 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Visual-Language Models Effective in Action Recognition? A Comparative Study
Paper and Code
Oct 22, 2024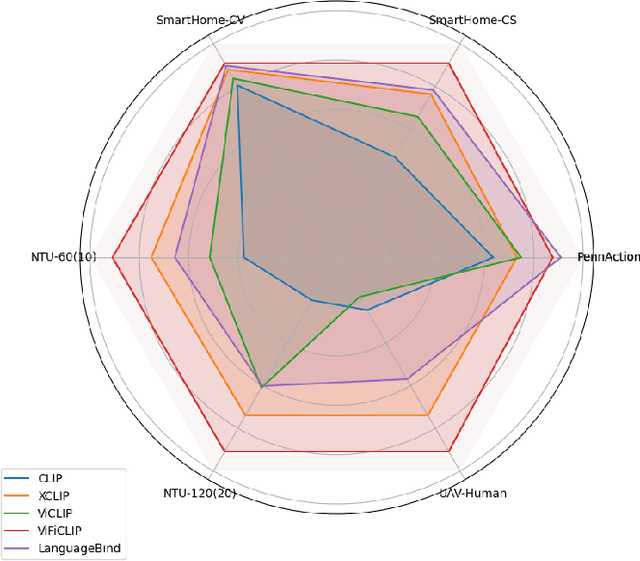

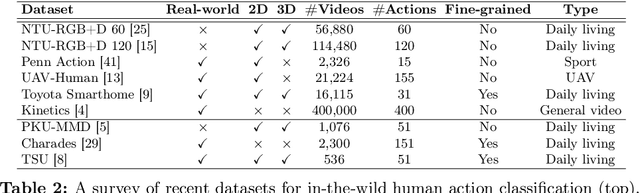
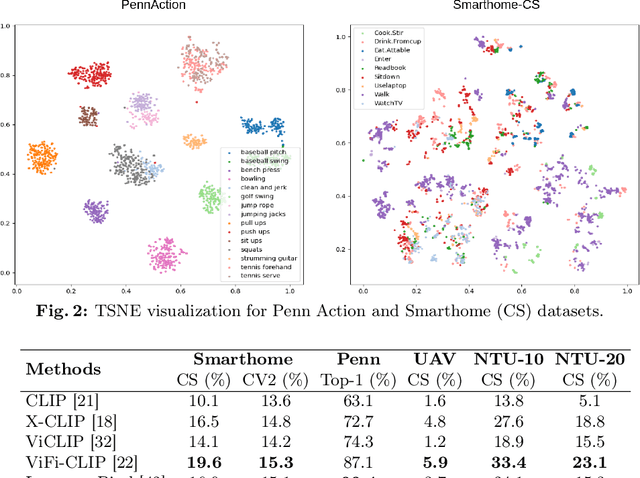
Current vision-language foundation models, such as CLIP, have recently shown significant improvement in performance across various downstream tasks. However, whether such foundation models significantly improve more complex fine-grained action recognition tasks is still an open question. To answer this question and better find out the future research direction on human behavior analysis in-the-wild, this paper provides a large-scale study and insight on current state-of-the-art vision foundation models by comparing their transfer ability onto zero-shot and frame-wise action recognition tasks. Extensive experiments are conducted on recent fine-grained, human-centric action recognition datasets (e.g., Toyota Smarthome, Penn Action, UAV-Human, TSU, Charades) including action classification and segmentation.