 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatic and Dynamic Synthesis of Bengali and Devanagari Signatures
Jan 30, 2024



Developing an automatic signature verification system is challenging and demands a large number of training samples. This is why synthetic handwriting generation is an emerging topic in document image analysis. Some handwriting synthesizers use the motor equivalence model, the well-established hypothesis from neuroscience, which analyses how a human being accomplishes movement. Specifically, a motor equivalence model divides human actions into two steps: 1) the effector independent step at cognitive level and 2) the effector dependent step at motor level. In fact, recent work reports the successful application to Western scripts of a handwriting synthesizer, based on this theory. This paper aims to adapt this scheme for the generation of synthetic signatures in two Indic scripts, Bengali (Bangla), and Devanagari (Hindi). For this purpose, we use two different online and offline databases for both Bengali and Devanagari signatures. This paper reports an effective synthesizer for static and dynamic signatures written in Devanagari or Bengali scripts. We obtain promising results with artificially generated signatures in terms of appearance and performance when we compare the results with those for real signatures.
* Accepted version. Published on IEEE Transactions on Cybernetics [ISSN 2168-2267], v. 48(10), p. 2896-2907
EZ-CLIP: Efficient Zeroshot Video Action Recognition
Dec 13, 2023



Recent advancements in large-scale pre-training of visual-language models on paired image-text data have demonstrated impressive generalization capabilities for zero-shot tasks. Building on this success, efforts have been made to adapt these image-based visual-language models, such as CLIP, for videos extending their zero-shot capabilities to the video domain. While these adaptations have shown promising results, they come at a significant computational cost and struggle with effectively modeling the crucial temporal aspects inherent to the video domain. In this study, we present EZ-CLIP, a simple and efficient adaptation of CLIP that addresses these challenges. EZ-CLIP leverages temporal visual prompting for seamless temporal adaptation, requiring no fundamental alterations to the core CLIP architecture while preserving its remarkable generalization abilities. Moreover, we introduce a novel learning