 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Traffic Flow with Federated Learning and Graph Neural with Asynchronous Computations Network
Jan 05, 2024
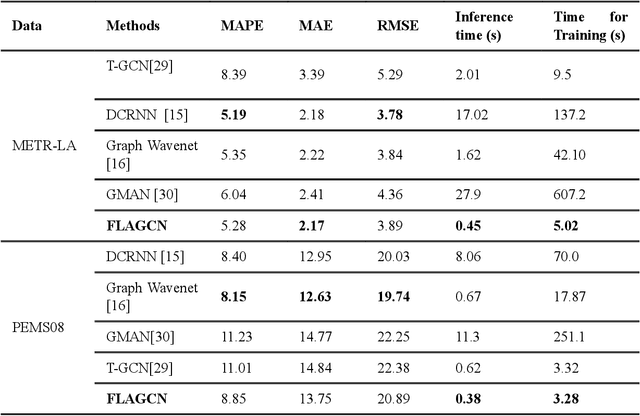
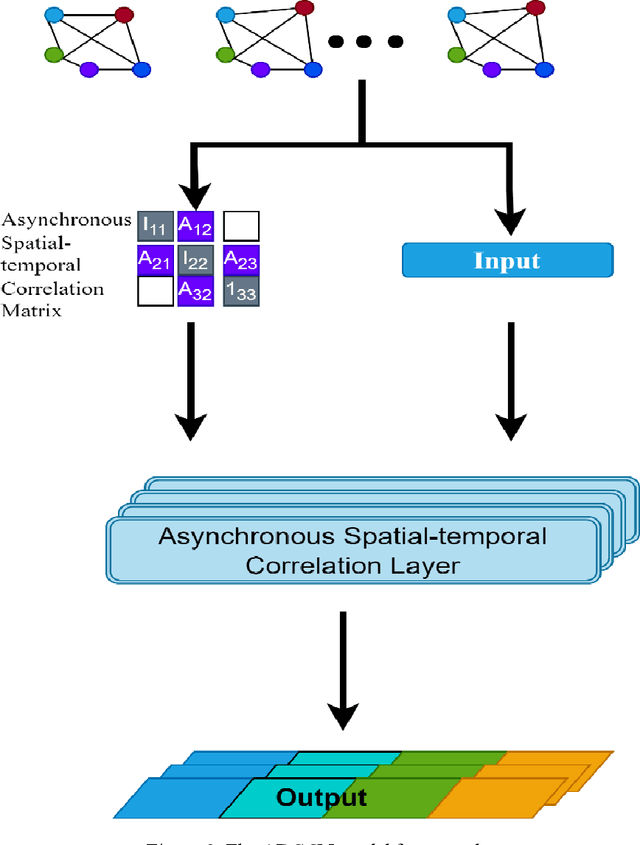

Real-time traffic flow prediction holds significant importance within the domain of Intelligent Transportation Systems (ITS). The task of achieving a balance between prediction precision and computational efficiency presents a significant challenge. In this article, we present a novel deep-learning method called Federated Learning and Asynchronous Graph Convolutional Network (FLAGCN). Our framework incorporates the principles of asynchronous graph convolutional networks with federated learning to enhance the accuracy and efficiency of real-time traffic flow prediction. The FLAGCN model employs a spatial-temporal graph convolution technique to asynchronously address spatio-temporal dependencies within traffic data effectively. To efficiently handle the computational requirements associated with this deep learning model, this study used a graph federated learning technique known as GraphFL. This approach is designed to facilitate the training process. The experimental results obtained from conducting tests on two distinct traffic datasets demonstrate that the utilization of FLAGCN leads to the optimization of both training and inference durations while maintaining a high level of prediction accuracy. FLAGCN outperforms existing models with significant improvements by achieving up to approximately 6.85% reduction in RMSE, 20.45% reduction in MAPE, compared to the best-performing existing models.
