 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVP: Multimodal Emotion Recognition based on Video and Physiological Signals
Jan 06, 2025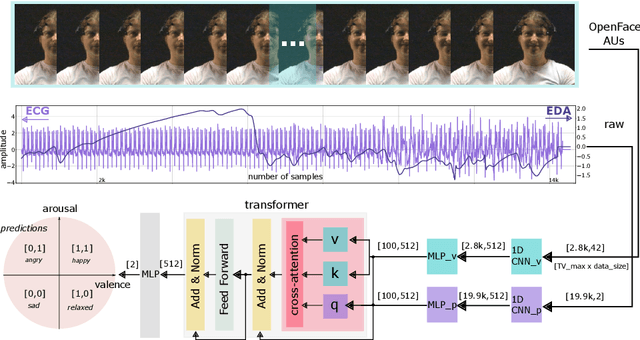
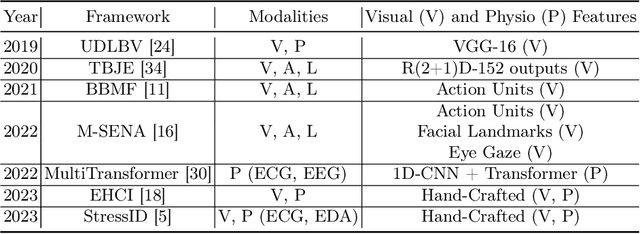
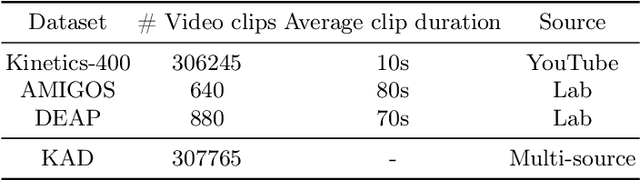
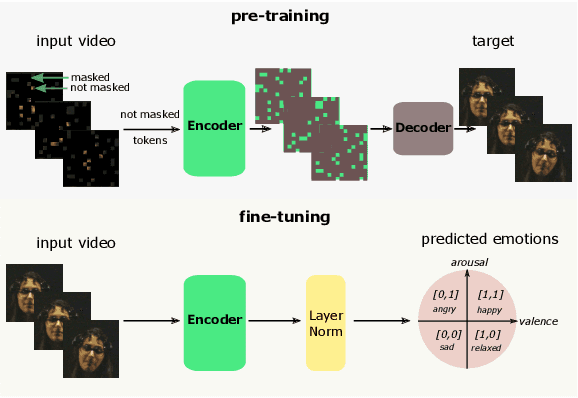
Human emotions entail a complex set of behavioral, physiological and cognitive changes. Current state-of-the-art models fuse the behavioral and physiological components using classic machine learning, rather than recent deep learning techniques. We propose to fill this gap, designing the Multimodal for Video and Physio (MVP) architecture, streamlined to fuse video and physiological signals. Differently then others approaches, MVP exploits the benefits of attention to enable the use of long input sequences (1-2 minutes). We have studied video and physiological backbones for inputting long sequences and evaluated our method with respect to the state-of-the-art. Our results show that MVP outperforms former methods for emotion recognition based on facial videos, EDA, and ECG/PPG.
