 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Contextual Recall in Transformers: How Finetuning Enables In-Context Reasoning over Pretraining Knowledge
Mar 21, 2026Transformer-based language models excel at in-context learning (ICL), where they can adapt to new tasks based on contextual examples, without parameter updates. In a specific form of ICL, which we refer to as \textit{contextual recall}, models pretrained on open-ended text leverage pairwise examples to recall specific facts in novel prompt formats. We investigate whether contextual recall emerges from pretraining alone, what finetuning is required, and what mechanisms drive the necessary representations. For this, we introduce a controlled synthetic framework where pretraining sequences consist of subject-grammar-attribute tuples, with attribute types tied to grammar statistics. We demonstrate that while such pretraining successfully yields factual knowledge, it is insufficient for contextual recall: models fail to implicitly infer attribute types when the grammar statistics are removed in ICL prompts. However, we show that finetuning on tasks requiring implicit inference, distinct from the ICL evaluation, using a subset of subjects, triggers the emergence of contextual recall across all subjects. This transition is accompanied by the formation of low-dimensional latent encodings of the shared attribute type. For mechanistic insight, we derive a construction for an attention-only transformer that replicates the transition from factual to contextual recall, corroborated by empirical validation.
How Muon's Spectral Design Benefits Generalization: A Study on Imbalanced Data
Oct 27, 2025



The growing adoption of spectrum-aware matrix-valued optimizers such as Muon and Shampoo in deep learning motivates a systematic study of their generalization properties and, in particular, when they might outperform competitive algorithms. We approach this question by introducing appropriate simplifying abstractions as follows: First, we use imbalanced data as a testbed. Second, we study the canonical form of such optimizers, which is Spectral Gradient Descent (SpecGD) -- each update step is $UV^T$ where $U\Sigma V^T$ is the truncated SVD of the gradient. Third, within this framework we identify a canonical setting for which we precisely quantify when SpecGD outperforms vanilla Euclidean GD. For a Gaussian mixture data model and both linear and bilinear models, we show that unlike GD, which prioritizes learning dominant principal components of the data first, SpecGD learns all principal components of the data at equal rates. We demonstrate how this translates to a growing gap in balanced accuracy favoring SpecGD early in training and further show that the gap remains consistent even when the GD counterpart uses adaptive step-sizes via normalization. By extending the analysis to deep linear models, we show that depth amplifies these effects. We empirically verify our theoretical findings on a variety of imbalanced datasets. Our experiments compare practical variants of spectral methods, like Muon and Shampoo, against their Euclidean counterparts and Adam. The results validate our findings that these spectral optimizers achieve superior generalization by promoting a more balanced learning of the data's underlying components.
In-Context Occam's Razor: How Transformers Prefer Simpler Hypotheses on the Fly
Jun 24, 2025In-context learning (ICL) enables transformers to adapt to new tasks through contextual examples without parameter updates. While existing research has typically studied ICL in fixed-complexity environments, practical language models encounter tasks spanning diverse complexity levels. This paper investigates how transformers navigate hierarchical task structures where higher-complexity categories can perfectly represent any pattern generated by simpler ones. We design well-controlled testbeds based on Markov chains and linear regression that reveal transformers not only identify the appropriate complexity level for each task but also accurately infer the corresponding parameters--even when the in-context examples are compatible with multiple complexity hypotheses. Notably, when presented with data generated by simpler processes, transformers consistently favor the least complex sufficient explanation. We theoretically explain this behavior through a Bayesian framework, demonstrating that transformers effectively implement an in-context Bayesian Occam's razor by balancing model fit against complexity penalties. We further ablate on the roles of model size, training mixture distribution, inference context length, and architecture. Finally, we validate this Occam's razor-like inductive bias on a pretrained GPT-4 model with Boolean-function tasks as case study, suggesting it may be inherent to transformers trained on diverse task distributions.
