 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-supervised Joint Anomaly Detection and Classification
Aug 20, 2021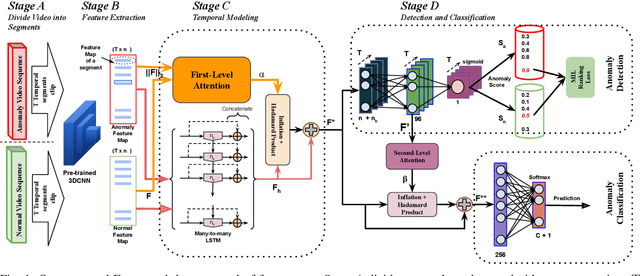
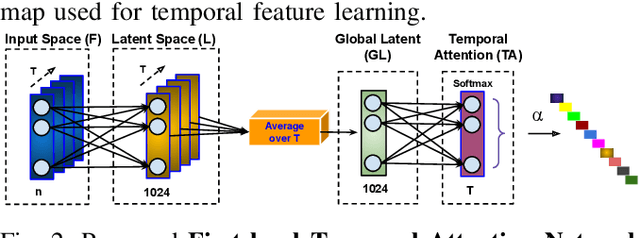
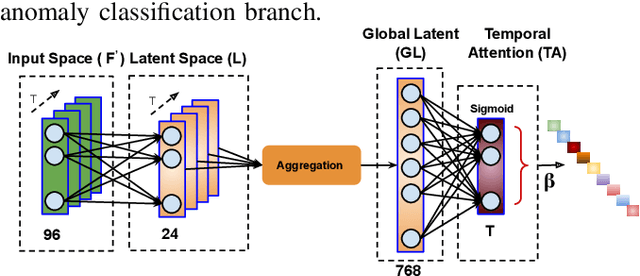

Anomaly activities such as robbery, explosion, accidents, etc. need immediate actions for preventing loss of human life and property in real world surveillance systems. Although the recent automation in surveillance systems are capable of detecting the anomalies, but they still need human efforts for categorizing the anomalies and taking necessary preventive actions. This is due to the lack of methodology performing both anomaly detection and classification for real world scenarios. Thinking of a fully automatized surveillance system, which is capable of both detecting and classifying the anomalies that need immediate actions, a joint anomaly detection and classification method is a pressing need. The task of joint detection and classification of anomalies becomes challenging due to the unavailability of dense annotated videos pertaining to anomalous classes, which is a crucial factor for training modern deep architecture. Furthermore, doing it through manual human effort seems impossible. Thus, we propose a method that jointly handles the anomaly detection and classification in a single framework by adopting a weakly-supervised learning paradigm. In weakly-supervised learning instead of dense temporal annotations, only video-level labels are sufficient for learning. The proposed model is validated on a large-scale publicly available UCF-Crime dataset, achieving state-of-the-art results.
Blind Deblurring using Deep Learning: A Survey
Jul 23, 2019
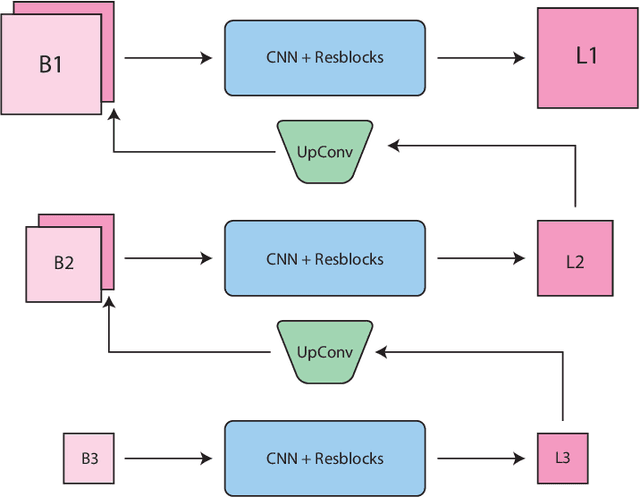
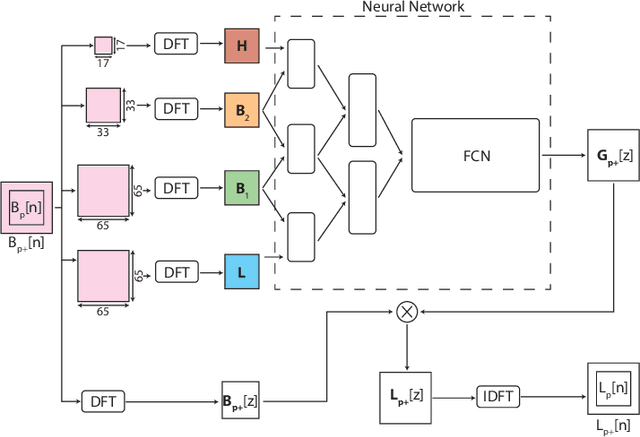
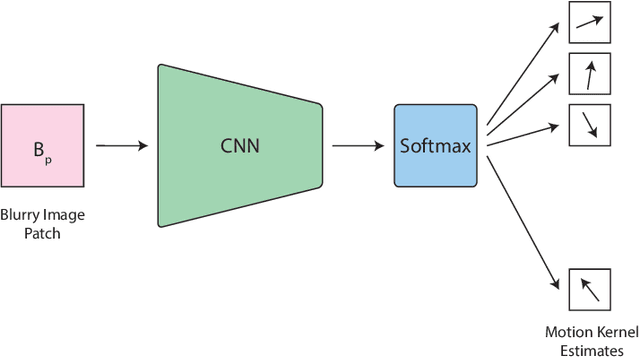
