 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCM3T: Framework for Efficient Multimodal Learning for Inhomogeneous Interaction Datasets
Jan 06, 2025
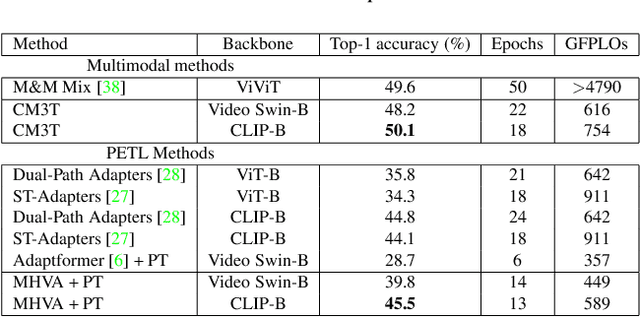
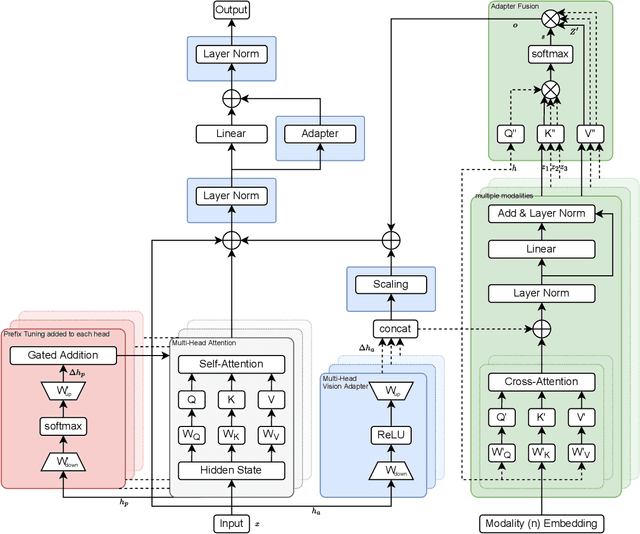
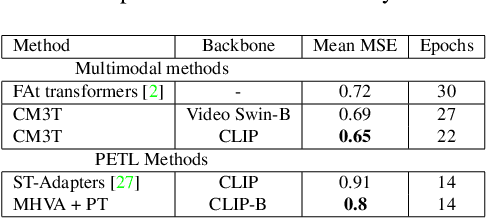
Challenges in cross-learning involve inhomogeneous or even inadequate amount of training data and lack of resources for retraining large pretrained models. Inspired by transfer learning techniques in NLP, adapters and prefix tuning, this paper presents a new model-agnostic plugin architecture for cross-learning, called CM3T, that adapts transformer-based models to new or missing information. We introduce two adapter blocks: multi-head vision adapters for transfer learning and cross-attention adapters for multimodal learning. Training becomes substantially efficient as the backbone and other plugins do not need to be finetuned along with these additions. Comparative and ablation studies on three datasets Epic-Kitchens-100, MPIIGroupInteraction and UDIVA v0.5 show efficacy of this framework on different recording settings and tasks. With only 12.8% trainable parameters compared to the backbone to process video input and only 22.3% trainable parameters for two additional modalities, we achieve comparable and even better results than the state-of-the-art. CM3T has no specific requirements for training or pretraining and is a step towards bridging the gap between a general model and specific practical applications of video classification.
