 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Deblurring Using GANs
Jul 27, 2019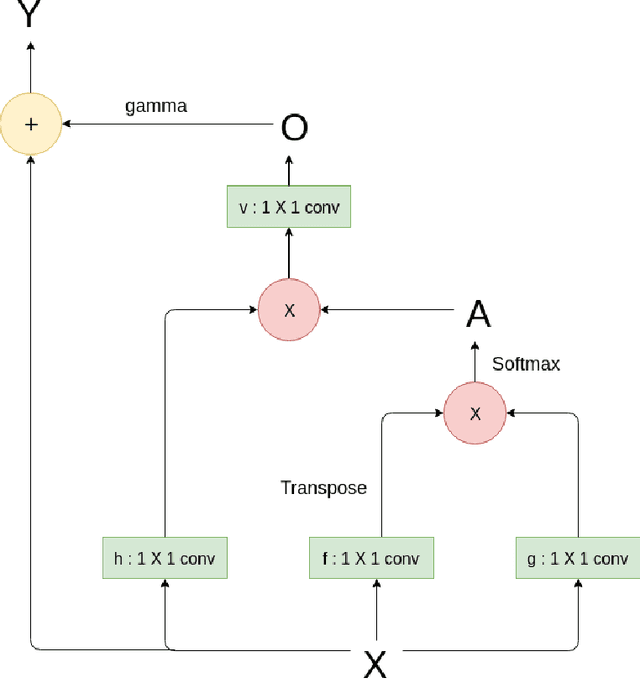

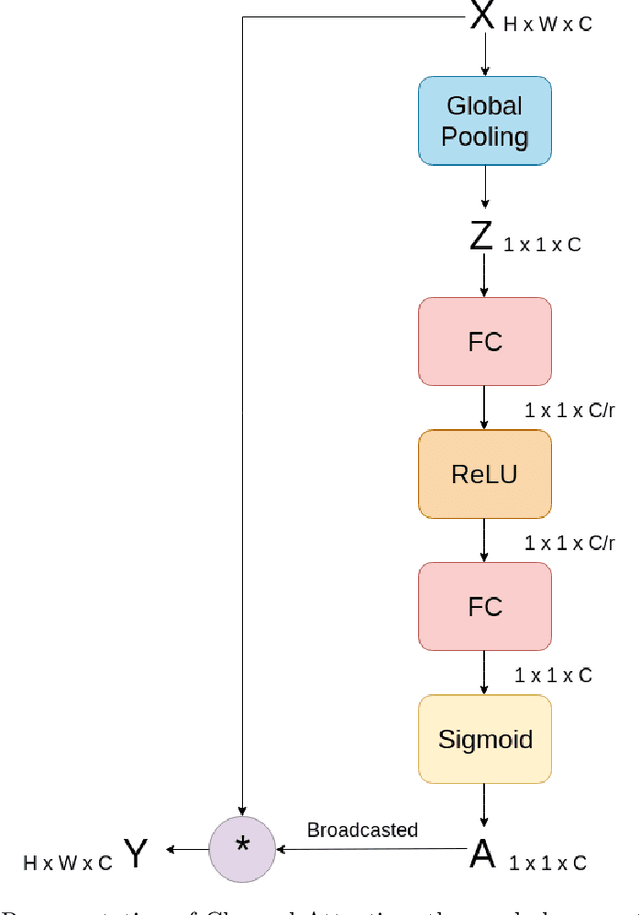

Deblurring is the task of restoring a blurred image to a sharp one, retrieving the information lost due to the blur. In blind deblurring we have no information regarding the blur kernel. As deblurring can be considered as an image to image translation task, deep learning based solutions, including the ones which use GAN (Generative Adversarial Network), have been proven effective for deblurring. Most of them have an encoder-decoder structure. Our objective is to try different GAN structures and improve its performance through various modifications to the existing structure for supervised deblurring. In supervised deblurring we have pairs of blurred and their corresponding sharp images, while in the unsupervised case we have a set of blurred and sharp images but their is no correspondence between them. Modifications to the structures is done to improve the global perception of the model. As blur is non-uniform in nature, for deblurring we require global information of the entire image, whereas convolution used in CNN is able to provide only local perception. Deep models can be used to improve global perception but due to large number of parameters it becomes difficult for it to converge and inference time increases, to solve this we propose the use of