 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegDesicNet: Lightweight Semantic Segmentation in Remote Sensing with Geo-Coordinate Embeddings for Domain Adaptation
Mar 11, 2025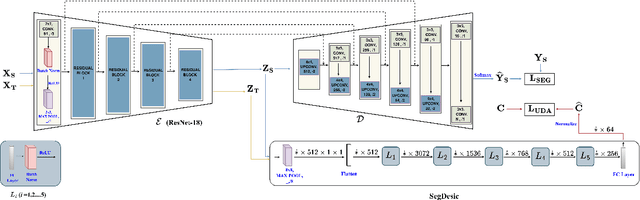

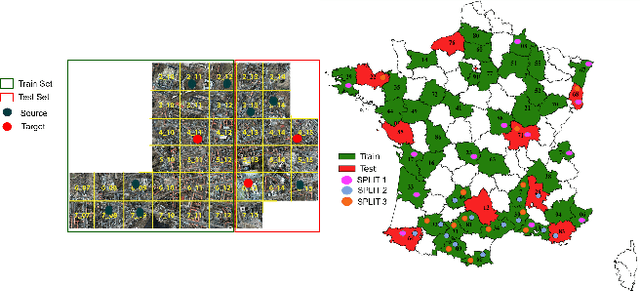
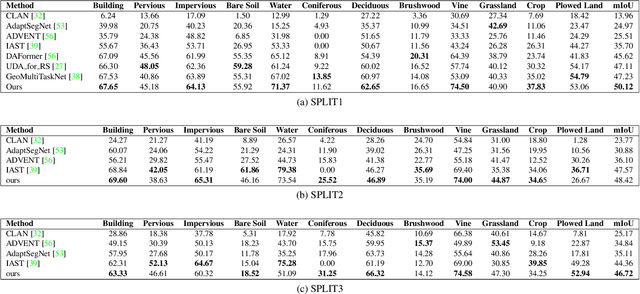
Semantic segmentation is essential for analyzing highdefinition remote sensing images (HRSIs) because it allows the precise classification of objects and regions at the pixel level. However, remote sensing data present challenges owing to geographical location, weather, and environmental variations, making it difficult for semantic segmentation models to generalize across diverse scenarios. Existing methods are often limited to specific data domains and require expert annotators and specialized equipment for semantic labeling. In this study, we propose a novel unsupervised domain adaptation technique for remote sensing semantic segmentation by utilizing geographical coordinates that are readily accessible in remote sensing setups as metadata in a dataset. To bridge the domain gap, we propose a novel approach that considers the combination of an image\'s location encoding trait and the spherical nature of Earth\'s surface. Our proposed SegDesicNet module regresses the GRID positional encoding of the geo coordinates projected over the unit sphere to obtain the domain loss. Our experimental results demonstrate that the proposed SegDesicNet outperforms state of the art domain adaptation methods in remote sensing image segmentation, achieving an improvement of approximately ~6% in the mean intersection over union (MIoU) with a ~ 27\% drop in parameter count on benchmarked subsets of the publicly available FLAIR #1 dataset. We also benchmarked our method performance on the custom split of the ISPRS Potsdam dataset. Our algorithm seeks to reduce the modeling disparity between artificial neural networks and human comprehension of the physical world, making the technology more human centric and scalable.
* https://openaccess.thecvf.com/content/WACV2025/papers/Verma_SegDesicNet_Lightweight_Semantic_Segmentation_in_Remote_Sensing_with_Geo-Coordinate_Embeddings_WACV_2025_paper.pdf
Localization of Unmanned Aerial Vehicles in Corridor Environments using Deep Learning
Mar 21, 2019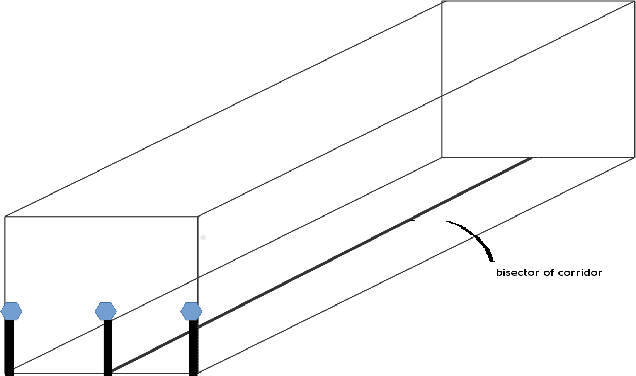
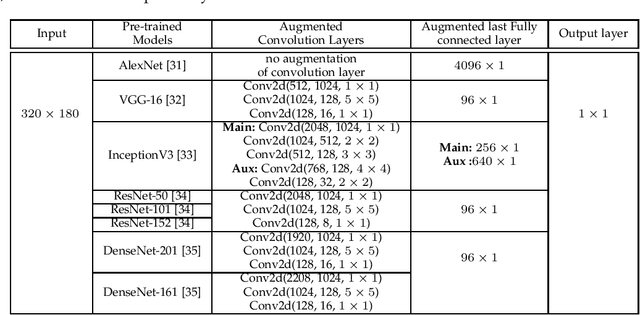

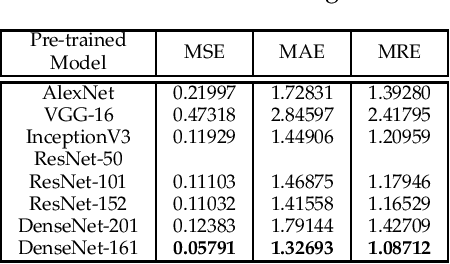
Vision-based pose estimation of Unmanned Aerial Vehicles (UAV) in unknown environments is a rapidly growing research area in the field of robot vision. The task becomes more complex when the only available sensor is a static single camera (monocular vision). In this regard, we propose a monocular vision assisted localization algorithm, that will help a UAV to navigate safely in indoor corridor environments. Always, the aim is to navigate the UAV through a corridor in the forward direction by keeping it at the center with no orientation either to the left or right side. The algorithm makes use of the RGB image, captured from the UAV front camera, and passes it through a trained deep neural network (DNN) to predict the position of the UAV as either on the left or center or right side of the corridor. Depending upon the divergence of the UAV with respect to the central bisector line (CBL) of the corridor, a suitable command is generated to bring the UAV to the center. When the UAV is at the center of the corridor, a new image is passed through another trained DNN to predict the orientation of the UAV with respect to the CBL of the corridor. If the UAV is either left or right tilted, an appropriate command is generated to rectify the orientation. We also propose a new corridor dataset, named NITRCorrV1, which contains images as captured by the UAV front camera when the UAV is at all possible locations of a variety of corridors. An exhaustive set of experiments in different corridors reveal the efficacy of the proposed algorithm.