 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyFFPAD: Dynamic Fusion of Convolutional and Handcrafted Features for Fingerprint Presentation Attack Detection
Aug 19, 2023



Automatic fingerprint recognition systems suffer from the threat of presentation attacks due to their wide range of applications in areas including national borders and commercial applications. Presentation attacks can be performed by fabricating the fake fingerprint of a user with or without the intention of the subject. This paper presents a dynamic ensemble of deep learning and handcrafted features to detect presentation attacks in known-material and unknown-material protocols. The proposed model is a dynamic ensemble of deep CNN and handcrafted features empowered deep neural networks both of which learn their parameters together. The proposed presentation attack detection model, in this way, utilizes the capabilities of both classification techniques and exhibits better performance than their individual results. The proposed model's performance is validated using benchmark LivDet 2015, 2017, and 2019 databases, with an overall accuracy of 96.10\%, 96.49\%, and 95.99\% attained on them, respectively. The proposed model outperforms state-of-the-art methods in benchmark protocols of presentation attack detection in terms of classification accuracy.
An Open Patch Generator based Fingerprint Presentation Attack Detection using Generative Adversarial Network
Jun 06, 2023



The low-cost, user-friendly, and convenient nature of Automatic Fingerprint Recognition Systems (AFRS) makes them suitable for a wide range of applications. This spreading use of AFRS also makes them vulnerable to various security threats. Presentation Attack (PA) or spoofing is one of the threats which is caused by presenting a spoof of a genuine fingerprint to the sensor of AFRS. Fingerprint Presentation Attack Detection (FPAD) is a countermeasure intended to protect AFRS against fake or spoof fingerprints created using various fabrication materials. In this paper, we have proposed a Convolutional Neural Network (CNN) based technique that uses a Generative Adversarial Network (GAN) to augment the dataset with spoof samples generated from the proposed Open Patch Generator (OPG). This OPG is capable of generating realistic fingerprint samples which have no resemblance to the existing spoof fingerprint samples generated with other materials. The augmented dataset is fed to the DenseNet classifier which helps in increasing the performance of the Presentation Attack Detection (PAD) module for the various real-world attacks possible with unknown spoof materials. Experimental evaluations of the proposed approach are carried out on the Liveness Detection (LivDet) 2015, 2017, and 2019 competition databases. An overall accuracy of 96.20\%, 94.97\%, and 92.90\% has been achieved on the LivDet 2015, 2017, and 2019 databases, respectively under the LivDet protocol scenarios. The performance of the proposed PAD model is also validated in the cross-material and cross-sensor attack paradigm which further exhibits its capability to be used under real-world attack scenarios.
EXPRESSNET: An Explainable Residual Slim Network for Fingerprint Presentation Attack Detection
May 16, 2023



Presentation attack is a challenging issue that persists in the security of automatic fingerprint recognition systems. This paper proposes a novel explainable residual slim network that detects the presentation attack by representing the visual features in the input fingerprint sample. The encoder-decoder of this network along with the channel attention block converts the input sample into its heatmap representation while the modified residual convolutional neural network classifier discriminates between live and spoof fingerprints. The entire architecture of the heatmap generator block and modified ResNet classifier works together in an end-to-end manner. The performance of the proposed model is validated on benchmark liveness detection competition databases i.e. Livdet 2011, 2013, 2015, 2017, and 2019 and the classification accuracy of 96.86\%, 99.84\%, 96.45\%, 96.07\%, 96.27\% are achieved on them, respectively. The performance of the proposed model is compared with the state-of-the-art techniques, and the proposed method outperforms state-of-the-art methods in benchmark protocols of presentation attack detection in terms of classification accuracy.
MoSFPAD: An end-to-end Ensemble of MobileNet and Support Vector Classifier for Fingerprint Presentation Attack Detection
Mar 02, 2023



Automatic fingerprint recognition systems are the most extensively used systems for person authentication although they are vulnerable to Presentation attacks. Artificial artifacts created with the help of various materials are used to deceive these systems causing a threat to the security of fingerprint-based applications. This paper proposes a novel end-to-end model to detect fingerprint Presentation attacks. The proposed model incorporates MobileNet as a feature extractor and a Support Vector Classifier as a classifier to detect presentation attacks in cross-material and cross-sensor paradigms. The feature extractor's parameters are learned with the loss generated by the support vector classifier. The proposed model eliminates the need for intermediary data preparation procedures, unlike other static hybrid architectures. The performance of the proposed model has been validated on benchmark LivDet 2011, 2013, 2015, 2017, and 2019 databases, and overall accuracy of 98.64%, 99.50%, 97.23%, 95.06%, and 95.20% is achieved on these databases, respectively. The performance of the proposed model is compared with state-of-the-art methods and the proposed method outperforms in cross-material and cross-sensor paradigms in terms of average classification error.
PhoNet: An Approach Towards Zero-shot Word Image Recognition in Historical Documents
May 31, 2021
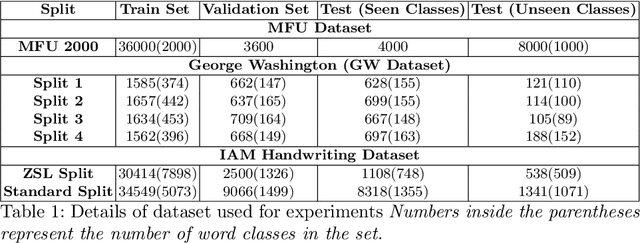

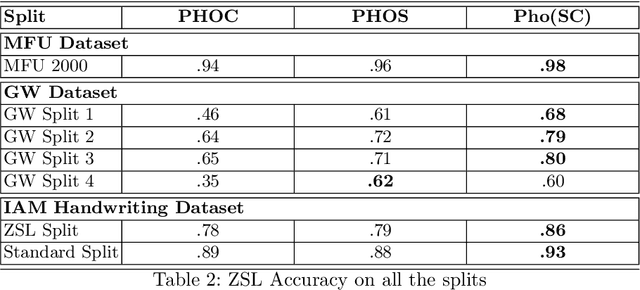
Annotating words in a historical document image archive for word image recognition purpose demands time and skilled human resource (like historians, paleographers). In a real-life scenario, obtaining sample images for all possible words is also not feasible. However, Zero-shot learning methods could aptly be used to recognize unseen/out-of-lexicon words in such historical document images. Based on previous state-of-the-art methods for word spotting and recognition, we propose a hybrid representation that considers the character's shape appearance to differentiate between two different words and has shown to be more effective in recognizing unseen words. This representation has been termed as Pyramidal Histogram of Shapes (PHOS), derived from PHOC, which embeds information about the occurrence and position of characters in the word. Later, the two representations are combined and experiments were conducted to examine the effectiveness of an embedding that has properties of both PHOS and PHOC. Encouraging results were obtained on two publicly available historical document datasets and one synthetic handwritten dataset, which justifies the efficacy of "Phos" and the combined "Pho(SC)" representation.