objective that guides the temporal visual prompts to focus on capturing motion, thereby enhancing its learning capabilities from video data. We conducted extensive experiments on five different benchmark datasets, thoroughly evaluating EZ-CLIP for zero-shot learning and base-to-novel video action recognition, and also demonstrating its potential for few-shot generalization.Impressively, with a mere 5.2 million learnable parameters (as opposed to the 71.1 million in the prior best model), EZ-CLIP can be efficiently trained on a single GPU, outperforming existing approaches in several evaluations.
PAANet: Progressive Alternating Attention for Automatic Medical Image Segmentation
Nov 20, 2021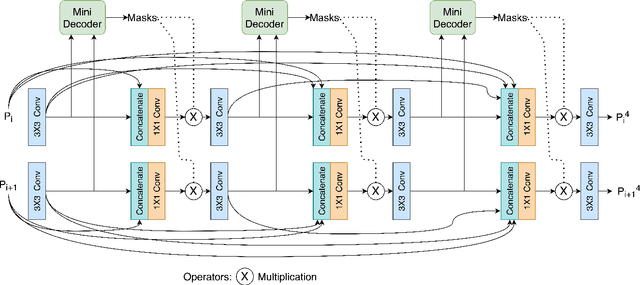

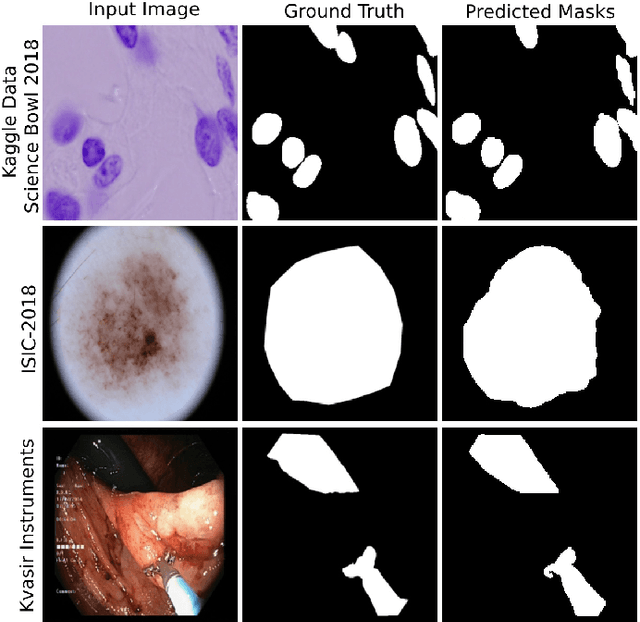
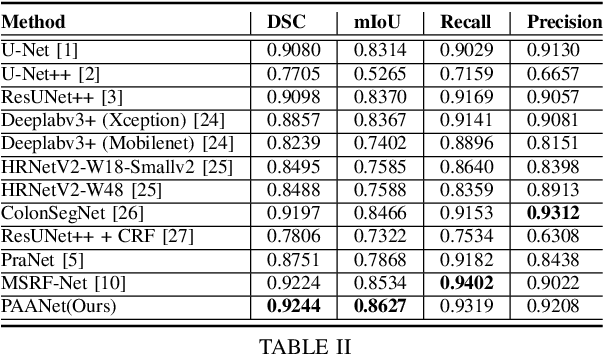
Medical image segmentation can provide detailed information for clinical analysis which can be useful for scenarios where the detailed location of a finding is important. Knowing the location of disease can play a vital role in treatment and decision-making. Convolutional neural network (CNN) based encoder-decoder techniques have advanced the performance of automated medical image segmentation systems. Several such CNN-based methodologies utilize techniques such as spatial- and channel-wise attention to enhance performance. Another technique that has drawn attention in recent years is residual dense blocks (RDBs). The successive convolutional layers in densely connected blocks are capable of extracting diverse features with varied receptive fields and thus, enhancing performance. However, consecutive stacked convolutional operators may not necessarily generate features that facilitate the identification of the target structures. In this paper, we propose a progressive alternating attention network (PAANet). We develop progressive alternating attention dense (PAAD) blocks, which construct a guiding attention map (GAM) after every convolutional layer in the dense blocks using features from all scales. The GAM allows the following layers in the dense blocks to focus on the spatial locations relevant to the target region. Every alternate PAAD block inverts the GAM to generate a reverse attention map which guides ensuing layers to extract boundary and edge-related information, refining the segmentation process. Our experiments on three different biomedical image segmentation datasets exhibit that our PAANet achieves favourable performance when compared to other state-of-the-art methods.
