 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB-MoE: A Body-Part-Aware Mixture-of-Experts "All Parts Matter" Approach to Micro-Action Recognition
Mar 25, 2026Micro-actions, fleeting and low-amplitude motions, such as glances, nods, or minor posture shifts, carry rich social meaning but remain difficult for current action recognition models to recognize due to their subtlety, short duration, and high inter-class ambiguity. In this paper, we introduce B-MoE, a Body-part-aware Mixture-of-Experts framework designed to explicitly model the structured nature of human motion. In B-MoE, each expert specializes in a distinct body region (head, body, upper limbs, lower limbs), and is based on the lightweight Macro-Micro Motion Encoder (M3E) that captures long-range contextual structure and fine-grained local motion. A cross-attention routing mechanism learns inter-region relationships and dynamically selects the most informative regions for each micro-action. B-MoE uses a dual-stream encoder that fuses these region-specific semantic cues with global motion features to jointly capture spatially localized cues and temporally subtle variations that characterize micro-actions. Experiments on three challenging benchmarks (MA-52, SocialGesture, and MPII-GroupInteraction) show consistent state-of-theart gains, with improvements in ambiguous, underrepresented, and low amplitude classes.
MuSACo: Multimodal Subject-Specific Selection and Adaptation for Expression Recognition with Co-Training
Aug 17, 2025Personalized expression recognition (ER) involves adapting a machine learning model to subject-specific data for improved recognition of expressions with considerable interpersonal variability. Subject-specific ER can benefit significantly from multi-source domain adaptation (MSDA) methods, where each domain corresponds to a specific subject, to improve model accuracy and robustness. Despite promising results, state-of-the-art MSDA approaches often overlook multimodal information or blend sources into a single domain, limiting subject diversity and failing to explicitly capture unique subject-specific characteristics. To address these limitations, we introduce MuSACo, a multi-modal subject-specific selection and adaptation method for ER based on co-training. It leverages complementary information across multiple modalities and multiple source domains for subject-specific adaptation. This makes MuSACo particularly relevant for affective computing applications in digital health, such as patient-specific assessment for stress or pain, where subject-level nuances are crucial. MuSACo selects source subjects relevant to the target and generates pseudo-labels using the dominant modality for class-aware learning, in conjunction with a class-agnostic loss to learn from less confident target samples. Finally, source features from each modality are aligned, while only confident target features are combined. Our experimental results on challenging multimodal ER datasets: BioVid and StressID, show that MuSACo can outperform UDA (blending) and state-of-the-art MSDA methods.
LIA-X: Interpretable Latent Portrait Animator
Aug 13, 2025We introduce LIA-X, a novel interpretable portrait animator designed to transfer facial dynamics from a driving video to a source portrait with fine-grained control. LIA-X is an autoencoder that models motion transfer as a linear navigation of motion codes in latent space. Crucially, it incorporates a novel Sparse Motion Dictionary that enables the model to disentangle facial dynamics into interpretable factors. Deviating from previous 'warp-render' approaches, the interpretability of the Sparse Motion Dictionary allows LIA-X to support a highly controllable 'edit-warp-render' strategy, enabling precise manipulation of fine-grained facial semantics in the source portrait. This helps to narrow initial differences with the driving video in terms of pose and expression. Moreover, we demonstrate the scalability of LIA-X by successfully training a large-scale model with approximately 1 billion parameters on extensive datasets. Experimental results show that our proposed method outperforms previous approaches in both self-reenactment and cross-reenactment tasks across several benchmarks. Additionally, the interpretable and controllable nature of LIA-X supports practical applications such as fine-grained, user-guided image and video editing, as well as 3D-aware portrait video manipulation.
Just Dance with $π$! A Poly-modal Inductor for Weakly-supervised Video Anomaly Detection
May 19, 2025Weakly-supervised methods for video anomaly detection (VAD) are conventionally based merely on RGB spatio-temporal features, which continues to limit their reliability in real-world scenarios. This is due to the fact that RGB-features are not sufficiently distinctive in setting apart categories such as shoplifting from visually similar events. Therefore, towards robust complex real-world VAD, it is essential to augment RGB spatio-temporal features by additional modalities. Motivated by this, we introduce the Poly-modal Induced framework for VAD: "PI-VAD", a novel approach that augments RGB representations by five additional modalities. Specifically, the modalities include sensitivity to fine-grained motion (Pose), three dimensional scene and entity representation (Depth), surrounding objects (Panoptic masks), global motion (optical flow), as well as language cues (VLM). Each modality represents an axis of a polygon, streamlined to add salient cues to RGB. PI-VAD includes two plug-in modules, namely Pseudo-modality Generation module and Cross Modal Induction module, which generate modality-specific prototypical representation and, thereby, induce multi-modal information into RGB cues. These modules operate by performing anomaly-aware auxiliary tasks and necessitate five modality backbones -- only during training. Notably, PI-VAD achieves state-of-the-art accuracy on three prominent VAD datasets encompassing real-world scenarios, without requiring the computational overhead of five modality backbones at inference.