Are Visual-Language Models Effective in Action Recognition? A Comparative Study
Oct 22, 2024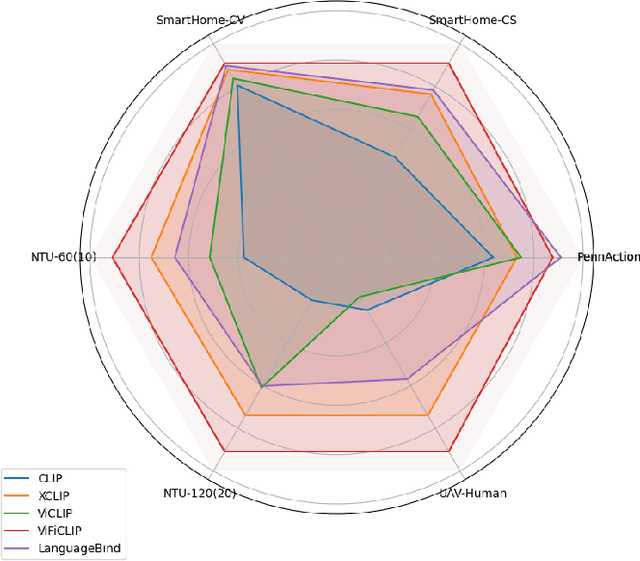

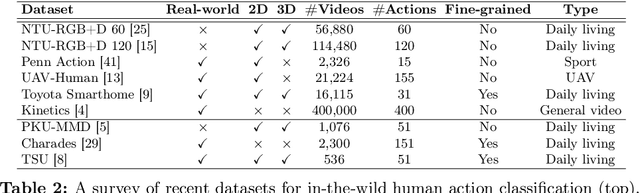
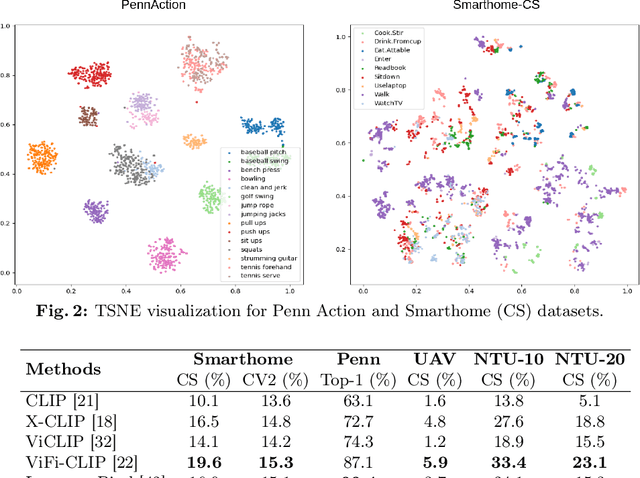
Current vision-language foundation models, such as CLIP, have recently shown significant improvement in performance across various downstream tasks. However, whether such foundation models significantly improve more complex fine-grained action recognition tasks is still an open question. To answer this question and better find out the future research direction on human behavior analysis in-the-wild, this paper provides a large-scale study and insight on current state-of-the-art vision foundation models by comparing their transfer ability onto zero-shot and frame-wise action recognition tasks. Extensive experiments are conducted on recent fine-grained, human-centric action recognition datasets (e.g., Toyota Smarthome, Penn Action, UAV-Human, TSU, Charades) including action classification and segmentation.
What Matters in Autonomous Driving Anomaly Detection: A Weakly Supervised Horizon
Aug 10, 2024Video anomaly detection (VAD) in autonomous driving scenario is an important task, however it involves several challenges due to the ego-centric views and moving camera. Due to this, it remains largely under-explored. While recent developments in weakly-supervised VAD methods have shown remarkable progress in detecting critical real-world anomalies in static camera scenario, the development and validation of such methods are yet to be explored for moving camera VAD. This is mainly due to existing datasets like DoTA not following training pre-conditions of weakly-supervised learning. In this paper, we aim to promote weakly-supervised method development for autonomous driving VAD. We reorganize the DoTA dataset and aim to validate recent powerful weakly-supervised VAD methods on moving camera scenarios. Further, we provide a detailed analysis of what modifications on state-of-the-art methods can significantly improve the detection performance. Towards this, we propose a "feature transformation block" and through experimentation we show that our propositions can empower existing weakly-supervised VAD methods significantly in improving the VAD in autonomous driving. Our codes/dataset/demo will be released at github.com/ut21/WSAD-Driving
MultiMediate'23: Engagement Estimation and Bodily Behaviour Recognition in Social Interactions
Aug 16, 2023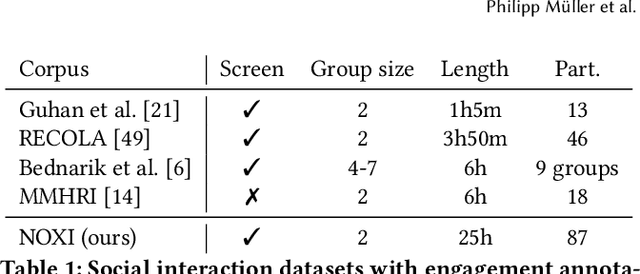
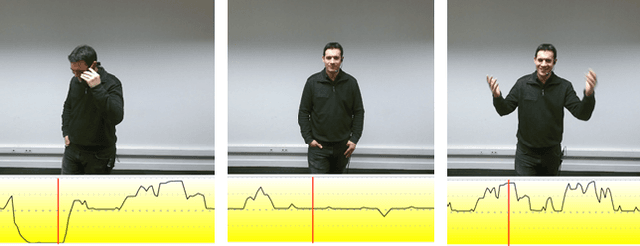

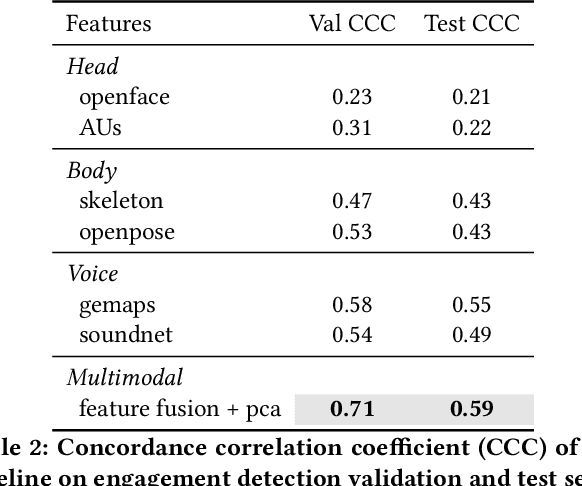