We inspect all the deep learning based solutions and provide holistic understanding of various architectures that have evolved over the past few years to solve blind deblurring. The introductory work used deep learning to estimate some features of the blur kernel and then moved onto predicting the blur kernel entirely, which converts the problem into non-blind deblurring. The recent state of the art techniques are end to end, i.e., they don't estimate the blur kernel rather try to estimate the latent sharp image directly from the blurred image. The benchmarking PSNR and SSIM values on standard datasets of GOPRO and Kohler using various architectures are also provided.
Localization of Unmanned Aerial Vehicles in Corridor Environments using Deep Learning
Mar 21, 2019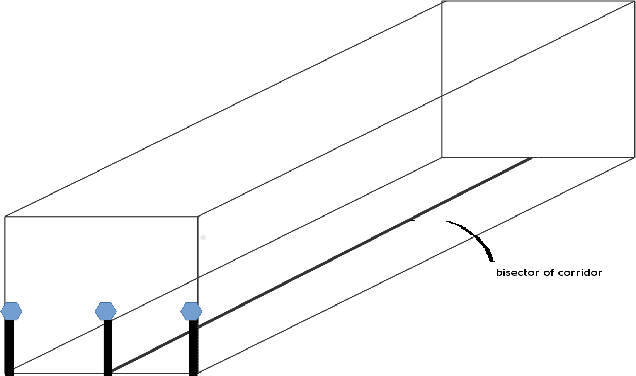

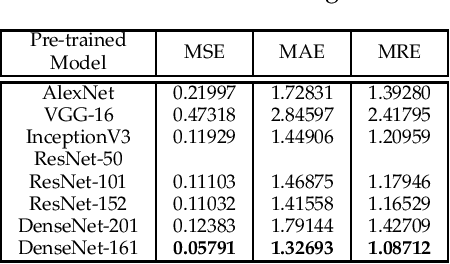
Vision-based pose estimation of Unmanned Aerial Vehicles (UAV) in unknown environments is a rapidly growing research area in the field of robot vision. The task becomes more complex when the only available sensor is a static single camera (monocular vision). In this regard, we propose a monocular vision assisted localization algorithm, that will help a UAV to navigate safely in indoor corridor environments. Always, the aim is to navigate the UAV through a corridor in the forward direction by keeping it at the center with no orientation either to the left or right side. The algorithm makes use of the RGB image, captured from the UAV front camera, and passes it through a trained deep neural network (DNN) to predict the position of the UAV as either on the left or center or right side of the corridor. Depending upon the divergence of the UAV with respect to the central bisector line (CBL) of the corridor, a suitable command is generated to bring the UAV to the center. When the UAV is at the center of the corridor, a new image is passed through another trained DNN to predict the orientation of the UAV with respect to the CBL of the corridor. If the UAV is either left or right tilted, an appropriate command is generated to rectify the orientation. We also propose a new corridor dataset, named NITRCorrV1, which contains images as captured by the UAV front camera when the UAV is at all possible locations of a variety of corridors. An exhaustive set of experiments in different corridors reveal the efficacy of the proposed algorithm.