 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom SAM to DINOv2: Towards Distilling Foundation Models to Lightweight Baselines for Generalized Polyp Segmentation
Dec 10, 2025Accurate polyp segmentation during colonoscopy is critical for the early detection of colorectal cancer and still remains challenging due to significant size, shape, and color variations, and the camouflaged nature of polyps. While lightweight baseline models such as U-Net, U-Net++, and PraNet offer advantages in terms of easy deployment and low computational cost, they struggle to deal with the above issues, leading to limited segmentation performance. In contrast, large-scale vision foundation models such as SAM, DINOv2, OneFormer, and Mask2Former have exhibited impressive generalization performance across natural image domains. However, their direct transfer to medical imaging tasks (e.g., colonoscopic polyp segmentation) is not straightforward, primarily due to the scarcity of large-scale datasets and lack of domain-specific knowledge. To bridge this gap, we propose a novel distillation framework, Polyp-DiFoM, that transfers the rich representations of foundation models into lightweight segmentation baselines, allowing efficient and accurate deployment in clinical settings. In particular, we infuse semantic priors from the foundation models into canonical architectures such as U-Net and U-Net++ and further perform frequency domain encoding for enhanced distillation, corroborating their generalization capability. Extensive experiments are performed across five benchmark datasets, such as Kvasir-SEG, CVC-ClinicDB, ETIS, ColonDB, and CVC-300. Notably, Polyp-DiFoM consistently outperforms respective baseline models significantly, as well as the state-of-the-art model, with nearly 9 times reduced computation overhead. The code is available at https://github.com/lostinrepo/PolypDiFoM.
Mixture of Experts Guided by Gaussian Splatters Matters: A new Approach to Weakly-Supervised Video Anomaly Detection
Aug 08, 2025Video Anomaly Detection (VAD) is a challenging task due to the variability of anomalous events and the limited availability of labeled data. Under the Weakly-Supervised VAD (WSVAD) paradigm, only video-level labels are provided during training, while predictions are made at the frame level. Although state-of-the-art models perform well on simple anomalies (e.g., explosions), they struggle with complex real-world events (e.g., shoplifting). This difficulty stems from two key issues: (1) the inability of current models to address the diversity of anomaly types, as they process all categories with a shared model, overlooking category-specific features; and (2) the weak supervision signal, which lacks precise temporal information, limiting the ability to capture nuanced anomalous patterns blended with normal events. To address these challenges, we propose Gaussian Splatting-guided Mixture of Experts (GS-MoE), a novel framework that employs a set of expert models, each specialized in capturing specific anomaly types. These experts are guided by a temporal Gaussian splatting loss, enabling the model to leverage temporal consistency and enhance weak supervision. The Gaussian splatting approach encourages a more precise and comprehensive representation of anomalies by focusing on temporal segments most likely to contain abnormal events. The predictions from these specialized experts are integrated through a mixture-of-experts mechanism to model complex relationships across diverse anomaly patterns. Our approach achieves state-of-the-art performance, with a 91.58% AUC on the UCF-Crime dataset, and demonstrates superior results on XD-Violence and MSAD datasets. By leveraging category-specific expertise and temporal guidance, GS-MoE sets a new benchmark for VAD under weak supervision.
Mamba Guided Boundary Prior Matters: A New Perspective for Generalized Polyp Segmentation
Jul 02, 2025Polyp segmentation in colonoscopy images is crucial for early detection and diagnosis of colorectal cancer. However, this task remains a significant challenge due to the substantial variations in polyp shape, size, and color, as well as the high similarity between polyps and surrounding tissues, often compounded by indistinct boundaries. While existing encoder-decoder CNN and transformer-based approaches have shown promising results, they struggle with stable segmentation performance on polyps with weak or blurry boundaries. These methods exhibit limited abilities to distinguish between polyps and non-polyps and capture essential boundary cues. Moreover, their generalizability still falls short of meeting the demands of real-time clinical applications. To address these limitations, we propose SAM-MaGuP, a groundbreaking approach for robust polyp segmentation. By incorporating a boundary distillation module and a 1D-2D Mamba adapter within the Segment Anything Model (SAM), SAM-MaGuP excels at resolving weak boundary challenges and amplifies feature learning through enriched global contextual interactions. Extensive evaluations across five diverse datasets reveal that SAM-MaGuP outperforms state-of-the-art methods, achieving unmatched segmentation accuracy and robustness. Our key innovations, a Mamba-guided boundary prior and a 1D-2D Mamba block, set a new benchmark in the field, pushing the boundaries of polyp segmentation to new heights.