Automatic analysis of human behaviour is a fundamental prerequisite for the creation of machines that can effectively interact with- and support humans in social interactions. In MultiMediate'23, we address two key human social behaviour analysis tasks for the first time in a controlled challenge: engagement estimation and bodily behaviour recognition in social interactions. This paper describes the MultiMediate'23 challenge and presents novel sets of annotations for both tasks. For engagement estimation we collected novel annotations on the NOvice eXpert Interaction (NOXI) database. For bodily behaviour recognition, we annotated test recordings of the MPIIGroupInteraction corpus with the BBSI annotation scheme. In addition, we present baseline results for both challenge tasks.
Multimodal Vision Transformers with Forced Attention for Behavior Analysis
Dec 07, 2022Human behavior understanding requires looking at minute details in the large context of a scene containing multiple input modalities. It is necessary as it allows the design of more human-like machines. While transformer approaches have shown great improvements, they face multiple challenges such as lack of data or background noise. To tackle these, we introduce the Forced Attention (FAt) Transformer which utilize forced attention with a modified backbone for input encoding and a use of additional inputs. In addition to improving the performance on different tasks and inputs, the modification requires less time and memory resources. We provide a model for a generalised feature extraction for tasks concerning social signals and behavior analysis. Our focus is on understanding behavior in videos where people are interacting with each other or talking into the camera which simulates the first person point of view in social interaction. FAt Transformers are applied to two downstream tasks: personality recognition and body language recognition. We achieve state-of-the-art results for Udiva v0.5, First Impressions v2 and MPII Group Interaction datasets. We further provide an extensive ablation study of the proposed architecture.
Bodily Behaviors in Social Interaction: Novel Annotations and State-of-the-Art Evaluation
Jul 26, 2022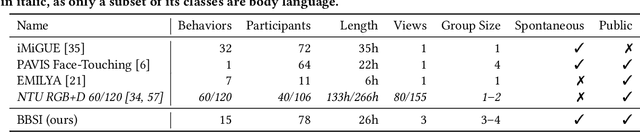
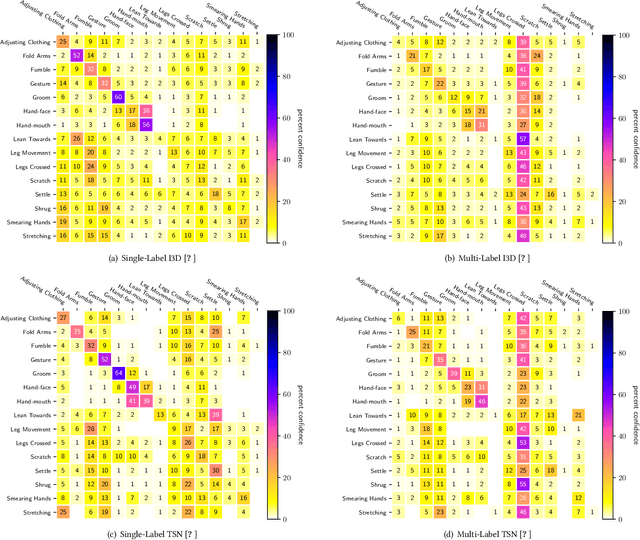
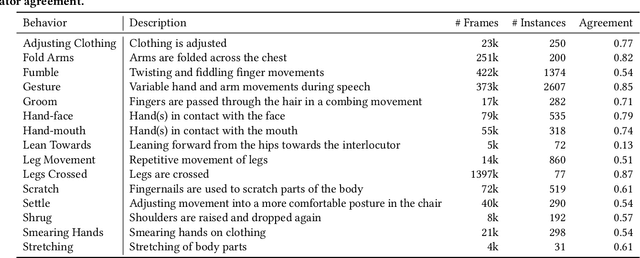
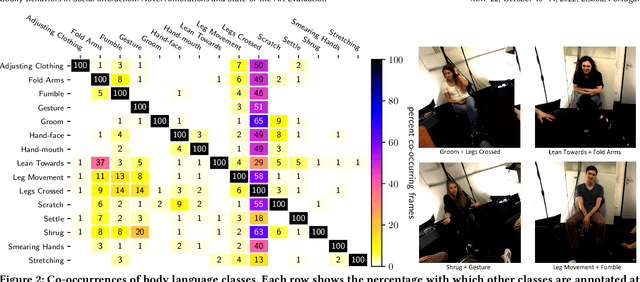
Body language is an eye-catching social signal and its automatic analysis can significantly advance artificial intelligence systems to understand and actively participate in social interactions. While computer vision has made impressive progress in low-level tasks like head and body pose estimation, the detection of more subtle behaviors such as gesturing, grooming, or fumbling is not well explored. In this paper we present BBSI, the first