 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREACT 2025: the Third Multiple Appropriate Facial Reaction Generation Challenge
May 22, 2025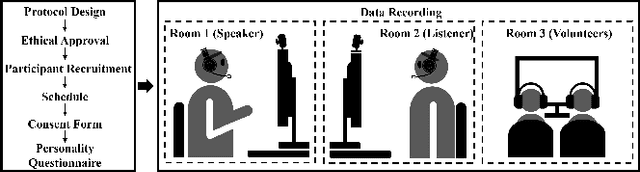

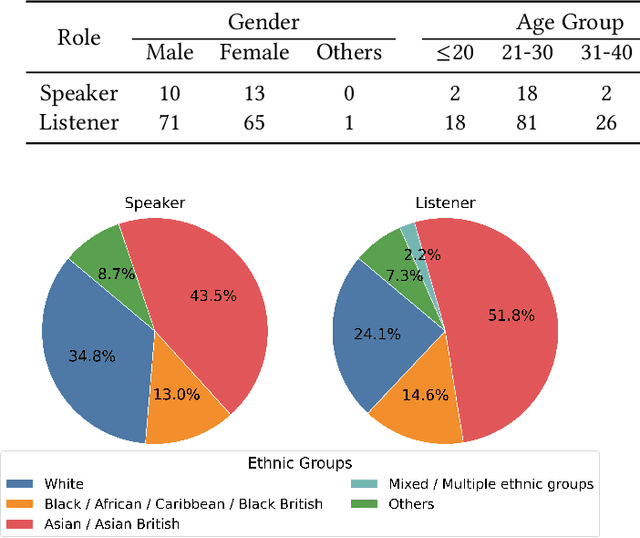
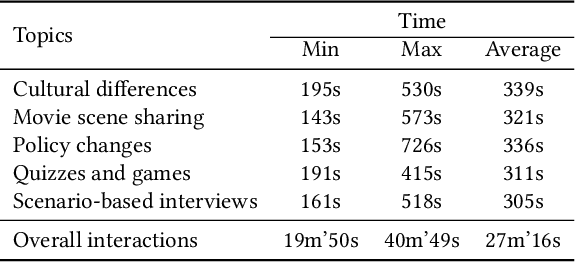
In dyadic interactions, a broad spectrum of human facial reactions might be appropriate for responding to each human speaker behaviour. Following the successful organisation of the REACT 2023 and REACT 2024 challenges, we are proposing the REACT 2025 challenge encouraging the development and benchmarking of Machine Learning (ML) models that can be used to generate multiple appropriate, diverse, realistic and synchronised human-style facial reactions expressed by human listeners in response to an input stimulus (i.e., audio-visual behaviours expressed by their corresponding speakers). As a key of the challenge, we provide challenge participants with the first natural and large-scale multi-modal MAFRG dataset (called MARS) recording 137 human-human dyadic interactions containing a total of 2856 interaction sessions covering five different topics. In addition, this paper also presents the challenge guidelines and the performance of our baselines on the two proposed sub-challenges: Offline MAFRG and Online MAFRG, respectively. The challenge baseline code is publicly available at https://github.com/reactmultimodalchallenge/baseline_react2025
DISCOVER: A Data-driven Interactive System for Comprehensive Observation, Visualization, and ExploRation of Human Behaviour
Jul 18, 2024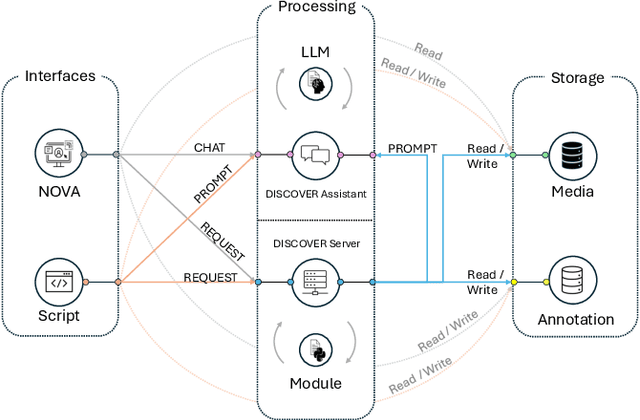
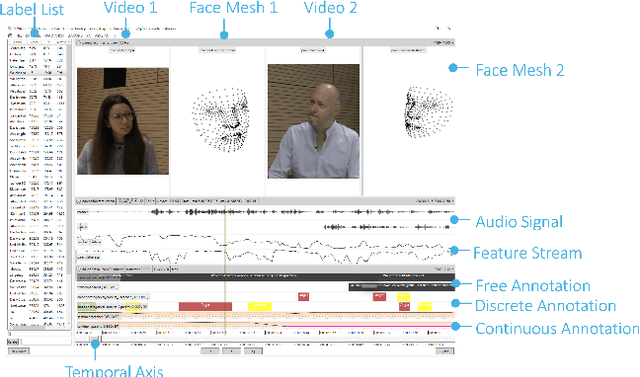
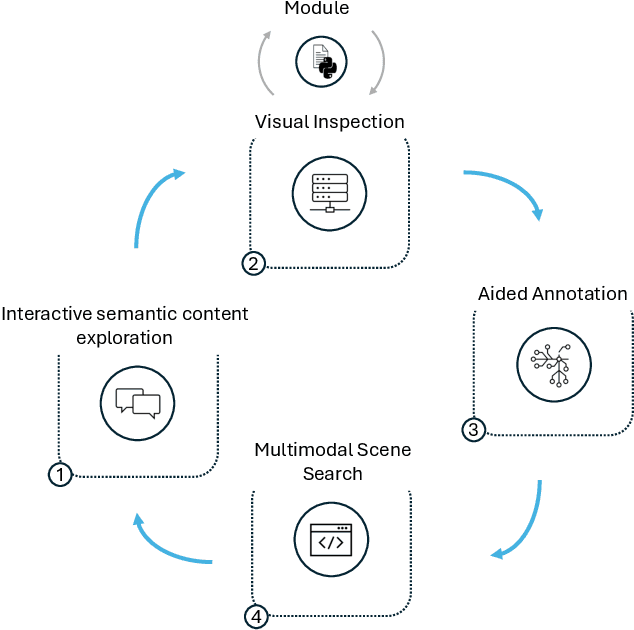
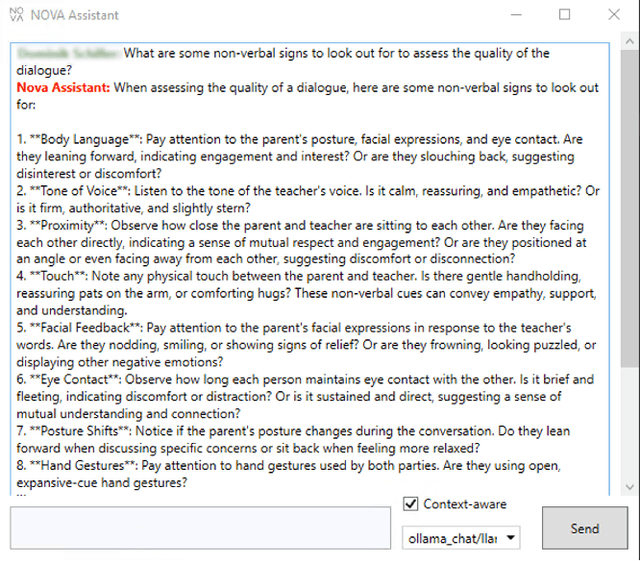