AM Flow: Adapters for Temporal Processing in Action Recognition
Nov 04, 2024



Deep learning models, in particular \textit{image} models, have recently gained generalisability and robustness. %are becoming more general and robust by the day. In this work, we propose to exploit such advances in the realm of \textit{video} classification. Video foundation models suffer from the requirement of extensive pretraining and a large training time. Towards mitigating such limitations, we propose "\textit{Attention Map (AM) Flow}" for image models, a method for identifying pixels relevant to motion in each input video frame. In this context, we propose two methods to compute AM flow, depending on camera motion. AM flow allows the separation of spatial and temporal processing, while providing improved results over combined spatio-temporal processing (as in video models). Adapters, one of the popular techniques in parameter efficient transfer learning, facilitate the incorporation of AM flow into pretrained image models, mitigating the need for full-finetuning. We extend adapters to "\textit{temporal processing adapters}" by incorporating a temporal processing unit into the adapters. Our work achieves faster convergence, therefore reducing the number of epochs needed for training. Moreover, we endow an image model with the ability to achieve state-of-the-art results on popular action recognition datasets. This reduces training time and simplifies pretraining. We present experiments on Kinetics-400, Something-Something v2, and Toyota Smarthome datasets, showcasing state-of-the-art or comparable results.
Multimodal Vision Transformers with Forced Attention for Behavior Analysis
