 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccRobNet : Occlusion Robust Network for Accurate 3D Interacting Hand-Object Pose Estimation
Mar 27, 2025Occlusion is one of the challenging issues when estimating 3D hand pose. This problem becomes more prominent when hand interacts with an object or two hands are involved. In the past works, much attention has not been given to these occluded regions. But these regions contain important and beneficial information that is vital for 3D hand pose estimation. Thus, in this paper, we propose an occlusion robust and accurate method for the estimation of 3D hand-object pose from the input RGB image. Our method includes first localising the hand joints using a CNN based model and then refining them by extracting contextual information. The self attention transformer then identifies the specific joints along with the hand identity. This helps the model to identify the hand belongingness of a particular joint which helps to detect the joint even in the occluded region. Further, these joints with hand identity are then used to estimate the pose using cross attention mechanism. Thus, by identifying the joints in the occluded region, the obtained network becomes robust to occlusion. Hence, this network achieves state-of-the-art results when evaluated on the InterHand2.6M, HO3D and H$_2$O3D datasets.
Multiscaled Multi-Head Attention-based Video Transformer Network for Hand Gesture Recognition
Jan 01, 2025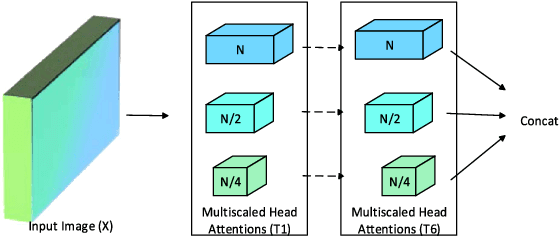



Dynamic gesture recognition is one of the challenging research areas due to variations in pose, size, and shape of the signer's hand. In this letter, Multiscaled Multi-Head Attention Video Transformer Network (MsMHA-VTN) for dynamic hand gesture recognition is proposed. A pyramidal hierarchy of multiscale features is extracted using the transformer multiscaled head attention model. The proposed model employs different attention dimensions for each head of the transformer which enables it to provide attention at the multiscale level. Further, in addition to single modality, recognition performance using multiple modalities is examined. Extensive experiments demonstrate the superior performance of the proposed MsMHA-VTN with an overall accuracy of 88.22\% and 99.10\% on NVGesture and Briareo datasets, respectively.