Understanding human behavior is a fundamental goal of social sciences, yet its analysis presents significant challenges. Conventional methodologies employed for the study of behavior, characterized by labor-intensive data collection processes and intricate analyses, frequently hinder comprehensive exploration due to their time and resource demands. In response to these challenges, computational models have proven to be promising tools that help researchers analyze large amounts of data by automatically identifying important behavioral indicators, such as social signals. However, the widespread adoption of such state-of-the-art computational models is impeded by their inherent complexity and the substantial computational resources necessary to run them, thereby constraining accessibility for researchers without technical expertise and adequate equipment. To address these barriers, we introduce DISCOVER -- a modular and flexible, yet user-friendly software framework specifically developed to streamline computational-driven data exploration for human behavior analysis. Our primary objective is to democratize access to advanced computational methodologies, thereby enabling researchers across disciplines to engage in detailed behavioral analysis without the need for extensive technical proficiency. In this paper, we demonstrate the capabilities of DISCOVER using four exemplary data exploration workflows that build on each other: Interactive Semantic Content Exploration, Visual Inspection, Aided Annotation, and Multimodal Scene Search. By illustrating these workflows, we aim to emphasize the versatility and accessibility of DISCOVER as a comprehensive framework and propose a set of blueprints that can serve as a general starting point for exploratory data analysis.