set of annotations of complex Bodily Behaviors embedded in continuous Social Interactions in a group setting. Based on previous work in psychology, we manually annotated 26 hours of spontaneous human behavior in the MPIIGroupInteraction dataset with 15 distinct body language classes. We present comprehensive descriptive statistics on the resulting dataset as well as results of annotation quality evaluations. For automatic detection of these behaviors, we adapt the Pyramid Dilated Attention Network (PDAN), a state-of-the-art approach for human action detection. We perform experiments using four variants of spatial-temporal features as input to PDAN: Two-Stream Inflated 3D CNN, Temporal Segment Networks, Temporal Shift Module and Swin Transformer. Results are promising and indicate a great room for improvement in this difficult task. Representing a key piece in the puzzle towards automatic understanding of social behavior, BBSI is fully available to the research community.
Skeleton Image Representation for 3D Action Recognition based on Tree Structure and Reference Joints
Sep 11, 2019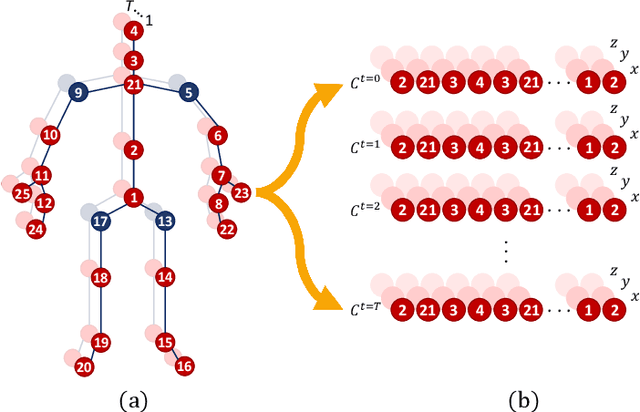
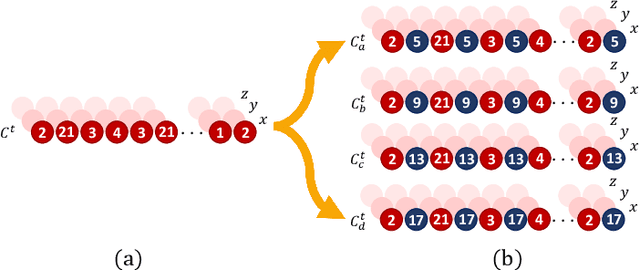
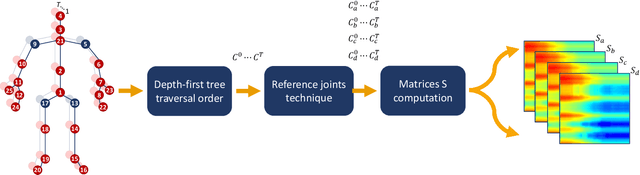
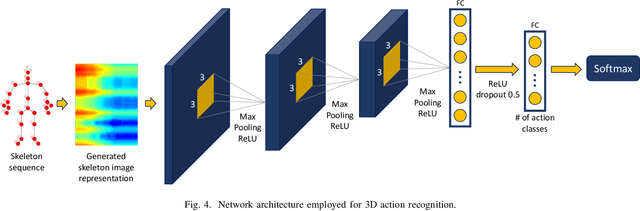
In the last years, the computer vision research community has studied on how to model temporal dynamics in videos to employ 3D human action recognition. To that end, two main baseline approaches have been researched: (i) Recurrent Neural Networks (RNNs) with Long-Short Term Memory (LSTM); and (ii) skeleton image representations used as input to a Convolutional Neural Network (CNN). Although RNN approaches present excellent results, such methods lack the ability to efficiently learn the spatial relations between the skeleton joints. On the other hand, the representations used to feed CNN approaches present the advantage of having the natural ability of learning structural information from 2D arrays (i.e., they learn spatial relations from the skeleton joints). To further improve such representations, we introduce the Tree Structure Reference Joints Image (TSRJI), a novel skeleton image representation to be used as input to CNNs. The proposed representation has the advantage of combining the use of reference joints and a tree structure skeleton. While the former incorporates different spatial relationships between the joints, the latter preserves important spatial relations by traversing a skeleton tree with a depth-first order algorithm. Experimental results demonstrate the effectiveness of the proposed representation for 3D action recognition on two datasets achieving state-of-the-art results on the recent NTU RGB+D~120 dataset.