The Rich and the Simple: On the Implicit Bias of Adam and SGD
May 29, 2025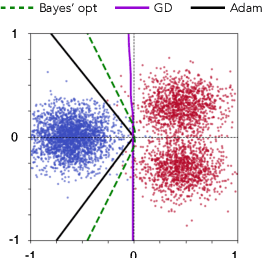
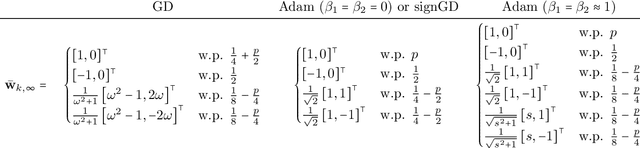
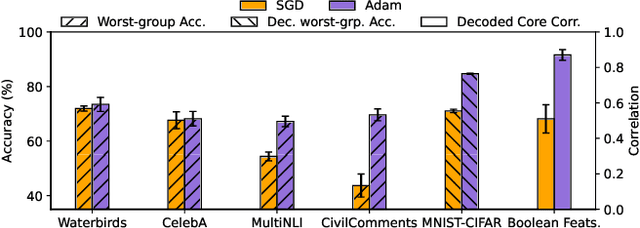

Adam is the de facto optimization algorithm for several deep learning applications, but an understanding of its implicit bias and how it differs from other algorithms, particularly standard first-order methods such as (stochastic) gradient descent (GD), remains limited. In practice, neural networks trained with SGD are known to exhibit simplicity bias -- a tendency to find simple solutions. In contrast, we show that Adam is more resistant to such simplicity bias. To demystify this phenomenon, in this paper, we investigate the differences in the implicit biases of Adam and GD when training two-layer ReLU neural networks on a binary classification task involving synthetic data with Gaussian clusters. We find that GD exhibits a simplicity bias, resulting in a linear decision boundary with a suboptimal margin, whereas Adam leads to much richer and more diverse features, producing a nonlinear boundary that is closer to the Bayes' optimal predictor. This richer decision boundary also allows Adam to achieve higher test accuracy both in-distribution and under certain distribution shifts. We theoretically prove these results by analyzing the population gradients. To corroborate our theoretical findings, we present empirical results showing that this property of Adam leads to superior generalization across datasets with spurious correlations where neural networks trained with SGD are known to show simplicity bias and don't generalize well under certain distributional shifts.
Simplicity Bias of Transformers to Learn Low Sensitivity Functions
Mar 11, 2024Transformers achieve state-of-the-art accuracy and robustness across many tasks, but an understanding of the inductive biases that they have and how those biases are different from other neural network architectures remains elusive. Various neural network architectures such as fully connected networks have been found to have a simplicity bias towards simple functions of the data; one version of this simplicity bias is a spectral bias to learn simple functions in the Fourier space. In this work, we identify the notion of sensitivity of the model to random changes in the input as a notion of simplicity bias which provides a unified metric to explain the simplicity and spectral bias of transformers across different data modalities. We show that transformers have lower sensitivity than alternative architectures, such as LSTMs, MLPs and CNNs, across both vision and language tasks. We also show that low-sensitivity bias correlates with improved robustness; furthermore, it can also be used as an efficient intervention to further improve the robustness of transformers.
Implicit Bias and Fast Convergence Rates for Self-attention
Feb 08, 2024



Self-attention, the core mechanism of transformers, distinguishes them from traditional neural networks and drives their outstanding performance. Towards developing the fundamental optimization principles of self-attention, we investigate the implicit bias of gradient descent (GD) in training a self-attention layer with fixed linear decoder in binary classification. Drawing inspiration from the study of GD in linear logistic regression over separable data, recent work demonstrates that as the number of iterations $t$ approaches infinity, the key-query matrix $W_t$ converges locally (with respect to the initialization direction) to a hard-margin SVM solution $W_{mm}$. Our work enhances this result in four aspects. Firstly, we identify non-trivial data settings for which convergence is provably global, thus shedding light on the optimization landscape. Secondly, we provide the first finite-time convergence rate for $W_t$ to $W_{mm}$, along with quantifying the rate of sparsification in the attention map. Thirdly, through an analysis of normalized GD and Polyak step-size, we demonstrate analytically that adaptive step-size rules can accelerate the convergence of self-attention. Additionally, we remove the restriction of prior work on a fixed linear decoder. Our results reinforce the implicit-bias perspective of self-attention and strengthen its connections to implicit-bias in linear logistic regression, despite the intricate non-convex nature of the former.