REACT 2024: the Second Multiple Appropriate Facial Reaction Generation Challenge
Jan 10, 2024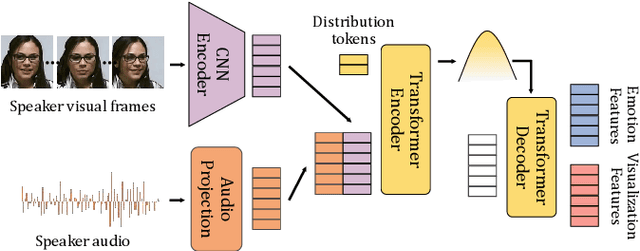
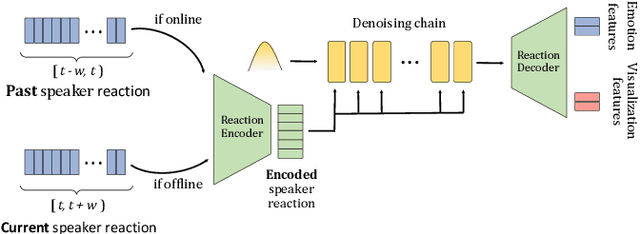
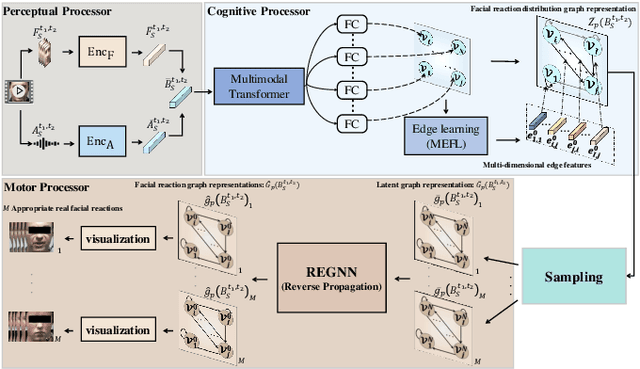
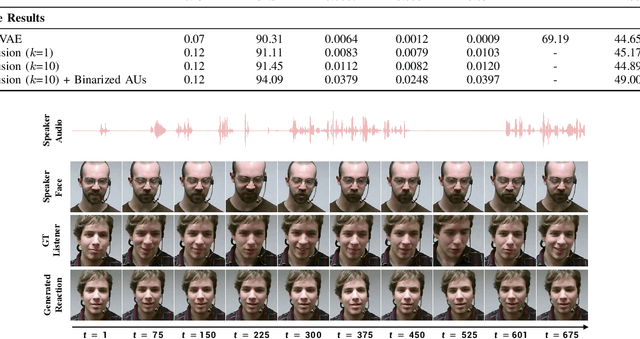
In dyadic interactions, humans communicate their intentions and state of mind using verbal and non-verbal cues, where multiple different facial reactions might be appropriate in response to a specific speaker behaviour. Then, how to develop a machine learning (ML) model that can automatically generate multiple appropriate, diverse, realistic and synchronised human facial reactions from an previously unseen speaker behaviour is a challenging task. Following the successful organisation of the first REACT challenge (REACT 2023), this edition of the challenge (REACT 2024) employs a subset used by the previous challenge, which contains segmented 30-secs dyadic interaction clips originally recorded as part of the NOXI and RECOLA datasets, encouraging participants to develop and benchmark Machine Learning (ML) models that can generate multiple appropriate facial reactions (including facial image sequences and their attributes) given an input conversational partner's stimulus under various dyadic video conference scenarios. This paper presents: (i) the guidelines of the REACT 2024 challenge; (ii) the dataset utilized in the challenge; and (iii) the performance of the baseline systems on the two proposed sub-challenges: Offline Multiple Appropriate Facial Reaction Generation and Online Multiple Appropriate Facial Reaction Generation, respectively. The challenge baseline code is publicly available at https://github.com/reactmultimodalchallenge/baseline_react2024.
