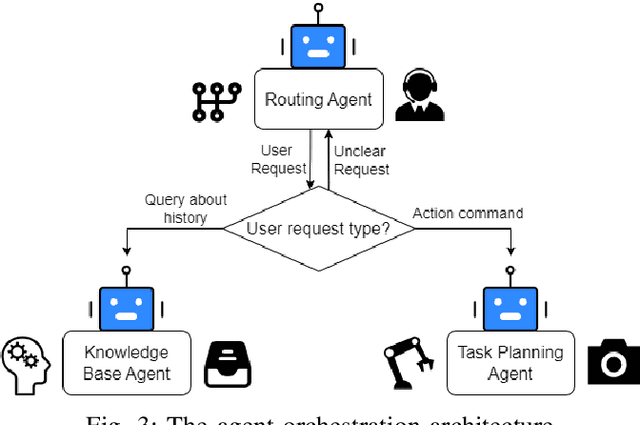
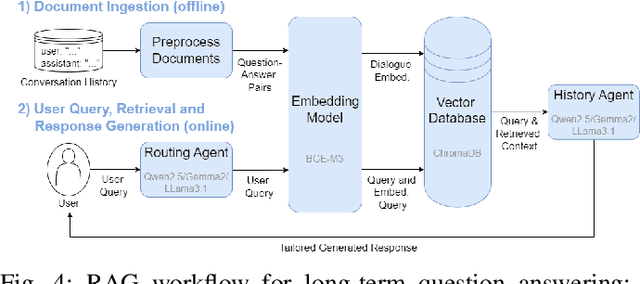
We present an embodied robotic system with an LLM-driven agent-orchestration architecture for autonomous household object management. The system integrates memory-augmented task planning, enabling robots to execute high-level user commands while tracking past actions. It employs three specialized agents: a routing agent, a task planning agent, and a knowledge base agent, each powered by task-specific LLMs. By leveraging in-context learning, our system avoids the need for explicit model training. RAG enables the system to retrieve context from past interactions, enhancing long-term object tracking. A combination of Grounded SAM and LLaMa3.2-Vision provides robust object detection, facilitating semantic scene understanding for task planning. Evaluation across three household scenarios demonstrates high task planning accuracy and an improvement in memory recall due to RAG. Specifically, Qwen2.5 yields best performance for specialized agents, while LLaMA3.1 excels in routing tasks. The source code is available at: https://github.com/marc1198/chat-hsr.
Category-Level and Open-Set Object Pose Estimation for Robotics
Apr 28, 2025Object pose estimation enables a variety of tasks in computer vision and robotics, including scene understanding and robotic grasping. The complexity of a pose estimation task depends on the unknown variables related to the target object. While instance-level methods already excel for opaque and Lambertian objects, category-level and open-set methods, where texture, shape, and size are partially or entirely unknown, still struggle with these basic material properties. Since texture is unknown in these scenarios, it cannot be used for disambiguating object symmetries, another core challenge of 6D object pose estimation. The complexity of estimating 6D poses with such a manifold of unknowns led to various datasets, accuracy metrics, and algorithmic solutions. This paper compares datasets, accuracy metrics, and algorithms for solving 6D pose estimation on the category-level. Based on this comparison, we analyze how to bridge category-level and open-set object pose estimation to reach generalization and provide actionable recommendations.