Just Dance with $π$! A Poly-modal Inductor for Weakly-supervised Video Anomaly Detection
May 19, 2025Weakly-supervised methods for video anomaly detection (VAD) are conventionally based merely on RGB spatio-temporal features, which continues to limit their reliability in real-world scenarios. This is due to the fact that RGB-features are not sufficiently distinctive in setting apart categories such as shoplifting from visually similar events. Therefore, towards robust complex real-world VAD, it is essential to augment RGB spatio-temporal features by additional modalities. Motivated by this, we introduce the Poly-modal Induced framework for VAD: "PI-VAD", a novel approach that augments RGB representations by five additional modalities. Specifically, the modalities include sensitivity to fine-grained motion (Pose), three dimensional scene and entity representation (Depth), surrounding objects (Panoptic masks), global motion (optical flow), as well as language cues (VLM). Each modality represents an axis of a polygon, streamlined to add salient cues to RGB. PI-VAD includes two plug-in modules, namely Pseudo-modality Generation module and Cross Modal Induction module, which generate modality-specific prototypical representation and, thereby, induce multi-modal information into RGB cues. These modules operate by performing anomaly-aware auxiliary tasks and necessitate five modality backbones -- only during training. Notably, PI-VAD achieves state-of-the-art accuracy on three prominent VAD datasets encompassing real-world scenarios, without requiring the computational overhead of five modality backbones at inference.
SAM-Mamba: Mamba Guided SAM Architecture for Generalized Zero-Shot Polyp Segmentation
Dec 11, 2024



Polyp segmentation in colonoscopy is crucial for detecting colorectal cancer. However, it is challenging due to variations in the structure, color, and size of polyps, as well as the lack of clear boundaries with surrounding tissues. Traditional segmentation models based on Convolutional Neural Networks (CNNs) struggle to capture detailed patterns and global context, limiting their performance. Vision Transformer (ViT)-based models address some of these issues but have difficulties in capturing local context and lack strong zero-shot generalization. To this end, we propose the Mamba-guided Segment Anything Model (SAM-Mamba) for efficient polyp segmentation. Our approach introduces a Mamba-Prior module in the encoder to bridge the gap between the general pre-trained representation of SAM and polyp-relevant trivial clues. It injects salient cues of polyp images into the SAM image encoder as a domain prior while capturing global dependencies at various scales, leading to more accurate segmentation results. Extensive experiments on five benchmark datasets show that SAM-Mamba outperforms traditional CNN, ViT, and Adapter-based models in both quantitative and qualitative measures. Additionally, SAM-Mamba demonstrates excellent adaptability to unseen datasets, making it highly suitable for real-time clinical use.