MultiMediate'23: Engagement Estimation and Bodily Behaviour Recognition in Social Interactions
Aug 16, 2023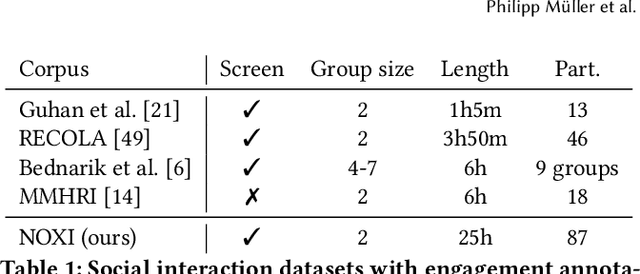
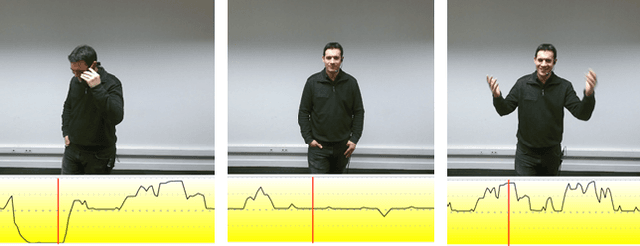

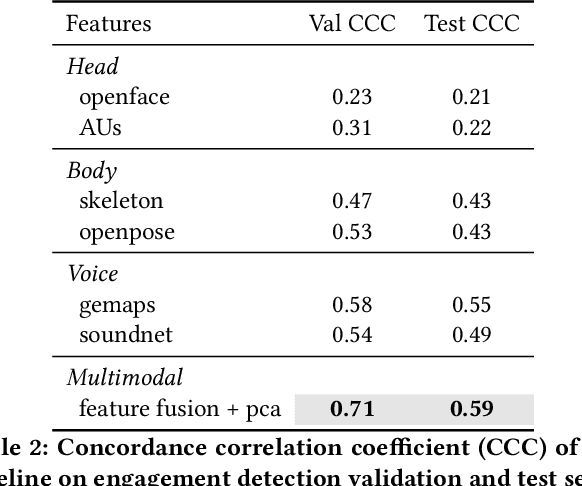
Automatic analysis of human behaviour is a fundamental prerequisite for the creation of machines that can effectively interact with- and support humans in social interactions. In MultiMediate'23, we address two key human social behaviour analysis tasks for the first time in a controlled challenge: engagement estimation and bodily behaviour recognition in social interactions. This paper describes the MultiMediate'23 challenge and presents novel sets of annotations for both tasks. For engagement estimation we collected novel annotations on the NOvice eXpert Interaction (NOXI) database. For bodily behaviour recognition, we annotated test recordings of the MPIIGroupInteraction corpus with the BBSI annotation scheme. In addition, we present baseline results for both challenge tasks.