Mitigating Simplicity Bias in Deep Learning for Improved OOD Generalization and Robustness
Oct 09, 2023


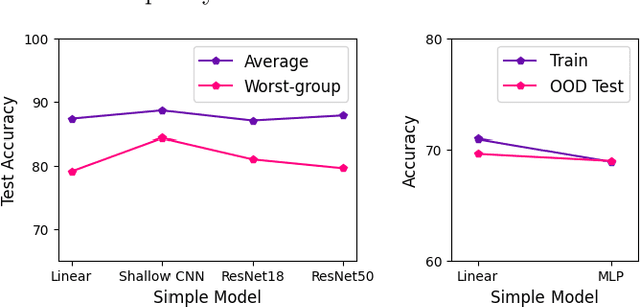
Neural networks (NNs) are known to exhibit simplicity bias where they tend to prefer learning 'simple' features over more 'complex' ones, even when the latter may be more informative. Simplicity bias can lead to the model making biased predictions which have poor out-of-distribution (OOD) generalization. To address this, we propose a framework that encourages the model to use a more diverse set of features to make predictions. We first train a simple model, and then regularize the conditional mutual information with respect to it to obtain the final model. We demonstrate the effectiveness of this framework in various problem settings and real-world applications, showing that it effectively addresses simplicity bias and leads to more features being used, enhances OOD generalization, and improves subgroup robustness and fairness. We complement these results with theoretical analyses of the effect of the regularization and its OOD generalization properties.
LoOp: Looking for Optimal Hard Negative Embeddings for Deep Metric Learning
Aug 20, 2021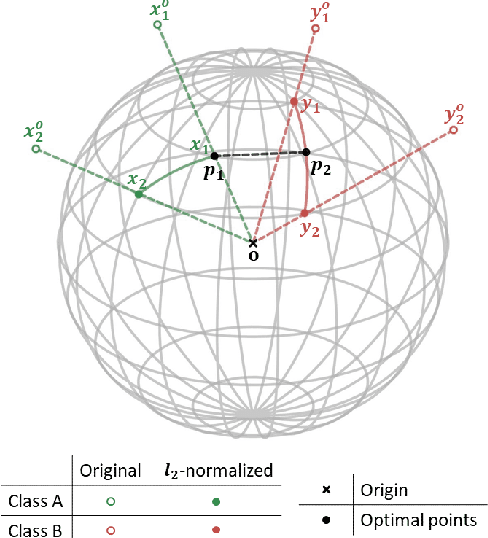

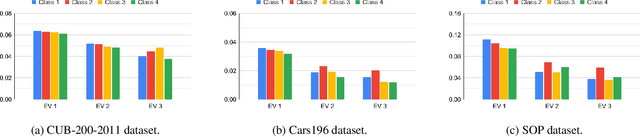
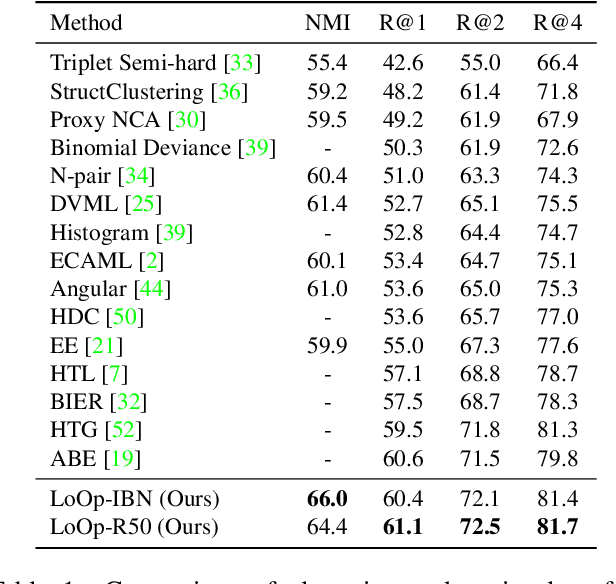
Deep metric learning has been effectively used to learn distance metrics for different visual tasks like image retrieval, clustering, etc. In order to aid the training process, existing methods either use a hard mining strategy to extract the most informative samples or seek to generate hard synthetics using an additional network. Such approaches face different challenges and can lead to biased embeddings in the former case, and (i) harder optimization (ii) slower training speed (iii) higher model complexity in the latter case. In order to overcome these challenges, we propose a novel approach that looks for optimal hard negatives (LoOp) in the embedding space, taking full advantage of each tuple by calculating the minimum distance between a pair of positives and a pair of negatives. Unlike mining-based methods, our approach considers the entire space between pairs of embeddings to calculate the optimal hard negatives. Extensive experiments combining our approach and representative metric learning losses reveal a significant boost in performance on three benchmark datasets.