Enhancing Transparent Object Pose Estimation: A Fusion of GDR-Net and Edge Detection
Feb 17, 2025
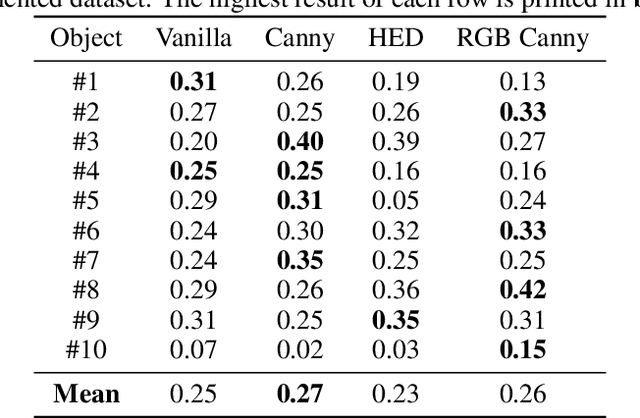
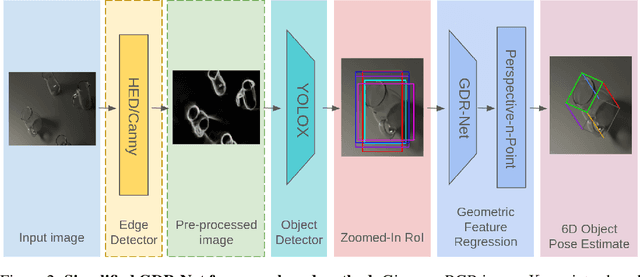
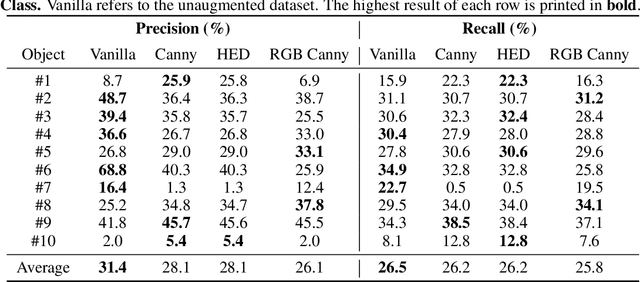
Object pose estimation of transparent objects remains a challenging task in the field of robot vision due to the immense influence of lighting, background, and reflections. However, the edges of clear objects have the highest contrast, which leads to stable and prominent features. We propose a novel approach by incorporating edge detection in a pre-processing step for the tasks of object detection and object pose estimation. We conducted experiments to investigate the effect of edge detectors on transparent objects. We examine the performance of the state-of-the-art 6D object pose estimation pipeline GDR-Net and the object detector YOLOX when applying different edge detectors as pre-processing steps (i.e., Canny edge detection with and without color information, and holistically-nested edges (HED)). We evaluate the physically-based rendered dataset Trans6D-32 K of transparent objects with parameters proposed by the BOP Challenge. Our results indicate that applying edge detection as a pre-processing enhances performance for certain objects.
* accepted at First Austrian Symposium on AI, Robotics, and Vision (AIROV 2024)
Improving 2D-3D Dense Correspondences with Diffusion Models for 6D Object Pose Estimation
Feb 09, 2024



Estimating 2D-3D correspondences between RGB images and 3D space is a fundamental problem in 6D object pose estimation. Recent pose estimators use dense correspondence maps and Point-to-Point algorithms to estimate object poses. The accuracy of pose estimation depends heavily on the quality of the dense correspondence maps and their ability to withstand occlusion, clutter, and challenging material properties. Currently, dense correspondence maps are estimated using image-to-image translation models based on GANs, Autoencoders, or direct regression models. However, recent advancements in image-to-image translation have led to diffusion models being the superior choice when evaluated on benchmarking datasets. In this study, we compare image-to-image translation networks based on GANs and diffusion models for the downstream task of 6D object pose estimation. Our results demonstrate that the diffusion-based image-to-image translation model outperforms the GAN, revealing potential for further improvements in 6D object pose estimation models.
STAR: Shape-focused Texture Agnostic Representations for Improved Object Detection and 6D Pose Estimation
Feb 07, 2024



Recent advances in machine learning have greatly benefited object detection and 6D pose estimation for robotic grasping. However, textureless and metallic objects still pose a significant challenge due to fewer visual cues and the texture bias of CNNs. To address this issue, we propose a texture-agnostic approach that focuses on learning from CAD models and emphasizes object shape features. To achieve a focus on learning shape features, the textures are randomized during the rendering of the training data. By treating the texture as noise, the need for real-world object instances or their final appearance during training data generation is eliminated. The TLESS and ITODD datasets, specifically created for industrial settings in robotics and featuring textureless and metallic objects, were used for evaluation. Texture agnosticity also increases the robustness against image perturbations such as imaging noise, motion blur, and brightness changes, which are common in robotics applications. Code and datasets are publicly available at github.com/hoenigpeter/randomized_texturing.