REACT2023: the first Multi-modal Multiple Appropriate Facial Reaction Generation Challenge
Jun 11, 2023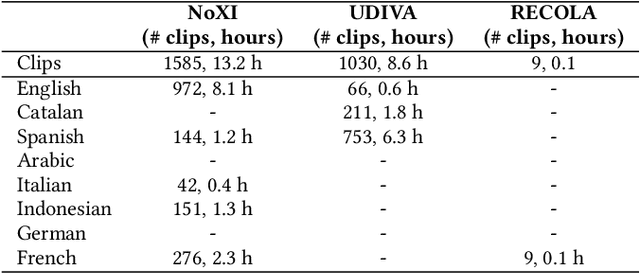
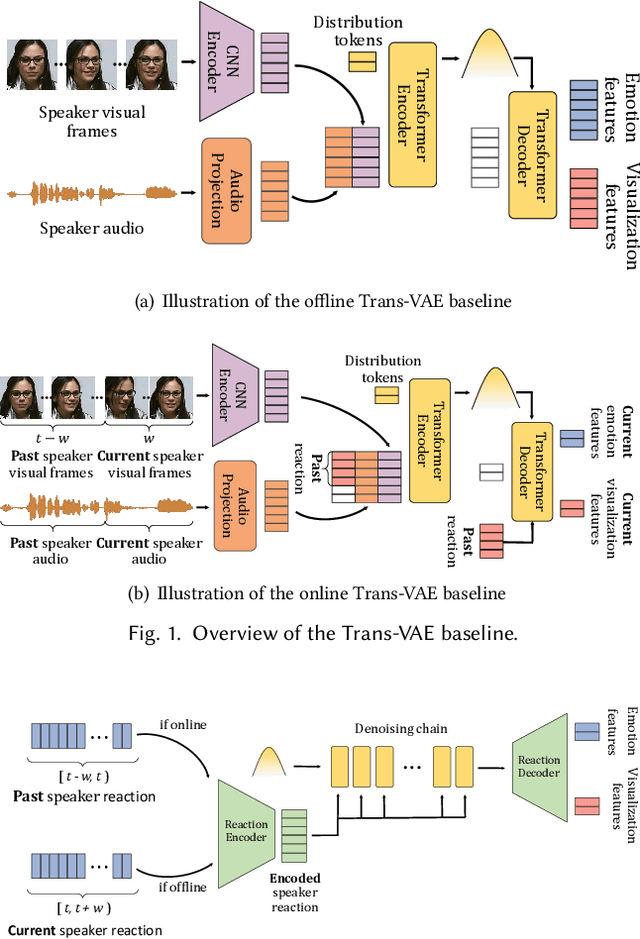
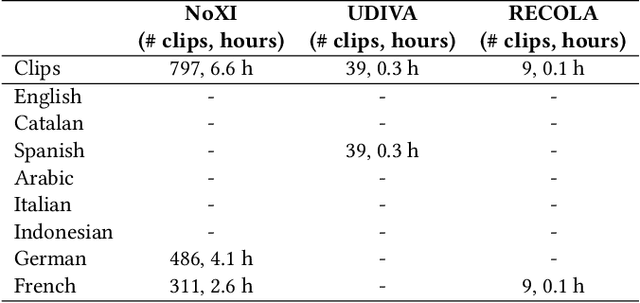
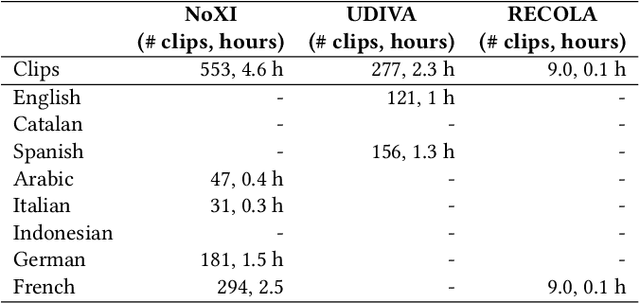
The Multi-modal Multiple Appropriate Facial Reaction Generation Challenge (REACT2023) is the first competition event focused on evaluating multimedia processing and machine learning techniques for generating human-appropriate facial reactions in various dyadic interaction scenarios, with all participants competing strictly under the same conditions. The goal of the challenge is to provide the first benchmark test set for multi-modal information processing and to foster collaboration among the audio, visual, and audio-visual affective computing communities, to compare the relative merits of the approaches to automatic appropriate facial reaction generation under different spontaneous dyadic interaction conditions. This paper presents: (i) novelties, contributions and guidelines of the REACT2023 challenge; (ii) the dataset utilized in the challenge; and (iii) the performance of baseline systems on the two proposed sub-challenges: Offline Multiple Appropriate Facial Reaction Generation and Online Multiple Appropriate Facial Reaction Generation, respectively. The challenge baseline code is publicly available at \url{https://github.com/reactmultimodalchallenge/baseline_react2023}.