Multi-Phase Locking Value: A Generalized Method for Determining Instantaneous Multi-frequency Phase Coupling
Feb 20, 2021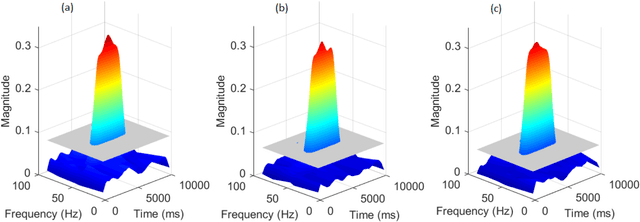
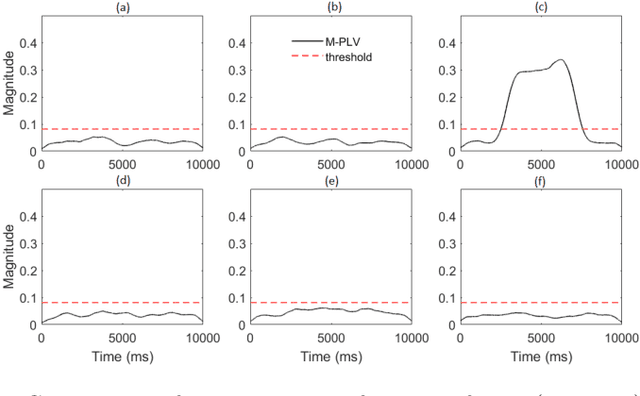
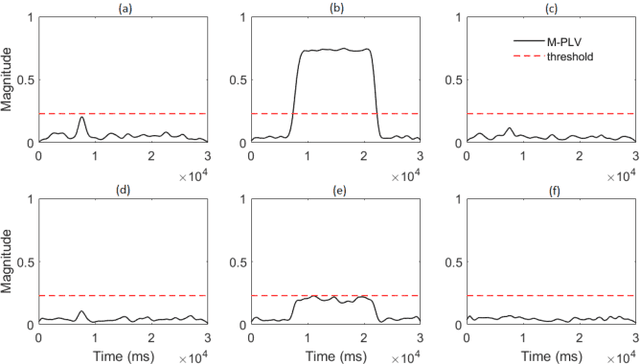
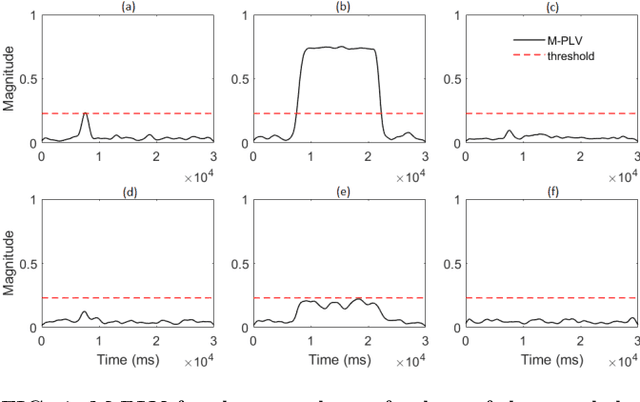
Many physical, biological and neural systems behave as coupled oscillators, with characteristic phase coupling across different frequencies. Methods such as $n:m$ phase locking value and bi-phase locking value have previously been proposed to quantify phase coupling between two resonant frequencies (e.g. $f$, $2f/3$) and across three frequencies (e.g. $f_1$, $f_2$, $f_1+f_2$), respectively. However, the existing phase coupling metrics have their limitations and limited applications. They cannot be used to detect or quantify phase coupling across multiple frequencies (e.g. $f_1$, $f_2$, $f_3$, $f_4$, $f_1+f_2+f_3-f_4$), or coupling that involves non-integer multiples of the frequencies (e.g. $f_1$, $f_2$, $2f_1/3+f_2/3$). To address the gap, this paper proposes a generalized approach, named multi-phase locking value (M-PLV), for the quantification of various types of instantaneous multi-frequency phase coupling. Different from most instantaneous phase coupling metrics that measure the simultaneous phase coupling, the proposed M-PLV method also allows the detection of delayed phase coupling and the associated time lag between coupled oscillators. The