GMSRF-Net: An improved generalizability with global multi-scale residual fusion network for polyp segmentation
Nov 20, 2021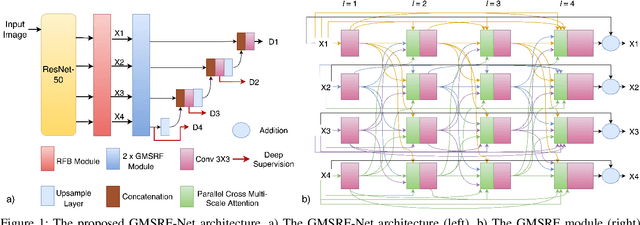
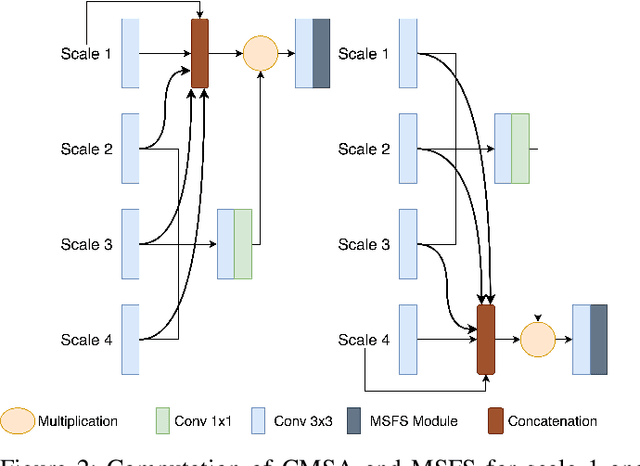
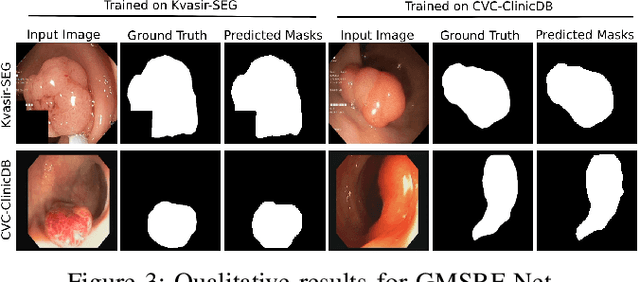
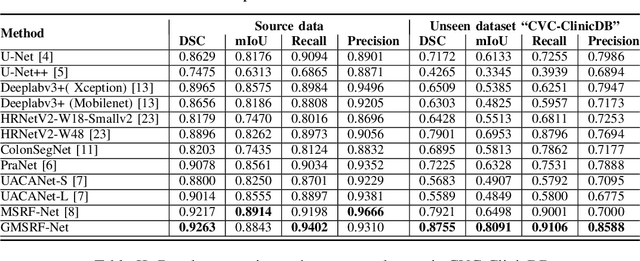
Colonoscopy is a gold standard procedure but is highly operator-dependent. Efforts have been made to automate the detection and segmentation of polyps, a precancerous precursor, to effectively minimize missed rate. Widely used computer-aided polyp segmentation systems actuated by encoder-decoder have achieved high performance in terms of accuracy. However, polyp segmentation datasets collected from varied centers can follow different imaging protocols leading to difference in data distribution. As a result, most methods suffer from performance drop and require re-training for each specific dataset. We address this generalizability issue by proposing a global multi-scale residual fusion network (GMSRF-Net). Our proposed network maintains high-resolution representations while performing multi-scale fusion operations for all resolution scales. To further leverage scale information, we design cross multi-scale attention (CMSA) and multi-scale feature selection (MSFS) modules within the GMSRF-Net. The repeated fusion operations gated by CMSA and MSFS demonstrate improved generalizability of the network. Experiments conducted on two different polyp segmentation datasets show that our proposed GMSRF-Net outperforms the previous top-performing state-of-the-art method by 8.34% and 10.31% on unseen CVC-ClinicDB and unseen Kvasir-SEG, in terms of dice coefficient.
Exploiting Multi-Scale Fusion, Spatial Attention and Patch Interaction Techniques for Text-Independent Writer Identification
Nov 20, 2021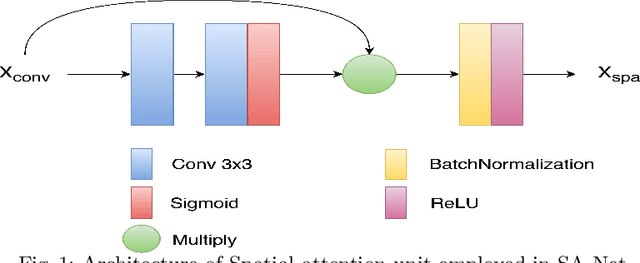
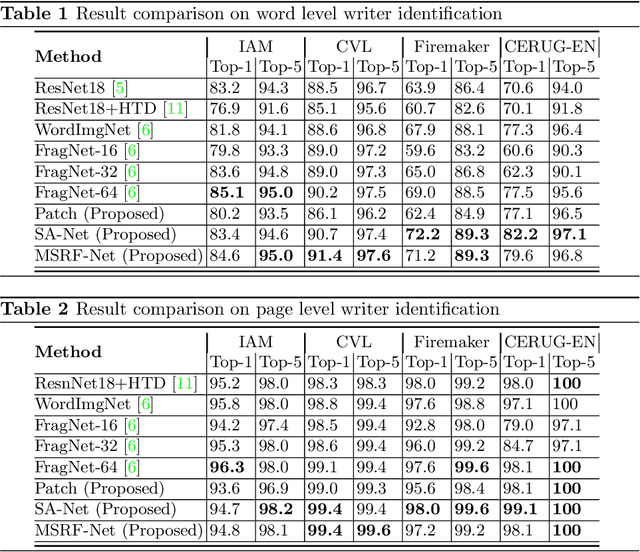
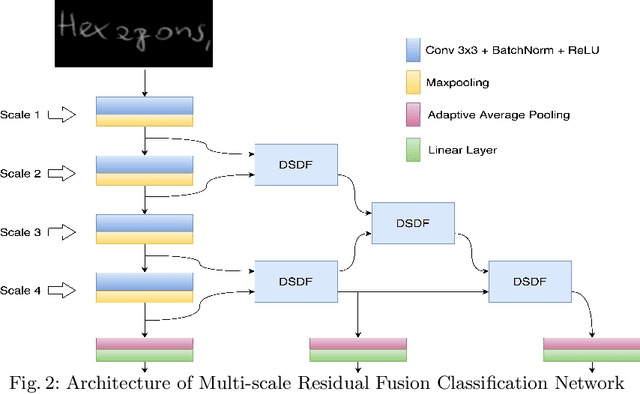
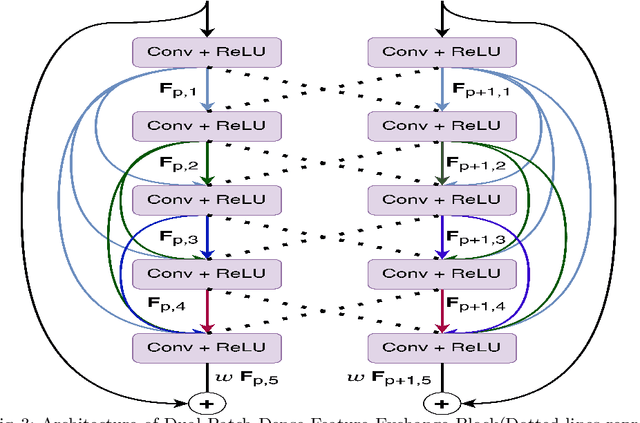
Text independent writer identification is a challenging problem that differentiates between different handwriting styles to decide the author of the handwritten text. Earlier writer identification relied on handcrafted features to reveal pieces of differences between writers. Recent work with the advent of convolutional neural network, deep learning-based methods have evolved. In this paper, three different deep