ForDigitStress: A multi-modal stress dataset employing a digital job interview scenario
Mar 14, 2023


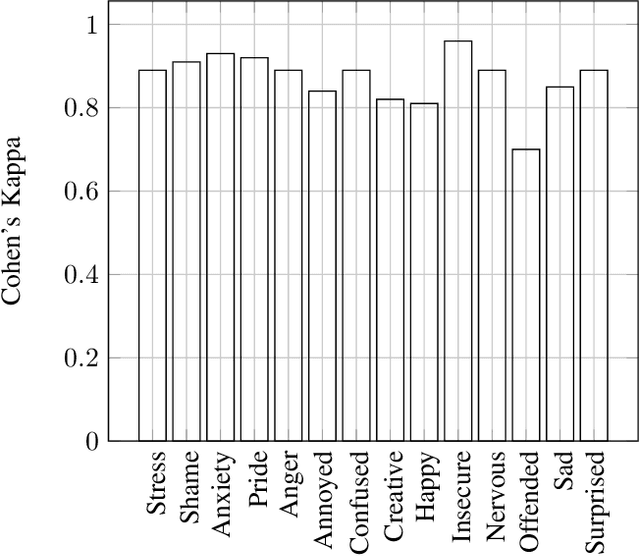
We present a multi-modal stress dataset that uses digital job interviews to induce stress. The dataset provides multi-modal data of 40 participants including audio, video (motion capturing, facial recognition, eye tracking) as well as physiological information (photoplethysmography, electrodermal activity). In addition to that, the dataset contains time-continuous annotations for stress and occurred emotions (e.g. shame, anger, anxiety, surprise). In order to establish a baseline, five different machine learning classifiers (Support Vector Machine, K-Nearest Neighbors, Random Forest, Long-Short-Term Memory Network) have been trained and evaluated on the proposed dataset for a binary stress classification task. The best-performing classifier achieved an accuracy of 88.3% and an F1-score of 87.5%.
"GAN I hire you?" -- A System for Personalized Virtual Job Interview Training
Jun 08, 2022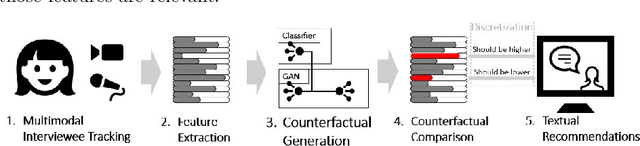
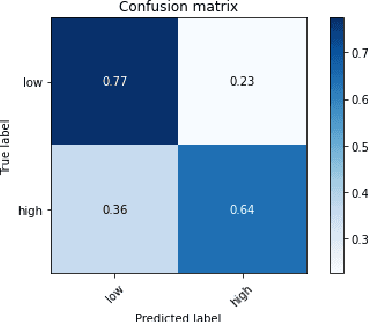

Job interviews are usually high-stakes social situations where professional and behavioral skills are required for a satisfactory outcome. Professional job interview trainers give educative feedback about the shown behavior according to common standards. This feedback can be helpful concerning the improvement of behavioral skills needed for job interviews. A technological approach for generating such feedback might be a playful and low-key starting point for job interview training. Therefore, we extended an interactive virtual job interview training system with a Generative Adversarial Network (GAN)-based approach that first detects behavioral weaknesses and subsequently generates personalized feedback. To evaluate the usefulness of the generated feedback, we conducted a mixed-methods pilot study using mock-ups from the job interview training system. The overall study results indicate that the GAN-based generated behavioral feedback is helpful. Moreover, participants assessed that the feedback would improve their job interview performance.