EZ-CLIP: Efficient Zeroshot Video Action Recognition
Dec 13, 2023



Recent advancements in large-scale pre-training of visual-language models on paired image-text data have demonstrated impressive generalization capabilities for zero-shot tasks. Building on this success, efforts have been made to adapt these image-based visual-language models, such as CLIP, for videos extending their zero-shot capabilities to the video domain. While these adaptations have shown promising results, they come at a significant computational cost and struggle with effectively modeling the crucial temporal aspects inherent to the video domain. In this study, we present EZ-CLIP, a simple and efficient adaptation of CLIP that addresses these challenges. EZ-CLIP leverages temporal visual prompting for seamless temporal adaptation, requiring no fundamental alterations to the core CLIP architecture while preserving its remarkable generalization abilities. Moreover, we introduce a novel learning objective that guides the temporal visual prompts to focus on capturing motion, thereby enhancing its learning capabilities from video data. We conducted extensive experiments on five different benchmark datasets, thoroughly evaluating EZ-CLIP for zero-shot learning and base-to-novel video action recognition, and also demonstrating its potential for few-shot generalization.Impressively, with a mere 5.2 million learnable parameters (as opposed to the 71.1 million in the prior best model), EZ-CLIP can be efficiently trained on a single GPU, outperforming existing approaches in several evaluations.
Metricizing the Euclidean Space towards Desired Distance Relations in Point Clouds
Nov 07, 2022
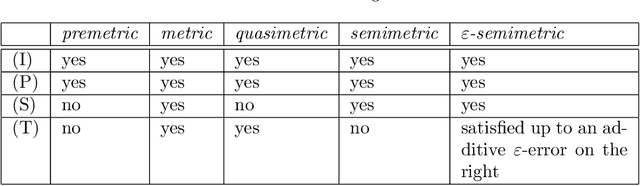
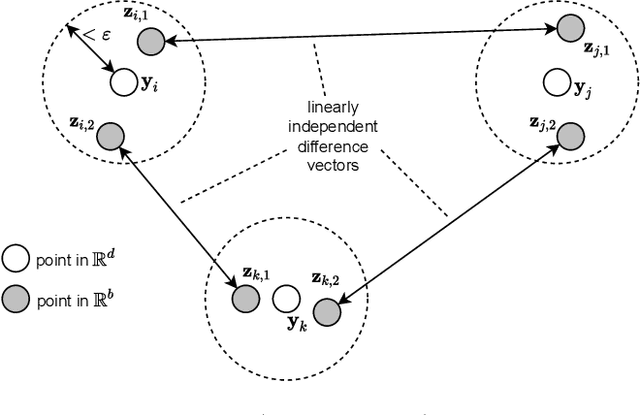
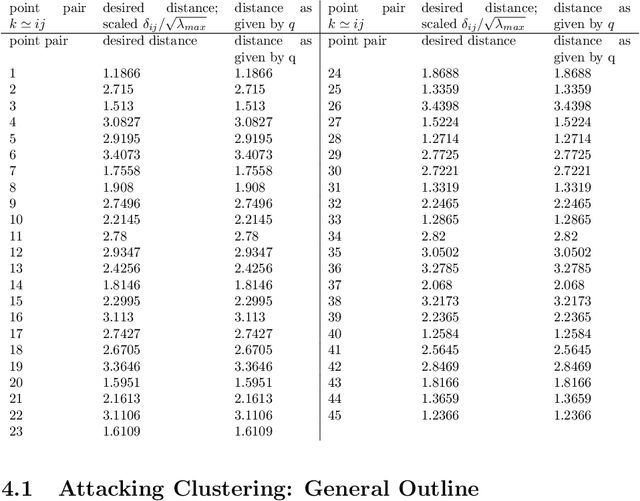
Given a set of points in the Euclidean space $\mathbb{R}^\ell$ with $\ell>1$, the pairwise distances between the points are determined by their spatial location and the metric $d$ that we endow $\mathbb{R}^\ell$ with. Hence, the distance $d(\mathbf x,\mathbf y)=\delta$ between two points is fixed by the choice of $\mathbf x$ and $\mathbf y$ and $d$. We study the related problem of fixing the value $\delta$, and the points $\mathbf x,\mathbf y$, and ask if there is a topological metric $d$ that computes the desired distance $\delta$. We demonstrate this problem to be solvable by constructing a metric to simultaneously give desired pairwise distances between up to $O(\sqrt\ell)$ many points in $\mathbb{R}^\ell$. We then introduce the notion of an $\varepsilon$-semimetric $\tilde{d}$ to formulate our main result: for all $\varepsilon>0$, for all $m\geq 1$, for any choice of $m$ points $\mathbf y_1,\ldots,\mathbf y_m\in\mathbb{R}^\ell$, and all chosen sets of values $\{\delta_{ij}\geq 0: 1\leq i<j\leq m\}$, there exists an $\varepsilon$-semimetric $\tilde{\delta}:\mathbb{R}^\ell\times \mathbb{R}^\ell\to\mathbb{R}$ such that $\tilde{d}(\mathbf y_i,\mathbf y_j)=\delta_{ij}$, i.e., the desired distances are accomplished, irrespectively of the topology that the Euclidean or other norms would induce. We showcase our results by using them to attack unsupervised learning algorithms, specifically $k$-Means and density-based (DBSCAN) clustering algorithms. These have manifold applications in artificial intelligence, and letting them run with externally provided distance measures constructed in the way as shown here, can make clustering algorithms produce results that are pre-determined and hence malleable. This demonstrates that the results of clustering algorithms may not generally be trustworthy, unless there is a standardized and fixed prescription to use a specific distance function.
Localization of Unmanned Aerial Vehicles in Corridor Environments using Deep Learning
Mar 21, 2019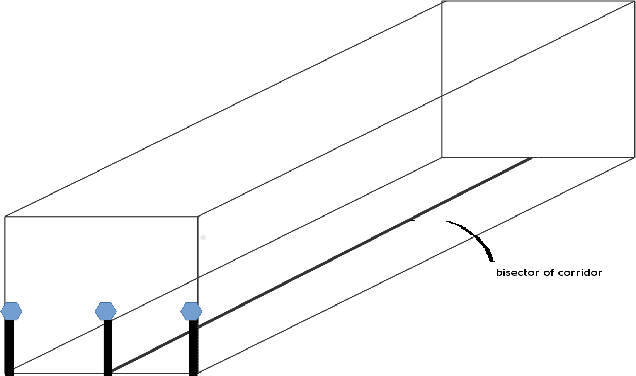

Vision-based pose estimation of Unmanned Aerial Vehicles (UAV) in unknown environments is a rapidly growing research area in the field of robot vision. The task becomes more complex when the only available sensor is a static single camera (monocular vision). In this regard, we propose a monocular vision assisted localization algorithm, that will help a UAV to navigate safely in indoor corridor environments. Always, the aim is to navigate the UAV through a corridor in the forward direction by keeping it at the center with no orientation either to the left or right side. The algorithm makes use of the RGB image, captured from the UAV front camera, and passes it through a trained deep neural network (DNN) to predict the position of the UAV as either on the left or center or right side of the corridor. Depending upon the divergence of the UAV with respect to the central bisector line (CBL) of the corridor, a suitable command is generated to bring the UAV to the center. When the UAV is at the center of the corridor, a new image is passed through another trained DNN to predict the orientation of the UAV with respect to the CBL of the corridor. If the UAV is either left or right tilted, an appropriate command is generated to rectify the orientation. We also propose a new corridor dataset, named NITRCorrV1, which contains images as captured by the UAV front camera when the UAV is at all possible locations of a variety of corridors. An exhaustive set of experiments in different corridors reveal the efficacy of the proposed algorithm.