ConvMixFormer- A Resource-efficient Convolution Mixer for Transformer-based Dynamic Hand Gesture Recognition
Nov 11, 2024

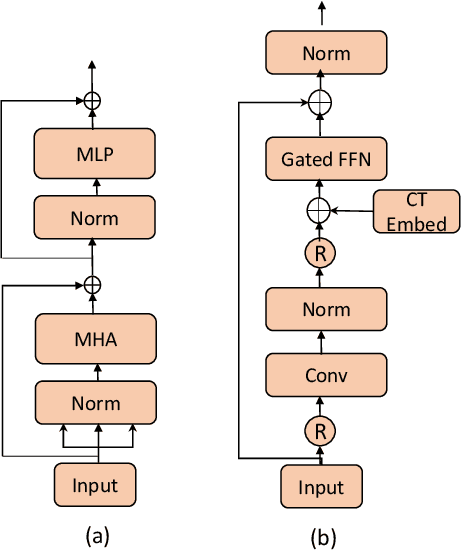
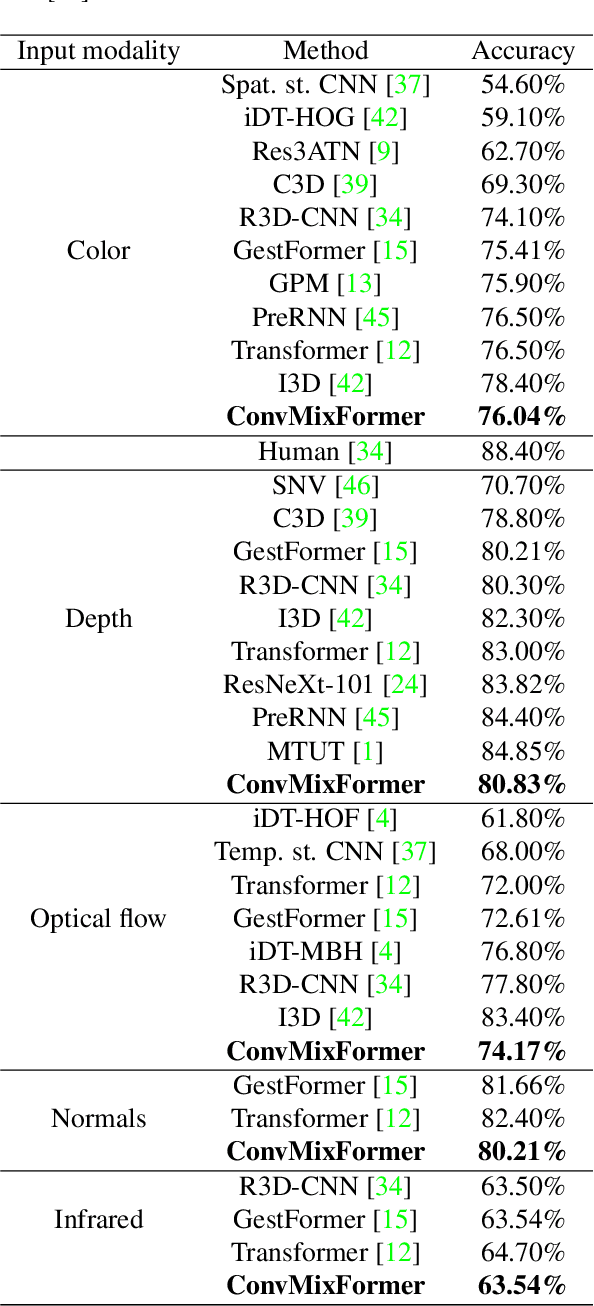
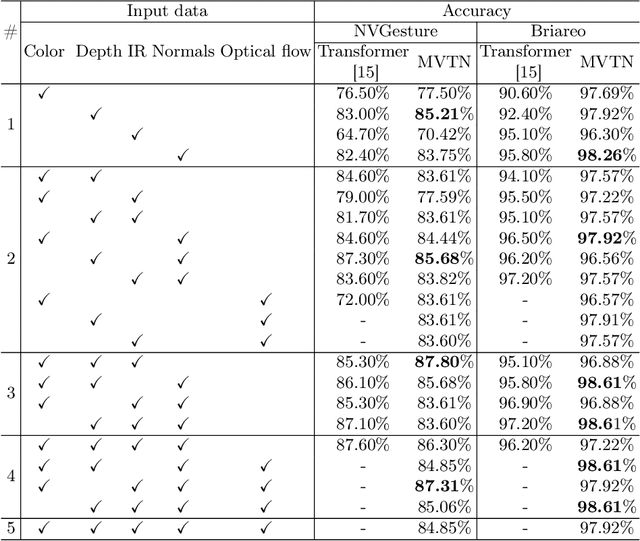
Transformer models have demonstrated remarkable success in many domains such as natural language processing (NLP) and computer vision. With the growing interest in transformer-based architectures, they are now utilized for gesture recognition. So, we also explore and devise a novel ConvMixFormer architecture for dynamic hand gestures. The transformers use quadratic scaling of the attention features with the sequential data, due to which these models are computationally complex and heavy. We have considered this drawback of the transformer and designed a resource-efficient model that replaces the self-attention in the transformer with the simple convolutional layer-based token mixer. The computational cost and the parameters used for the convolution-based mixer are comparatively less than the quadratic self-attention. Convolution-mixer helps the model capture the local spatial features that self-attention struggles to capture due to their sequential processing nature. Further, an efficient gate mechanism is employed instead of a conventional feed-forward network in the transformer to help the model control the flow of features within different stages of the proposed model. This design uses fewer learnable parameters which is nearly half the vanilla transformer that helps in fast and efficient training. The proposed method is evaluated on NVidia Dynamic Hand Gesture and Briareo datasets and our model has achieved state-of-the-art results on single and multimodal inputs. We have also shown the parameter efficiency of the proposed ConvMixFormer model compared to other methods. The source code is available at https://github.com/mallikagarg/ConvMixFormer.