SKI Models: Skeleton Induced Vision-Language Embeddings for Understanding Activities of Daily Living
Feb 05, 2025



The introduction of vision-language models like CLIP has enabled the development of foundational video models capable of generalizing to unseen videos and human actions. However, these models are typically trained on web videos, which often fail to capture the challenges present in Activities of Daily Living (ADL) videos. Existing works address ADL-specific challenges, such as similar appearances, subtle motion patterns, and multiple viewpoints, by combining 3D skeletons and RGB videos. However, these approaches are not integrated with language, limiting their ability to generalize to unseen action classes. In this paper, we introduce SKI models, which integrate 3D skeletons into the vision-language embedding space. SKI models leverage a skeleton-language model, SkeletonCLIP, to infuse skeleton information into Vision Language Models (VLMs) and Large Vision Language Models (LVLMs) through collaborative training. Notably, SKI models do not require skeleton data during inference, enhancing their robustness for real-world applications. The effectiveness of SKI models is validated on three popular ADL datasets for zero-shot action recognition and video caption generation tasks.
CM3T: Framework for Efficient Multimodal Learning for Inhomogeneous Interaction Datasets
Jan 06, 2025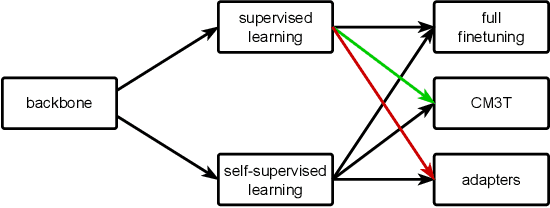
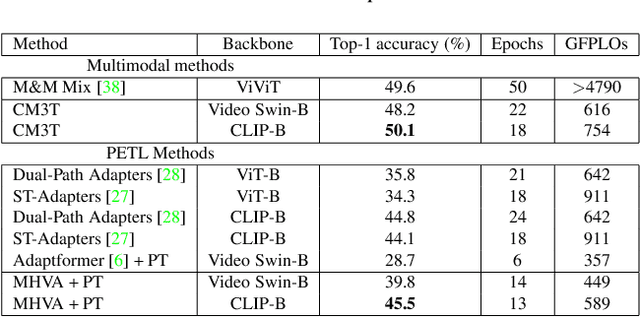
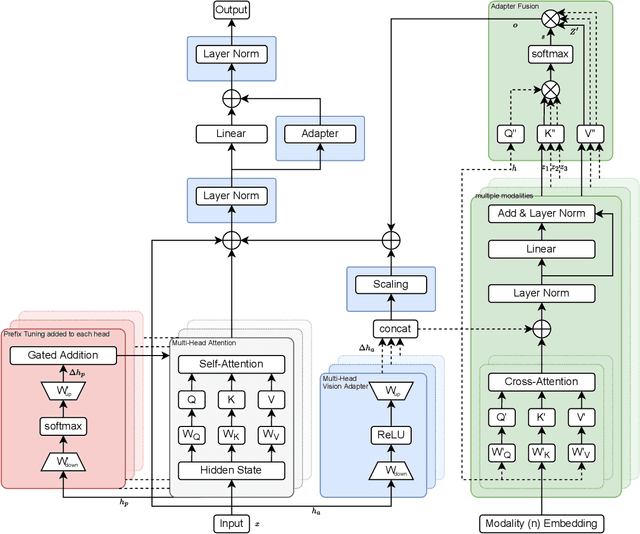
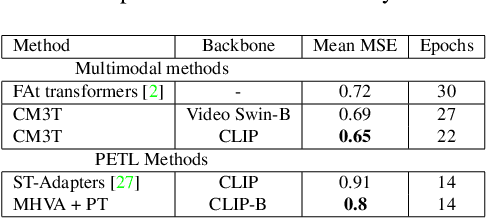
Challenges in cross-learning involve inhomogeneous or even inadequate amount of training data and lack of resources for retraining large pretrained models. Inspired by transfer learning techniques in NLP, adapters and prefix tuning, this paper presents a new model-agnostic plugin architecture for cross-learning, called CM3T, that adapts transformer-based models to new or missing information. We introduce two adapter blocks: multi-head vision adapters for transfer learning and cross-attention adapters for multimodal learning. Training becomes substantially efficient as the backbone and other plugins do not need to be finetuned along with these additions. Comparative and ablation studies on three datasets Epic-Kitchens-100, MPIIGroupInteraction and UDIVA v0.5 show efficacy of this framework on different recording settings and tasks. With only 12.8% trainable parameters compared to the backbone to process video input and only 22.3% trainable parameters for two additional modalities, we achieve comparable and even better results than the state-of-the-art. CM3T has no specific requirements for training or pretraining and is a step towards bridging the gap between a general model and specific practical applications of video classification.