What Matters in Autonomous Driving Anomaly Detection: A Weakly Supervised Horizon
Aug 10, 2024Video anomaly detection (VAD) in autonomous driving scenario is an important task, however it involves several challenges due to the ego-centric views and moving camera. Due to this, it remains largely under-explored. While recent developments in weakly-supervised VAD methods have shown remarkable progress in detecting critical real-world anomalies in static camera scenario, the development and validation of such methods are yet to be explored for moving camera VAD. This is mainly due to existing datasets like DoTA not following training pre-conditions of weakly-supervised learning. In this paper, we aim to promote weakly-supervised method development for autonomous driving VAD. We reorganize the DoTA dataset and aim to validate recent powerful weakly-supervised VAD methods on moving camera scenarios. Further, we provide a detailed analysis of what modifications on state-of-the-art methods can significantly improve the detection performance. Towards this, we propose a "feature transformation block" and through experimentation we show that our propositions can empower existing weakly-supervised VAD methods significantly in improving the VAD in autonomous driving. Our codes/dataset/demo will be released at github.com/ut21/WSAD-Driving
Human-Scene Network: A Novel Baseline with Self-rectifying Loss for Weakly supervised Video Anomaly Detection
Jan 19, 2023



Video anomaly detection in surveillance systems with only video-level labels (i.e. weakly-supervised) is challenging. This is due to, (i) the complex integration of human and scene based anomalies comprising of subtle and sharp spatio-temporal cues in real-world scenarios, (ii) non-optimal optimization between normal and anomaly instances under weak supervision. In this paper, we propose a Human-Scene Network to learn discriminative representations by capturing both subtle and strong cues in a dissociative manner. In addition, a self-rectifying loss is also proposed that dynamically computes the pseudo temporal annotations from video-level labels for optimizing the Human-Scene Network effectively. The proposed Human-Scene Network optimized with self-rectifying loss is validated on three publicly available datasets i.e. UCF-Crime, ShanghaiTech and IITB-Corridor, outperforming recently reported state-of-the-art approaches on five out of the six scenarios considered.
Weakly-supervised Joint Anomaly Detection and Classification
Aug 20, 2021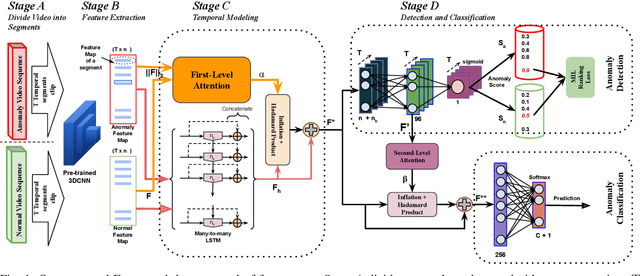
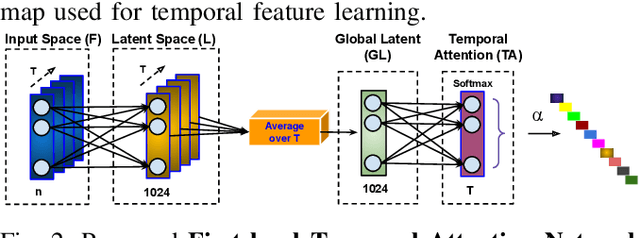
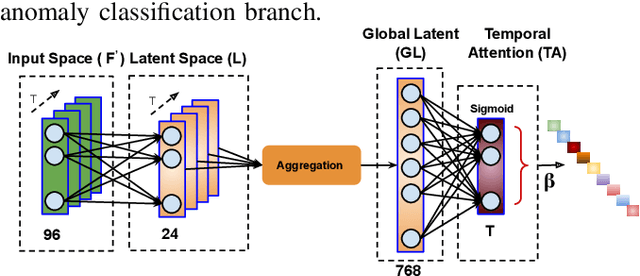

Anomaly activities such as robbery, explosion, accidents, etc. need immediate actions for preventing loss of human life and property in real world surveillance systems. Although the recent automation in surveillance systems are capable of detecting the anomalies, but they still need human efforts for categorizing the anomalies and taking necessary preventive actions. This is due to the lack of methodology performing both anomaly detection and classification for real world scenarios. Thinking of a fully automatized surveillance system, which is capable of both detecting and classifying the anomalies that need immediate actions, a joint anomaly detection and classification method is a pressing need. The task of joint detection and classification of anomalies becomes challenging due to the unavailability of dense annotated videos pertaining to anomalous classes, which is a crucial factor for training modern deep architecture. Furthermore, doing it through manual human effort seems impossible. Thus, we propose a method that jointly handles the anomaly detection and classification in a single framework by adopting a weakly-supervised learning paradigm. In weakly-supervised learning instead of dense temporal annotations, only video-level labels are sufficient for learning. The proposed model is validated on a large-scale publicly available UCF-Crime dataset, achieving state-of-the-art results.