MVTN: A Multiscale Video Transformer Network for Hand Gesture Recognition
Sep 05, 2024


In this paper, we introduce a novel Multiscale Video Transformer Network (MVTN) for dynamic hand gesture recognition, since multiscale features can extract features with variable size, pose, and shape of hand which is a challenge in hand gesture recognition. The proposed model incorporates a multiscale feature hierarchy to capture diverse levels of detail and context within hand gestures which enhances the model's ability. This multiscale hierarchy is obtained by extracting different dimensions of attention in different transformer stages with initial stages to model high-resolution features and later stages to model low-resolution features. Our approach also leverages multimodal data, utilizing depth maps, infrared data, and surface normals along with RGB images from NVGesture and Briareo datasets. Experiments show that the proposed MVTN achieves state-of-the-art results with less computational complexity and parameters. The source code is available at https://github.com/mallikagarg/MVTN.
GestFormer: Multiscale Wavelet Pooling Transformer Network for Dynamic Hand Gesture Recognition
May 18, 2024



Transformer model have achieved state-of-the-art results in many applications like NLP, classification, etc. But their exploration in gesture recognition task is still limited. So, we propose a novel GestFormer architecture for dynamic hand gesture recognition. The motivation behind this design is to propose a resource efficient transformer model, since transformers are computationally expensive and very complex. So, we propose to use a pooling based token mixer named PoolFormer, since it uses only pooling layer which is a non-parametric layer instead of quadratic attention. The proposed model also leverages the space-invariant features of the wavelet transform and also the multiscale features are selected using multi-scale pooling. Further, a gated mechanism helps to focus on fine details of the gesture with the contextual information. This enhances the performance of the proposed model compared to the traditional transformer with fewer parameters, when evaluated on dynamic hand gesture datasets, NVidia Dynamic Hand Gesture and Briareo datasets. To prove the efficacy of the proposed model, we have experimented on single as well multimodal inputs such as infrared, normals, depth, optical flow and color images. We have also compared the proposed GestFormer in terms of resource efficiency and number of operations. The source code is available at https://github.com/mallikagarg/GestFormer.
Co-VeGAN: Complex-Valued Generative Adversarial Network for Compressive Sensing MR Image Reconstruction
Feb 24, 2020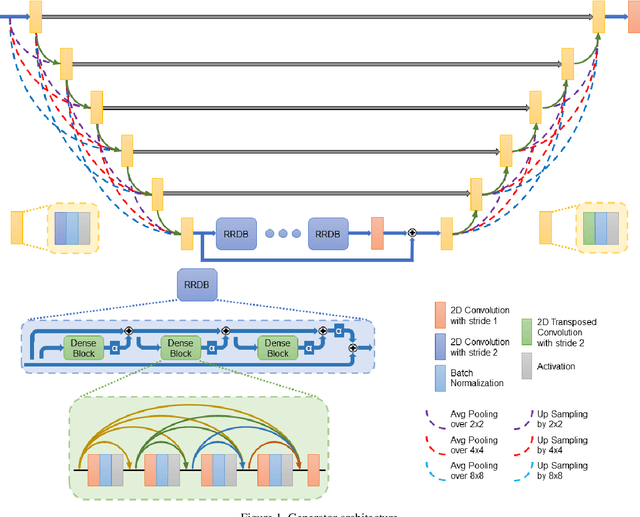
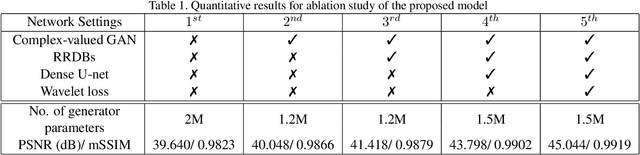
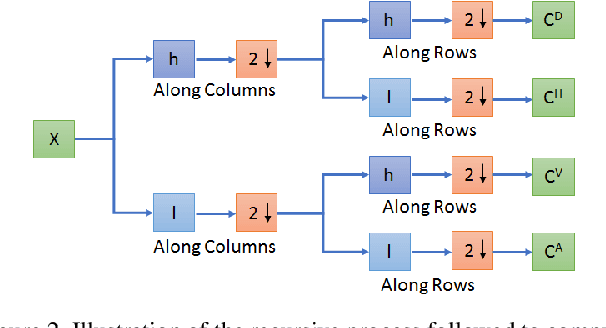
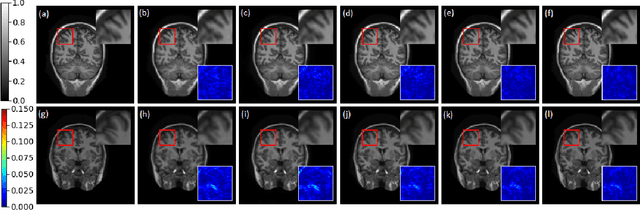
Compressive sensing (CS) is widely used to reduce the image acquisition time of magnetic resonance imaging (MRI). Though CS based undersampling has numerous benefits, like high quality images with less motion artefacts, low storage requirement, etc., the reconstruction of the image from the CS-undersampled data is an ill-posed inverse problem which requires extensive computation and resources. In this paper, we propose a novel deep network that can process complex-valued input to perform high-quality reconstruction. Our model is based on generative adversarial network (GAN) that uses residual-in-residual dense blocks in a modified U-net generator with patch based discriminator. We introduce a wavelet based loss in the complex GAN model for better reconstruction quality. Extensive analyses on different datasets demonstrate that the proposed model significantly outperforms the existing CS reconstruction techniques in terms of peak signal-to-noise ratio and structural similarity index.
