 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQA-prompting: Improving Summarization with Large Language Models using Question-Answering
May 20, 2025



Language Models (LMs) have revolutionized natural language processing, enabling high-quality text generation through prompting and in-context learning. However, models often struggle with long-context summarization due to positional biases, leading to suboptimal extraction of critical information. There are techniques to improve this with fine-tuning, pipelining, or using complex techniques, which have their own challenges. To solve these challenges, we propose QA-prompting - a simple prompting method for summarization that utilizes question-answering as an intermediate step prior to summary generation. Our method extracts key information and enriches the context of text to mitigate positional biases and improve summarization in a single LM call per task without requiring fine-tuning or pipelining. Experiments on multiple datasets belonging to different domains using ten state-of-the-art pre-trained models demonstrate that QA-prompting outperforms baseline and other state-of-the-art methods, achieving up to 29% improvement in ROUGE scores. This provides an effective and scalable solution for summarization and highlights the importance of domain-specific question selection for optimal performance.
Guiding Vision-Language Model Selection for Visual Question-Answering Across Tasks, Domains, and Knowledge Types
Sep 14, 2024Visual Question-Answering (VQA) has become a key use-case in several applications to aid user experience, particularly after Vision-Language Models (VLMs) achieving good results in zero-shot inference. But evaluating different VLMs for an application requirement using a standardized framework in practical settings is still challenging. This paper introduces a comprehensive framework for evaluating VLMs tailored to VQA tasks in practical settings. We present a novel dataset derived from established VQA benchmarks, annotated with task types, application domains, and knowledge types, three key practical aspects on which tasks can vary. We also introduce GoEval, a multimodal evaluation metric developed using GPT-4o, achieving a correlation factor of 56.71% with human judgments. Our experiments with ten state-of-the-art VLMs reveals that no single model excelling universally, making appropriate selection a key design decision. Proprietary models such as Gemini-1.5-Pro and GPT-4o-mini generally outperform others, though open-source models like InternVL-2-8B and CogVLM-2-Llama-3-19B demonstrate competitive strengths in specific contexts, while providing additional advantages. This study guides the selection of VLMs based on specific task requirements and resource constraints, and can also be extended to other vision-language tasks.
Evaluating Open Language Models Across Task Types, Application Domains, and Reasoning Types: An In-Depth Experimental Analysis
Jun 17, 2024



The rapid rise of Language Models (LMs) has expanded their use in several applications. Yet, due to constraints of model size, associated cost, or proprietary restrictions, utilizing state-of-the-art (SOTA) LLMs is not always feasible. With open, smaller LMs emerging, more applications can leverage their capabilities, but selecting the right LM can be challenging. This work conducts an in-depth experimental analysis of the semantic correctness of outputs of 10 smaller, open LMs across three aspects: task types, application domains and reasoning types, using diverse prompt styles. We demonstrate that most effective models and prompt styles vary depending on the specific requirements. Our analysis provides a comparative assessment of LMs and prompt styles using a proposed three-tier schema of aspects for their strategic selection based on use-case and other constraints. We also show that if utilized appropriately, these LMs can compete with, and sometimes outperform, SOTA LLMs like DeepSeek-v2, GPT-3.5-Turbo, and GPT-4o.