SkeleMotion: A New Representation of Skeleton Joint Sequences Based on Motion Information for 3D Action Recognition
Jul 30, 2019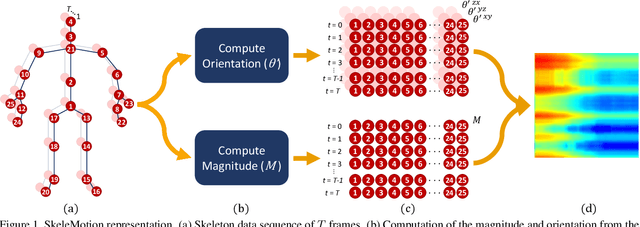
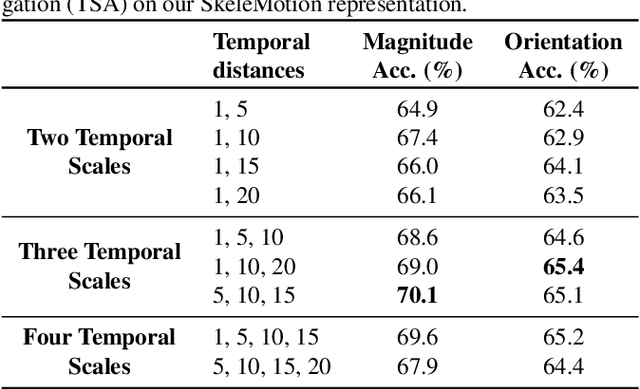
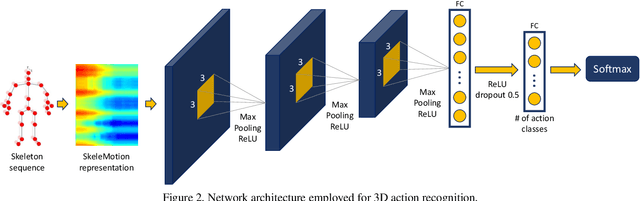
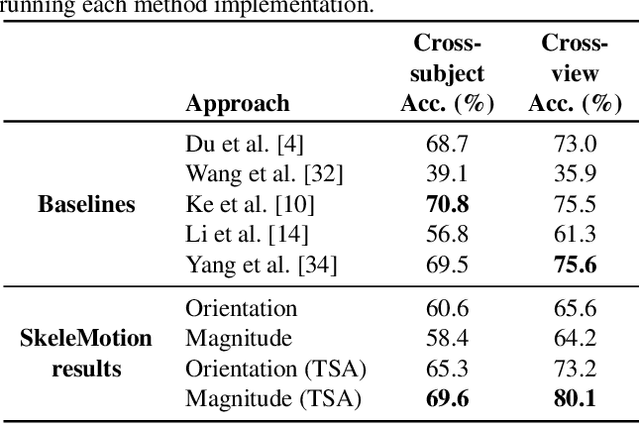
Due to the availability of large-scale skeleton datasets, 3D human action recognition has recently called the attention of computer vision community. Many works have focused on encoding skeleton data as skeleton image representations based on spatial structure of the skeleton joints, in which the temporal dynamics of the sequence is encoded as variations in columns and the spatial structure of each frame is represented as rows of a matrix. To further improve such representations, we introduce a novel skeleton image representation to be used as input of Convolutional Neural Networks (CNNs), named SkeleMotion. The proposed approach encodes the temporal dynamics by explicitly computing the magnitude and orientation values of the skeleton joints. Different temporal scales are employed to compute motion values to aggregate more temporal dynamics to the representation making it able to capture longrange joint interactions involved in actions as well as filtering noisy motion values. Experimental results demonstrate the effectiveness of the proposed representation on 3D action recognition outperforming the state-of-the-art on NTU RGB+D 120 dataset.