Challenges for Monocular 6D Object Pose Estimation in Robotics
Jul 22, 2023



Object pose estimation is a core perception task that enables, for example, object grasping and scene understanding. The widely available, inexpensive and high-resolution RGB sensors and CNNs that allow for fast inference based on this modality make monocular approaches especially well suited for robotics applications. We observe that previous surveys on object pose estimation establish the state of the art for varying modalities, single- and multi-view settings, and datasets and metrics that consider a multitude of applications. We argue, however, that those works' broad scope hinders the identification of open challenges that are specific to monocular approaches and the derivation of promising future challenges for their application in robotics. By providing a unified view on recent publications from both robotics and computer vision, we find that occlusion handling, novel pose representations, and formalizing and improving category-level pose estimation are still fundamental challenges that are highly relevant for robotics. Moreover, to further improve robotic performance, large object sets, novel objects, refractive materials, and uncertainty estimates are central, largely unsolved open challenges. In order to address them, ontological reasoning, deformability handling, scene-level reasoning, realistic datasets, and the ecological footprint of algorithms need to be improved.
Open Challenges for Monocular Single-shot 6D Object Pose Estimation
Feb 23, 2023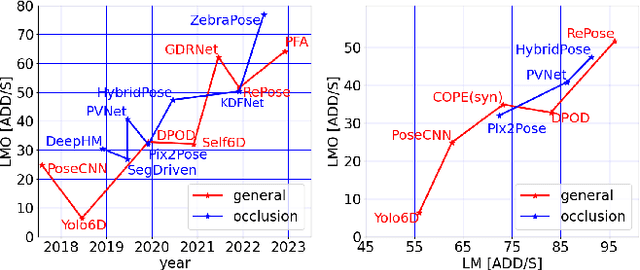
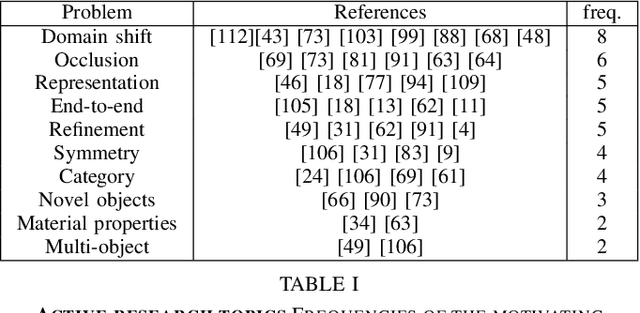
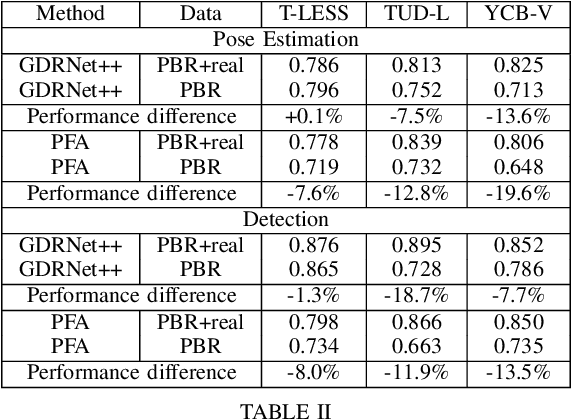
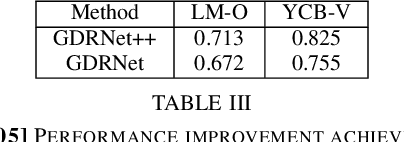
Object pose estimation is a non-trivial task that enables robotic manipulation, bin picking, augmented reality, and scene understanding, to name a few use cases. Monocular object pose estimation gained considerable momentum with the rise of high-performing deep learning-based solutions and is particularly interesting for the community since sensors are inexpensive and inference is fast. Prior works establish the comprehensive state of the art for diverse pose estimation problems. Their broad scopes make it difficult to identify promising future directions. We narrow down the scope to the problem of single-shot monocular 6D object pose estimation, which is commonly used in robotics, and thus are able to identify such trends. By reviewing recent publications in robotics and computer vision, the state of the art is established at the union of both fields. Following that, we identify promising research directions in order to help researchers to formulate relevant research ideas and effectively advance the state of the art. Findings include that methods are sophisticated enough to overcome the domain shift and that occlusion handling is a fundamental challenge. We also highlight problems such as novel object pose estimation and challenging materials handling as central challenges to advance robotics.