 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Text-to-Face GAN -ST^2FG
Paper and Code
Jul 22, 2021
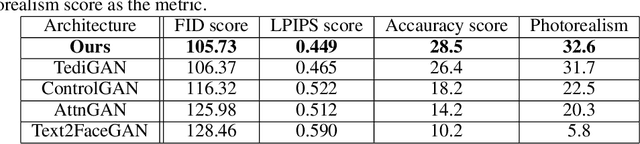
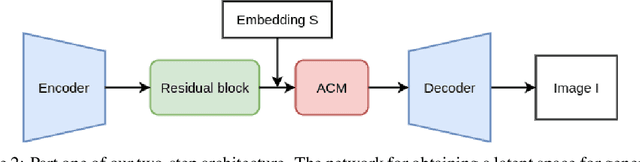

Faces generated using generative adversarial networks (GANs) have reached unprecedented realism. These faces, also known as "Deep Fakes", appear as realistic photographs with very little pixel-level distortions. While some work has enabled the training of models that lead to the generation of specific properties of the subject, generating a facial image based on a natural language description has not been fully explored. For security and criminal identification, the ability to provide a GAN-based system that works like a sketch artist would be incredibly useful. In this paper, we present a novel approach to generate facial images from semantic text descriptions. The learned model is provided with a text description and an outline of the type of face, which the model uses to sketch the features. Our models are trained using an Affine Combination Module (ACM) mechanism to combine the text embedding from BERT and the GAN latent space using a self-attention matrix. This avoids the loss of features due to inadequate "attention", which may happen if text embedding and latent vector are simply concatenated. Our approach is capable of generating images that are very accurately aligned to the exhaustive textual descriptions of faces with many fine detail features of the face and helps in generating better images. The proposed method is also capable of making incremental changes to a previously generated image if it is provided with additional textual descriptions or sentences.