Identifying Surgical Instruments in Pedagogical Cataract Surgery Videos through an Optimized Aggregation Network
Jan 05, 2025Instructional cataract surgery videos are crucial for ophthalmologists and trainees to observe surgical details repeatedly. This paper presents a deep learning model for real-time identification of surgical instruments in these videos, using a custom dataset scraped from open-access sources. Inspired by the architecture of YOLOV9, the model employs a Programmable Gradient Information (PGI) mechanism and a novel Generally-Optimized Efficient Layer Aggregation Network (Go-ELAN) to address the information bottleneck problem, enhancing Minimum Average Precision (mAP) at higher Non-Maximum Suppression Intersection over Union (NMS IoU) scores. The Go-ELAN YOLOV9 model, evaluated against YOLO v5, v7, v8, v9 vanilla, Laptool and DETR, achieves a superior mAP of 73.74 at IoU 0.5 on a dataset of 615 images with 10 instrument classes, demonstrating the effectiveness of the proposed model.
Anti-Forgetting Adaptation for Unsupervised Person Re-identification
Nov 22, 2024



Regular unsupervised domain adaptive person re-identification (ReID) focuses on adapting a model from a source domain to a fixed target domain. However, an adapted ReID model can hardly retain previously-acquired knowledge and generalize to unseen data. In this paper, we propose a Dual-level Joint Adaptation and Anti-forgetting (DJAA) framework, which incrementally adapts a model to new domains without forgetting source domain and each adapted target domain. We explore the possibility of using prototype and instance-level consistency to mitigate the forgetting during the adaptation. Specifically, we store a small number of representative image samples and corresponding cluster prototypes in a memory buffer, which is updated at each adaptation step. With the buffered images and prototypes, we regularize the image-to-image similarity and image-to-prototype similarity to rehearse old knowledge. After the multi-step adaptation, the model is tested on all seen domains and several unseen domains to validate the generalization ability of our method. Extensive experiments demonstrate that our proposed method significantly improves the anti-forgetting, generalization and backward-compatible ability of an unsupervised person ReID model.
AM Flow: Adapters for Temporal Processing in Action Recognition
Nov 04, 2024



Deep learning models, in particular \textit{image} models, have recently gained generalisability and robustness. %are becoming more general and robust by the day. In this work, we propose to exploit such advances in the realm of \textit{video} classification. Video foundation models suffer from the requirement of extensive pretraining and a large training time. Towards mitigating such limitations, we propose "\textit{Attention Map (AM) Flow}" for image models, a method for identifying pixels relevant to motion in each input video frame. In this context, we propose two methods to compute AM flow, depending on camera motion. AM flow allows the separation of spatial and temporal processing, while providing improved results over combined spatio-temporal processing (as in video models). Adapters, one of the popular techniques in parameter efficient transfer learning, facilitate the incorporation of AM flow into pretrained image models, mitigating the need for full-finetuning. We extend adapters to "\textit{temporal processing adapters}" by incorporating a temporal processing unit into the adapters. Our work achieves faster convergence, therefore reducing the number of epochs needed for training. Moreover, we endow an image model with the ability to achieve state-of-the-art results on popular action recognition datasets. This reduces training time and simplifies pretraining. We present experiments on Kinetics-400, Something-Something v2, and Toyota Smarthome datasets, showcasing state-of-the-art or comparable results.
Loose Social-Interaction Recognition in Real-world Therapy Scenarios
Sep 30, 2024



The computer vision community has explored dyadic interactions for atomic actions such as pushing, carrying-object, etc. However, with the advancement in deep learning models, there is a need to explore more complex dyadic situations such as loose interactions. These are interactions where two people perform certain atomic activities to complete a global action irrespective of temporal synchronisation and physical engagement, like cooking-together for example. Analysing these types of dyadic-interactions has several useful applications in the medical domain for social-skills development and mental health diagnosis. To achieve this, we propose a novel dual-path architecture to capture the loose interaction between two individuals. Our model learns global abstract features from each stream via a CNNs backbone and fuses them using a new Global-Layer-Attention module based on a cross-attention strategy. We evaluate our model on real-world autism diagnoses such as our Loose-Interaction dataset, and the publicly available Autism dataset for loose interactions. Our network achieves baseline results on the Loose-Interaction and SOTA results on the Autism datasets. Moreover, we study different social interactions by experimenting on a publicly available dataset i.e. NTU-RGB+D (interactive classes from both NTU-60 and NTU-120). We have found that different interactions require different network designs. We also compare a slightly different version of our method by incorporating time information to address tight interactions achieving SOTA results.