Dec 07, 2022Human behavior understanding requires looking at minute details in the large context of a scene containing multiple input modalities. It is necessary as it allows the design of more human-like machines. While transformer approaches have shown great improvements, they face multiple challenges such as lack of data or background noise. To tackle these, we introduce the Forced Attention (FAt) Transformer which utilize forced attention with a modified backbone for input encoding and a use of additional inputs. In addition to improving the performance on different tasks and inputs, the modification requires less time and memory resources. We provide a model for a generalised feature extraction for tasks concerning social signals and behavior analysis. Our focus is on understanding behavior in videos where people are interacting with each other or talking into the camera which simulates the first person point of view in social interaction. FAt Transformers are applied to two downstream tasks: personality recognition and body language recognition. We achieve state-of-the-art results for Udiva v0.5, First Impressions v2 and MPII Group Interaction datasets. We further provide an extensive ablation study of the proposed architecture.
Multimodal Personality Recognition using Cross-Attention Transformer and Behaviour Encoding
Dec 22, 2021
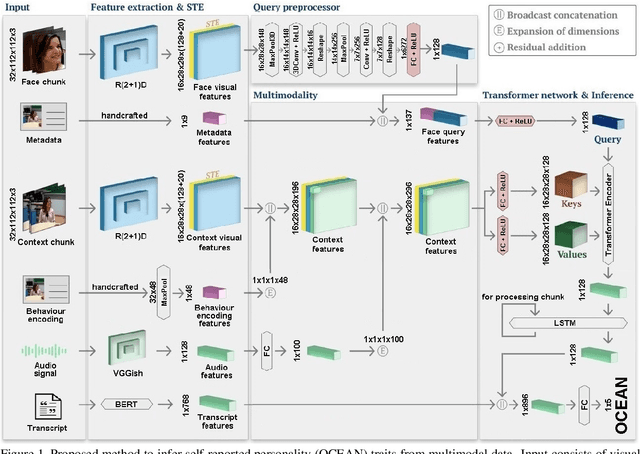
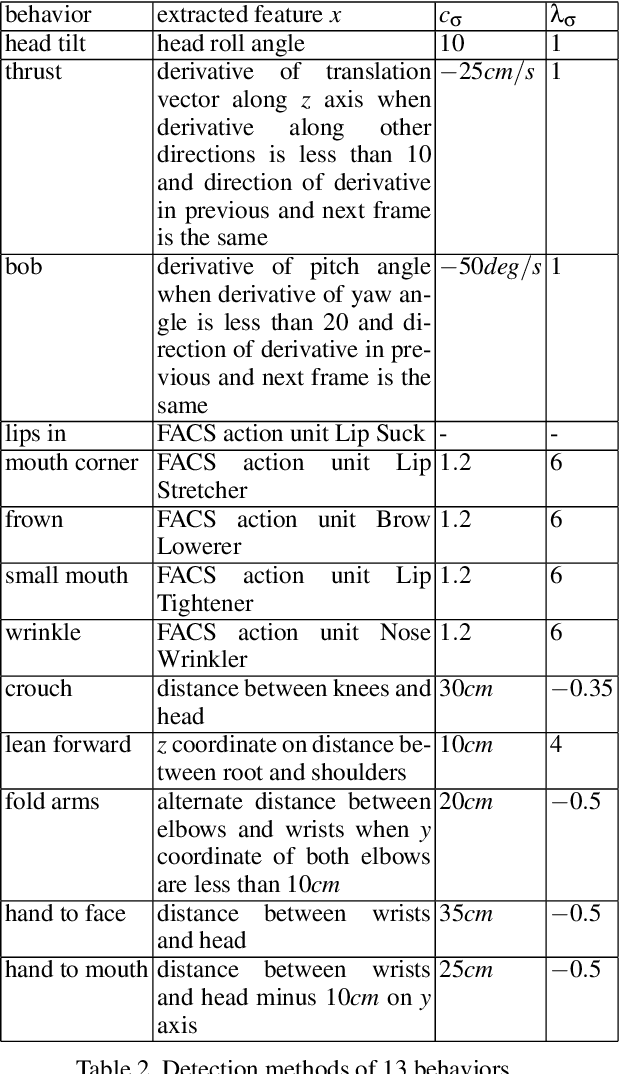
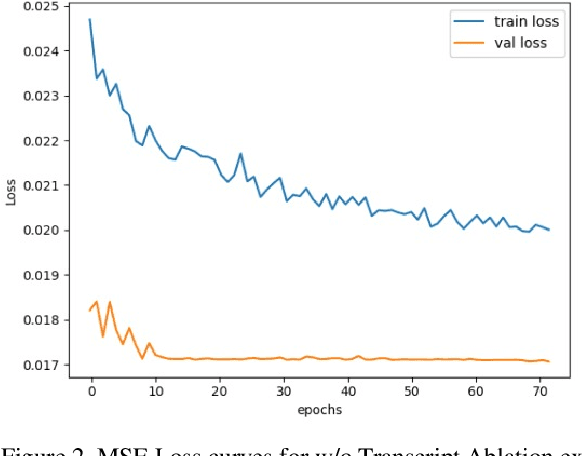