Robust Compressive Sensing MRI Reconstruction using Generative Adversarial Networks
Oct 14, 2019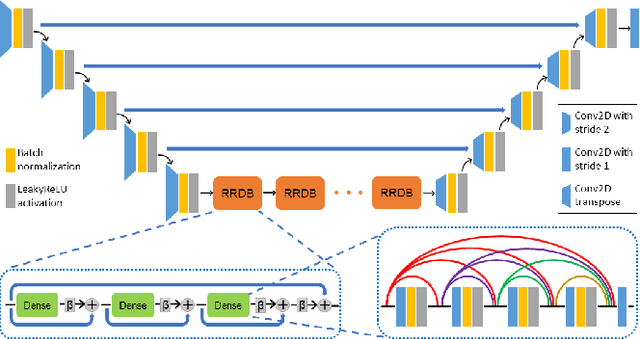
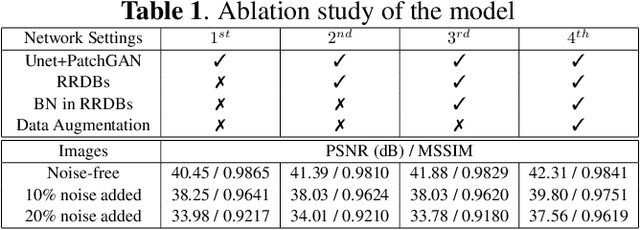
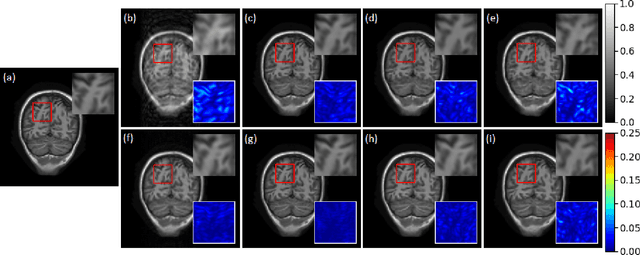
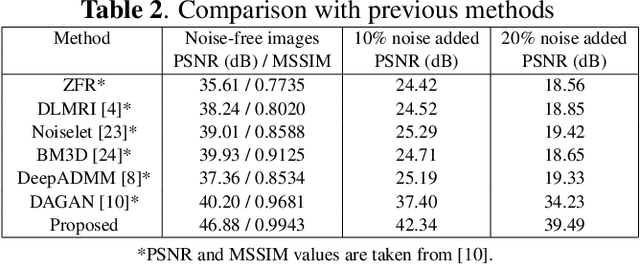
Compressive sensing magnetic resonance imaging (CS-MRI) accelerates the acquisition of MR images by breaking the Nyquist sampling limit. In this work, a novel generative adversarial network (GAN) based framework for CS-MRI reconstruction is proposed. Leveraging a combination of patchGAN discriminator and structural similarity index based loss, our model focuses on preserving high frequency content as well as fine textural details in the reconstructed image. Dense and residual connections have been incorporated in a U-net based generator architecture to allow easier transfer of information as well as variable network length. We show that our algorithm outperforms state-of-the-art methods in terms of quality of reconstruction and robustness to noise. Also, the reconstruction time, which is of the order of milliseconds, makes it highly suitable for real-time clinical use.