learning techniques - spatial attention mechanism, multi-scale feature fusion and patch-based CNN were proposed to effectively capture the difference between each writer's handwriting. Our methods are based on the hypothesis that handwritten text images have specific spatial regions which are more unique to a writer's style, multi-scale features propagate characteristic features with respect to individual writers and patch-based features give more general and robust representations that helps to discriminate handwriting from different writers. The proposed methods outperforms various state-of-the-art methodologies on word-level and page-level writer identification methods on three publicly available datasets - CVL, Firemaker, CERUG-EN datasets and give comparable performance on the IAM dataset.
AGA-GAN: Attribute Guided Attention Generative Adversarial Network with U-Net for Face Hallucination
Nov 20, 2021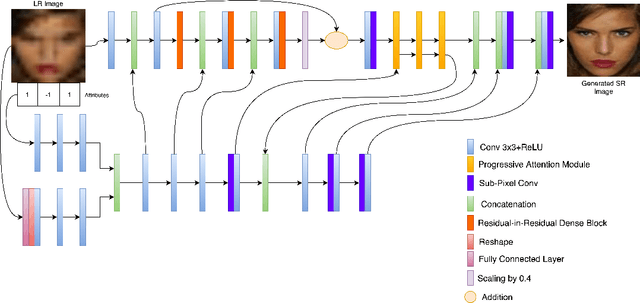
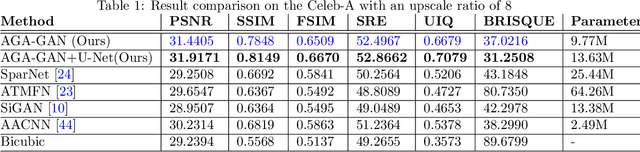
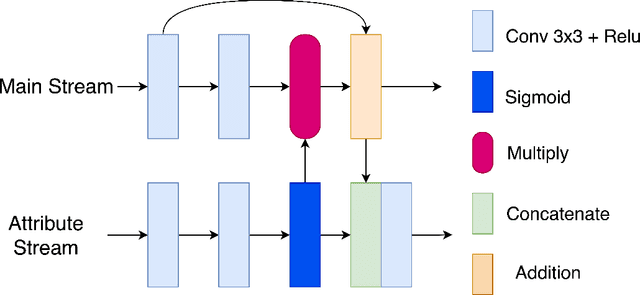
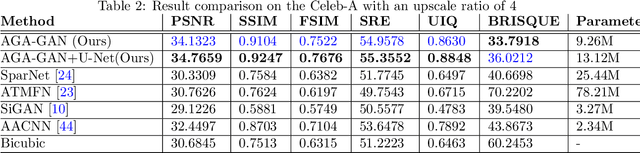
The performance of facial super-resolution methods relies on their ability to recover facial structures and salient features effectively. Even though the convolutional neural network and generative adversarial network-based methods deliver impressive performances on face hallucination tasks, the ability to use attributes associated with the low-resolution images to improve performance is unsatisfactory. In this paper, we propose an Attribute Guided Attention Generative Adversarial Network which employs novel attribute guided attention (AGA) modules to identify and focus the generation process on various facial features in the image. Stacking multiple AGA modules enables the recovery of both high and low-level facial structures. We design the discriminator to learn discriminative features exploiting the relationship between the high-resolution image and their corresponding facial attribute annotations. We then explore the use of U-Net based architecture to refine existing predictions and synthesize further facial details. Extensive experiments across several metrics show that our AGA-GAN and AGA-GAN+U-Net framework outperforms several other cutting-edge face hallucination state-of-the-art methods. We also demonstrate the viability of our method when every attribute descriptor is not known and thus, establishing its application in real-world scenarios.