Applying Cooperative Machine Learning to Speed Up the Annotation of Social Signals in Large Multi-modal Corpora
Feb 07, 2018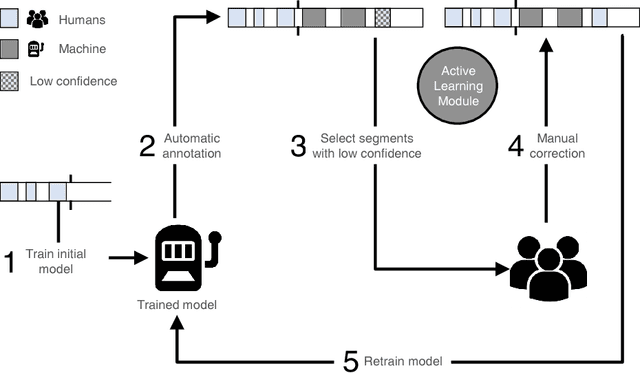

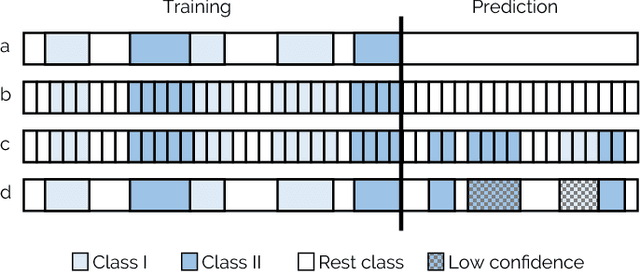
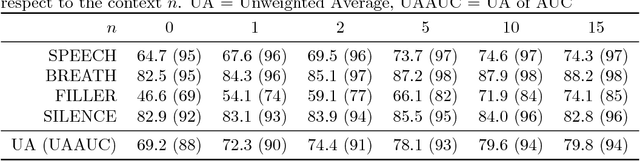
Scientific disciplines, such as Behavioural Psychology, Anthropology and recently Social Signal Processing are concerned with the systematic exploration of human behaviour. A typical work-flow includes the manual annotation (also called coding) of social signals in multi-modal corpora of considerable size. For the involved annotators this defines an exhausting and time-consuming task. In the article at hand we present a novel method and also provide the tools to speed up the coding procedure. To this end, we suggest and evaluate the use of Cooperative Machine Learning (CML) techniques to reduce manual labelling efforts by combining the power of computational capabilities and human intelligence. The proposed CML strategy starts with a small number of labelled instances and concentrates on predicting local parts first. Afterwards, a session-independent classification model is created to finish the remaining parts of the database. Confidence values are computed to guide the manual inspection and correction of the predictions. To bring the proposed approach into application we introduce NOVA - an open-source tool for collaborative and machine-aided annotations. In particular, it gives labellers immediate access to CML strategies and directly provides visual feedback on the results. Our experiments show that the proposed method has the potential to significantly reduce human labelling efforts.
Interpreting social cues to generate credible affective reactions of virtual job interviewers
Feb 25, 2014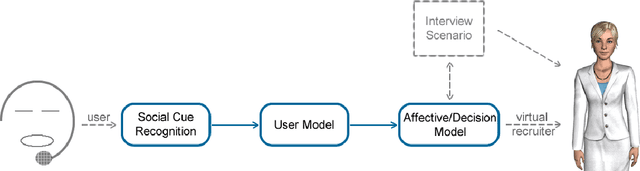
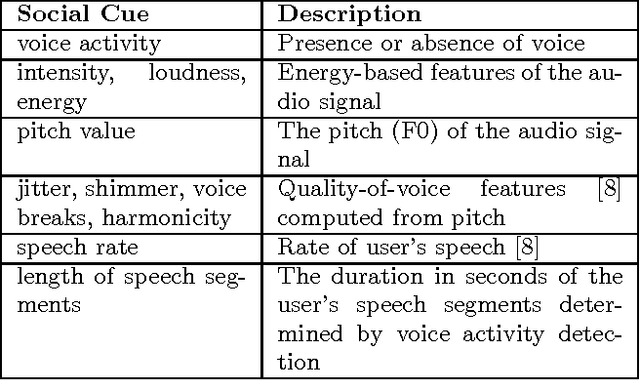
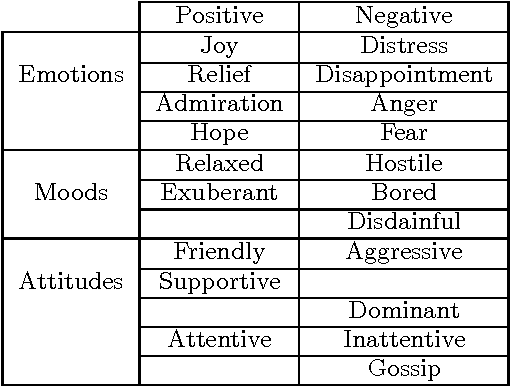
In this paper we describe a mechanism of generating credible affective reactions in a virtual recruiter during an interaction with a user. This is done using communicative performance computation based on the behaviours of the user as detected by a recognition module. The proposed software pipeline is part of the TARDIS system which aims to aid young job seekers in acquiring job interview related social skills. In this context, our system enables the virtual recruiter to realistically adapt and react to the user in real-time.