attention module (non-local block) which was previously used in language translation and other image to image translation tasks in deblurring. Use of residual connection also improves the performance of deblurring as features from the lower layers are added to the upper layers of the model. It has been found that classical losses like L1, L2, and perceptual loss also help in training of GANs when added together with adversarial loss. We also concatenate edge information of the image to observe its effects on deblurring. We also use feedback modules to retain long term dependencies
Blind Deblurring using Deep Learning: A Survey
Jul 23, 2019
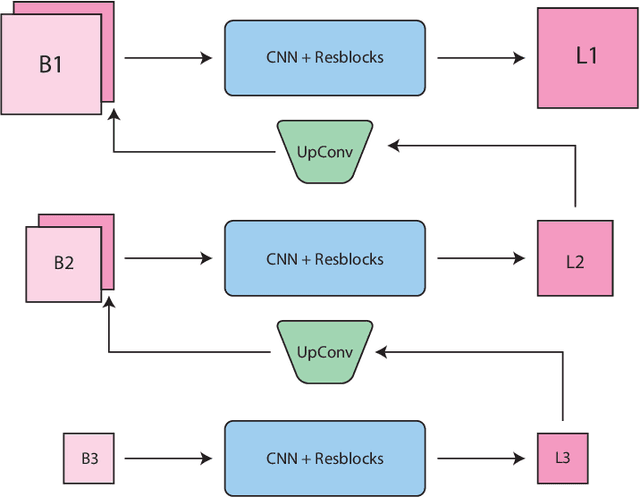
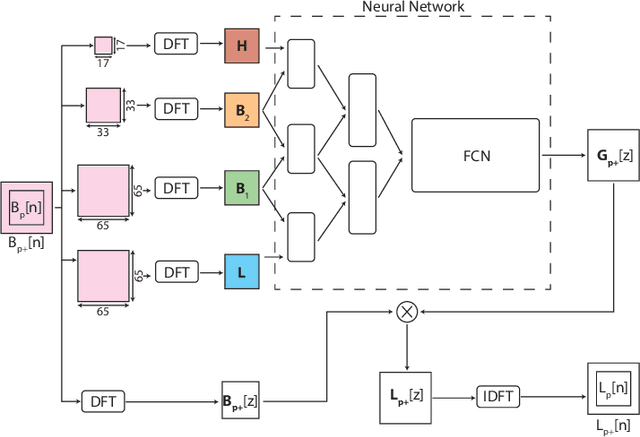
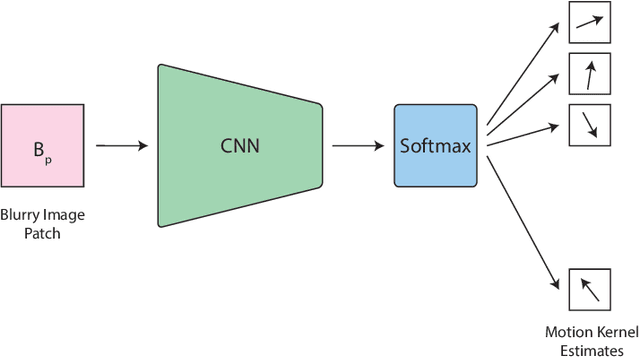
We inspect all the deep learning based solutions and provide holistic understanding of various architectures that have evolved over the past few years to solve blind deblurring. The introductory work used deep learning to estimate some features of the blur kernel and then moved onto predicting the blur kernel entirely, which converts the problem into non-blind deblurring. The recent state of the art techniques are end to end, i.e., they don't estimate the blur kernel rather try to estimate the latent sharp image directly from the blurred image. The benchmarking PSNR and SSIM values on standard datasets of GOPRO and Kohler using various architectures are also provided.