LoOp: Looking for Optimal Hard Negative Embeddings for Deep Metric Learning
Aug 20, 2021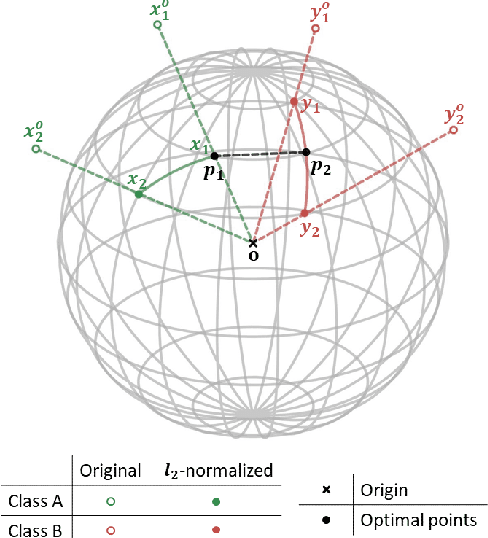

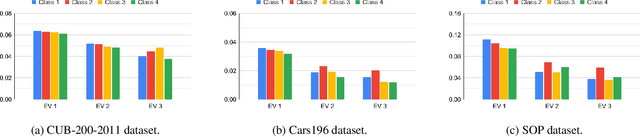
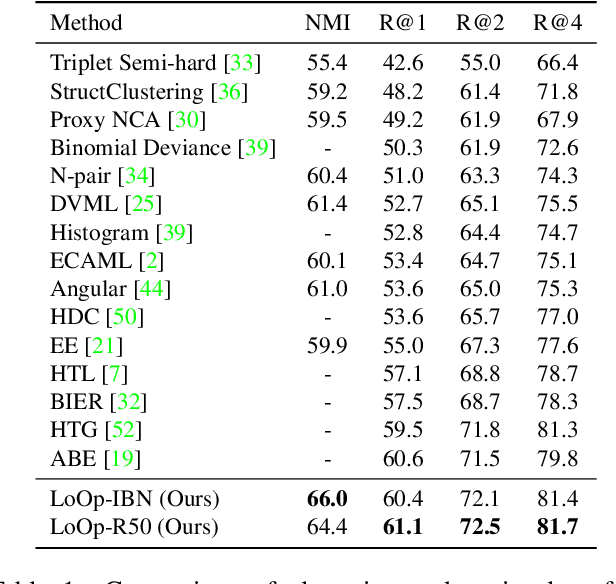
Deep metric learning has been effectively used to learn distance metrics for different visual tasks like image retrieval, clustering, etc. In order to aid the training process, existing methods either use a hard mining strategy to extract the most informative samples or seek to generate hard synthetics using an additional network. Such approaches face different challenges and can lead to biased embeddings in the former case, and (i) harder optimization (ii) slower training speed (iii) higher model complexity in the latter case. In order to overcome these challenges, we propose a novel approach that looks for optimal hard negatives (LoOp) in the embedding space, taking full advantage of each tuple by calculating the minimum distance between a pair of positives and a pair of negatives. Unlike mining-based methods, our approach considers the entire space between pairs of embeddings to calculate the optimal hard negatives. Extensive experiments combining our approach and representative metric learning losses reveal a significant boost in performance on three benchmark datasets.
