 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvMixFormer- A Resource-efficient Convolution Mixer for Transformer-based Dynamic Hand Gesture Recognition
Paper and Code


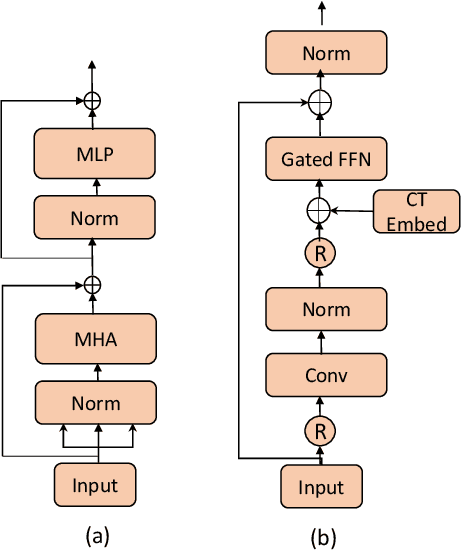
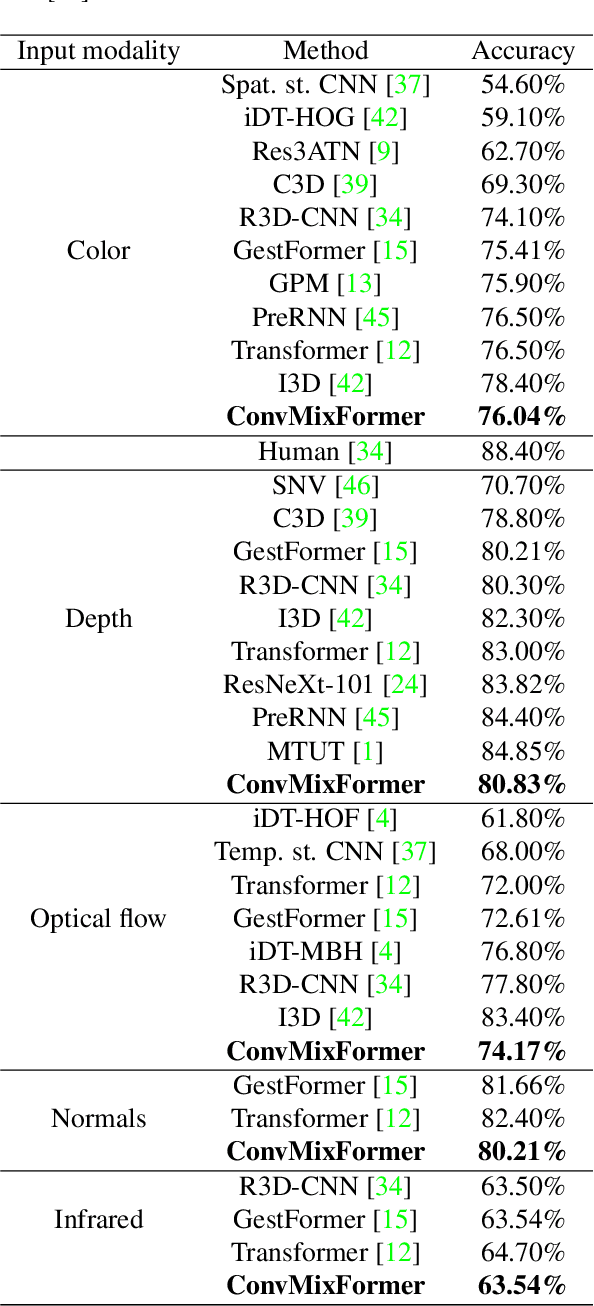
Transformer models have demonstrated remarkable success in many domains such as natural language processing (NLP) and computer vision. With the growing interest in transformer-based architectures, they are now utilized for gesture recognition. So, we also explore and devise a novel ConvMixFormer architecture for dynamic hand gestures. The transformers use quadratic scaling of the attention features with the sequential data, due to which these models are computationally complex and heavy. We have considered this drawback of the transformer and designed a resource-efficient model that replaces the self-attention in the transformer with the simple convolutional layer-based token mixer. The computational cost and the parameters used for the convolution-based mixer are comparatively less than the quadratic self-attention. Convolution-mixer helps the model capture the local spatial features that self-attention struggles to capture due to their sequential processing nature. Further, an efficient gate mechanism is employed instead of a conventional feed-forward network in the transformer to help the model control the flow of features within different stages of the proposed model. This design uses fewer learnable parameters which is nearly half the vanilla transformer that helps in fast and efficient training. The proposed method is evaluated on NVidia Dynamic Hand Gesture and Briareo datasets and our model has achieved state-of-the-art results on single and multimodal inputs. We have also shown the parameter efficiency of the proposed ConvMixFormer model compared to other methods. The source code is available at https://github.com/mallikagarg/ConvMixFormer.