M-PLV has been tested on cases where synthetic coupled signals are generated using white Gaussian signals, and a system comprised of multiple coupled R\"ossler oscillators. Results indicate that the M-PLV can provide a reliable estimation of the time window and frequency combination where the phase coupling is significant, as well as a precise determination of time lag in the case of delayed coupling. This method has the potential to become a powerful new tool for exploring phase coupling in complex nonlinear dynamic systems.
AIM 2020 Challenge on Learned Image Signal Processing Pipeline
Nov 10, 2020
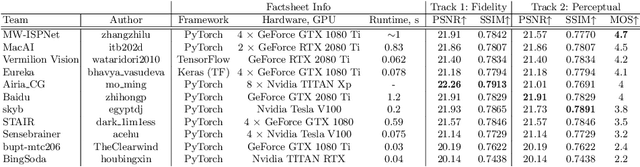
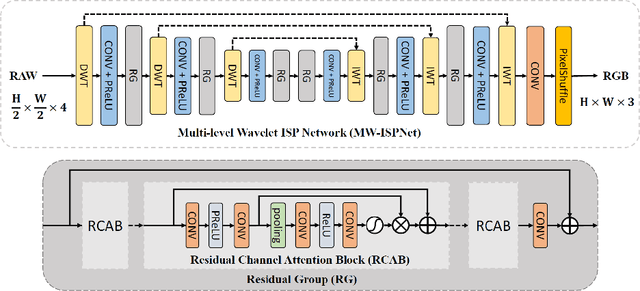
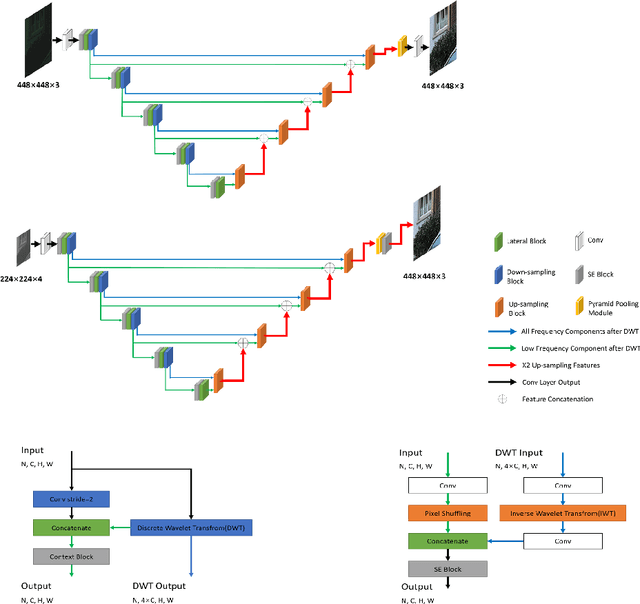
This paper reviews the second AIM learned ISP challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world RAW-to-RGB mapping problem, where to goal was to map the original low-quality RAW images captured by the Huawei P20 device to the same photos obtained with the Canon 5D DSLR camera. The considered task embraced a number of complex computer vision subtasks, such as image demosaicing, denoising, white balancing, color and contrast correction, demoireing, etc. The target metric used in this challenge combined fidelity scores (PSNR and SSIM) with solutions' perceptual results measured in a user study. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical image signal processing pipeline modeling.