Semantic Text-to-Face GAN -ST^2FG
Jul 22, 2021
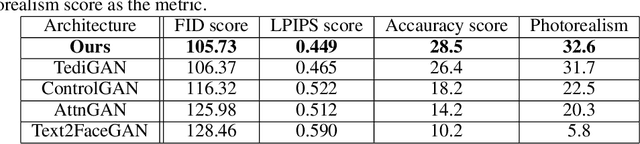
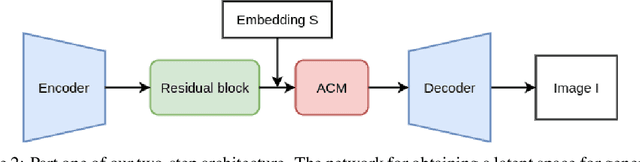

Faces generated using generative adversarial networks (GANs) have reached unprecedented realism. These faces, also known as "Deep Fakes", appear as realistic photographs with very little pixel-level distortions. While some work has enabled the training of models that lead to the generation of specific properties of the subject, generating a facial image based on a natural language description has not been fully explored. For security and criminal identification, the ability to provide a GAN-based system that works like a sketch artist would be incredibly useful. In this paper, we present a novel approach to generate facial images from semantic text descriptions. The learned model is provided with a text description and an outline of the type of face, which the model uses to sketch the features. Our models are trained using an Affine Combination Module (ACM) mechanism to combine the text embedding from BERT and the GAN latent space using a self-attention matrix. This avoids the loss of features due to inadequate "attention", which may happen if text embedding and latent vector are simply concatenated. Our approach is capable of generating images that are very accurately aligned to the exhaustive textual descriptions of faces with many fine detail features of the face and helps in generating better images. The proposed method is also capable of making incremental changes to a previously generated image if it is provided with additional textual descriptions or sentences.
PhoNet: An Approach Towards Zero-shot Word Image Recognition in Historical Documents
May 31, 2021
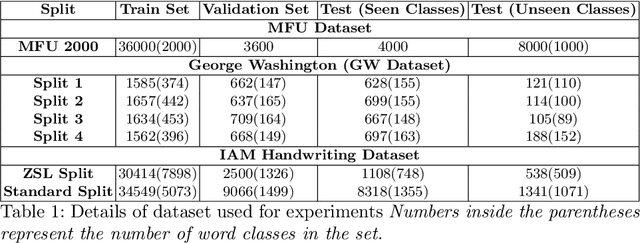

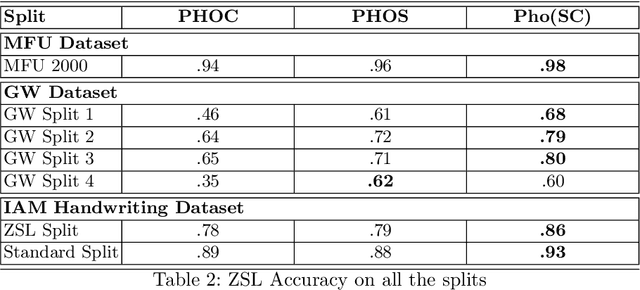
Annotating words in a historical document image archive for word image recognition purpose demands time and skilled human resource (like historians, paleographers). In a real-life scenario, obtaining sample images for all possible words is also not feasible. However, Zero-shot learning methods could aptly be used to recognize unseen/out-of-lexicon words in such historical document images. Based on previous state-of-the-art methods for word spotting and recognition, we propose a hybrid representation that considers the character's shape appearance to differentiate between two different words and has shown to be more effective in recognizing unseen words. This representation has been termed as Pyramidal Histogram of Shapes (PHOS), derived from PHOC, which embeds information about the occurrence and position of characters in the word. Later, the two representations are combined and experiments were conducted to examine the effectiveness of an embedding that has properties of both PHOS and PHOC. Encouraging results were obtained on two publicly available historical document datasets and one synthetic handwritten dataset, which justifies the efficacy of "Phos" and the combined "Pho(SC)" representation.