Personality computing and affective computing have gained recent interest in many research areas. The datasets for the task generally have multiple modalities like video, audio, language and bio-signals. In this paper, we propose a flexible model for the task which exploits all available data. The task involves complex relations and to avoid using a large model for video processing specifically, we propose the use of behaviour encoding which boosts performance with minimal change to the model. Cross-attention using transformers has become popular in recent times and is utilised for fusion of different modalities. Since long term relations may exist, breaking the input into chunks is not desirable, thus the proposed model processes the entire input together. Our experiments show the importance of each of the above contributions
From Multimodal to Unimodal Attention in Transformers using Knowledge Distillation
Oct 19, 2021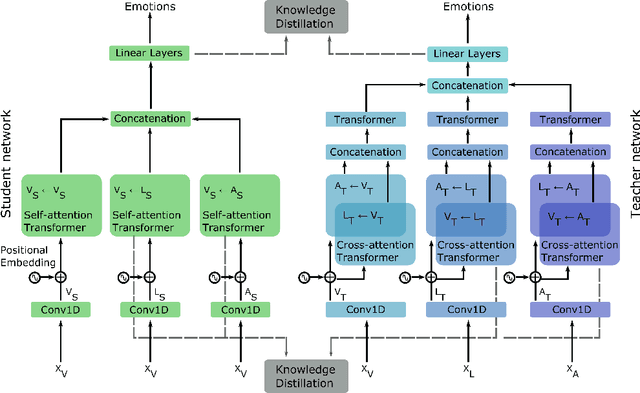
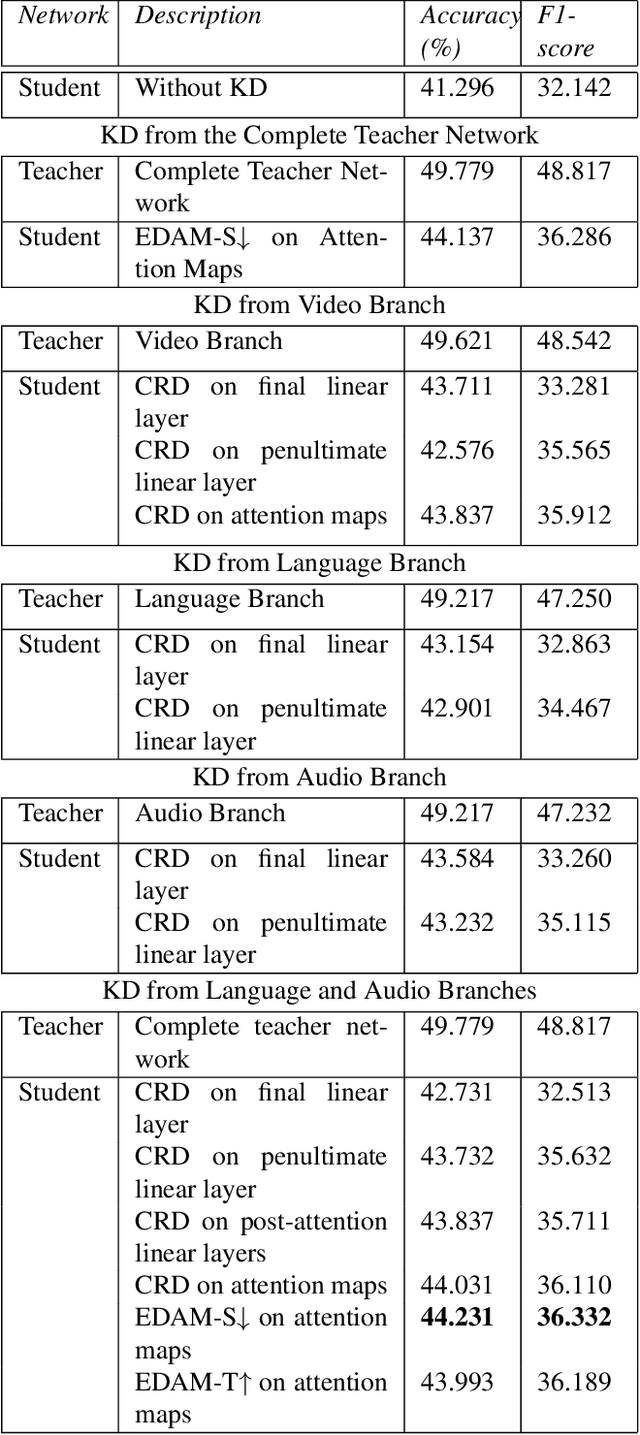
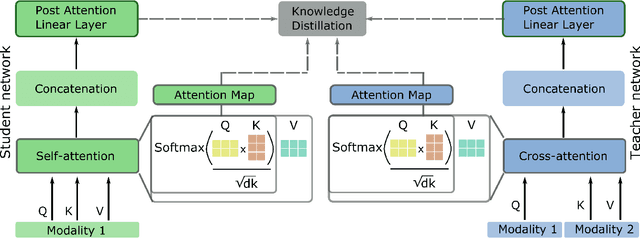

Multimodal Deep Learning has garnered much interest, and transformers have triggered novel approaches, thanks to the cross-attention mechanism. Here we propose an approach to deal with two key existing challenges: the high computational resource demanded and the issue of missing modalities. We introduce for the first time the concept of knowledge distillation in transformers to use only one modality at inference time. We report a full study analyzing multiple student-teacher configurations, levels at which distillation is applied, and different methodologies. With the best configuration, we improved the state-of-the-art accuracy by 3%, we reduced the number of parameters by 2.5 times and the inference time by 22%. Such performance-computation tradeoff can be exploited in many applications and we aim at opening a new research area where the deployment of complex models with limited resources is demanded.