MSRF-Net: A Multi-Scale Residual Fusion Network for Biomedical Image Segmentation
May 16, 2021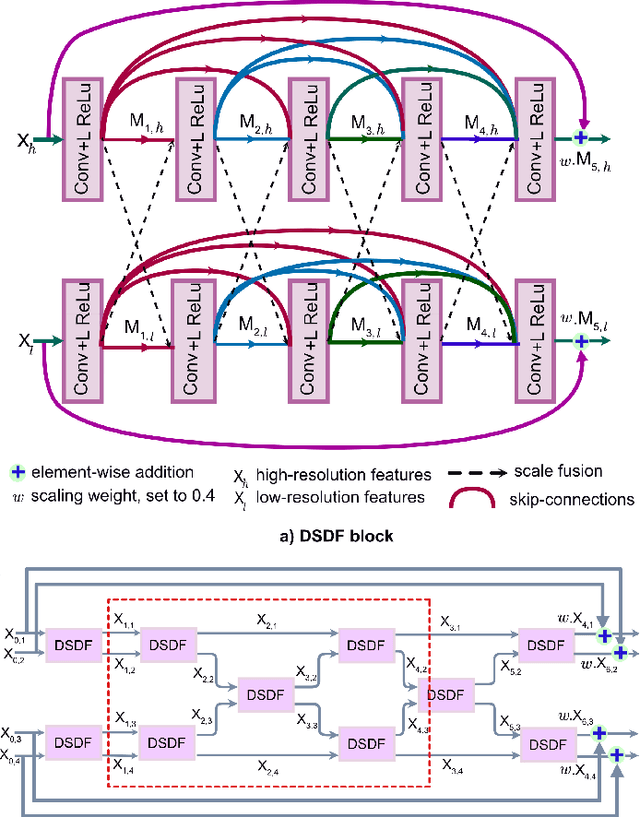
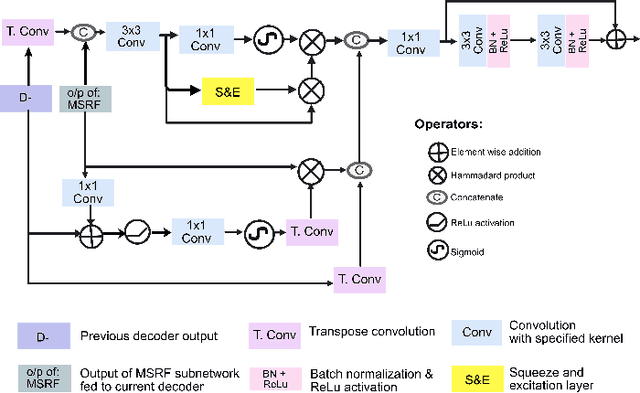
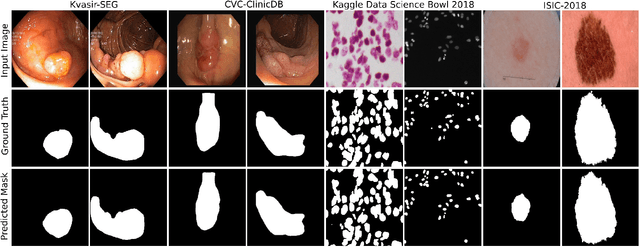
Methods based on convolutional neural networks have improved the performance of biomedical image segmentation. However, most of these methods cannot efficiently segment objects of variable sizes and train on small and biased datasets, which are common in biomedical use cases. While methods exist that incorporate multi-scale fusion approaches to address the challenges arising with variable sizes, they usually use complex models that are more suitable for general semantic segmentation computer vision problems. In this paper, we propose a novel architecture called MSRF-Net, which is specially designed for medical image segmentation tasks. The proposed MSRF-Net is able to exchange multi-scale features of varying receptive fields using a dual-scale dense fusion block (DSDF). Our DSDF block can exchange information rigorously across two different resolution scales, and our MSRF sub-network uses multiple DSDF blocks in sequence to perform multi-scale fusion. This allows the preservation of resolution, improved information flow, and propagation of both high- and low-level features to obtain accurate segmentation maps. The proposed MSRF-Net allows to capture object variabilities and provides improved results on different biomedical datasets. Extensive experiments on MSRF-Net demonstrate that the proposed method outperforms most of the cutting-edge medical image segmentation state-of-the-art methods. MSRF-Net advances the performance on four publicly available datasets, and also, MSRF-Net is more generalizable as compared to state-of-the-art methods.