Multimodal Personality Recognition using Cross-Attention Transformer and Behaviour Encoding
Dec 22, 2021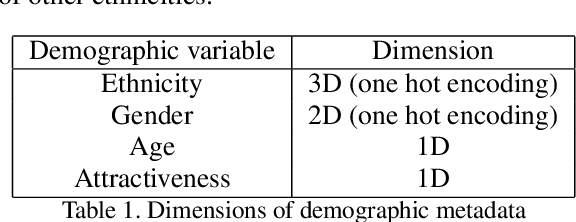
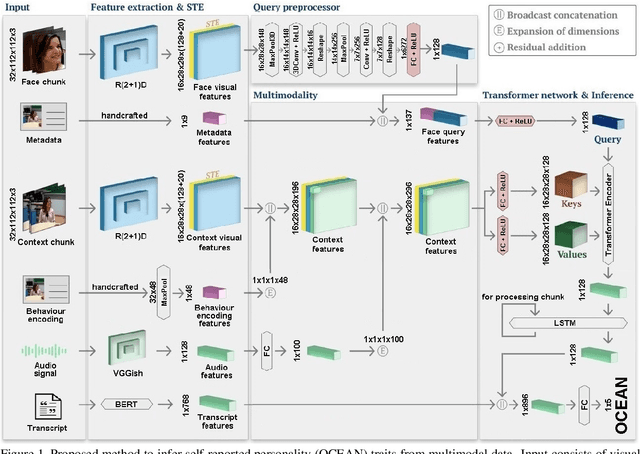
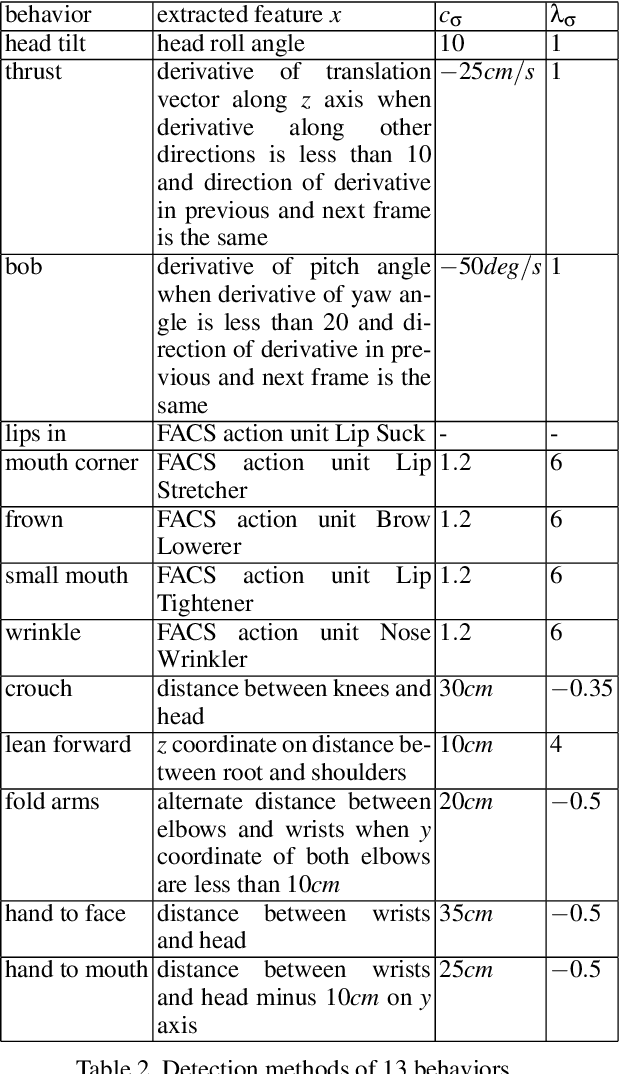
Personality computing and affective computing have gained recent interest in many research areas. The datasets for the task generally have multiple modalities like video, audio, language and bio-signals. In this paper, we propose a flexible model for the task which exploits all available data. The task involves complex relations and to avoid using a large model for video processing specifically, we propose the use of behaviour encoding which boosts performance with minimal change to the model. Cross-attention using transformers has become popular in recent times and is utilised for fusion of different modalities. Since long term relations may exist, breaking the input into chunks is not desirable, thus the proposed model processes the entire input together. Our experiments show the importance of each of the above contributions
FLAME: Facial Landmark Heatmap Activated Multimodal Gaze Estimation
Oct 10, 2021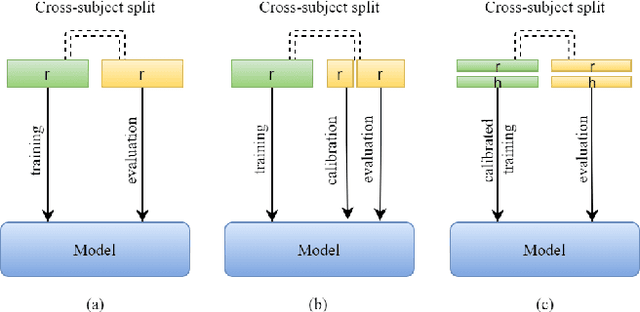

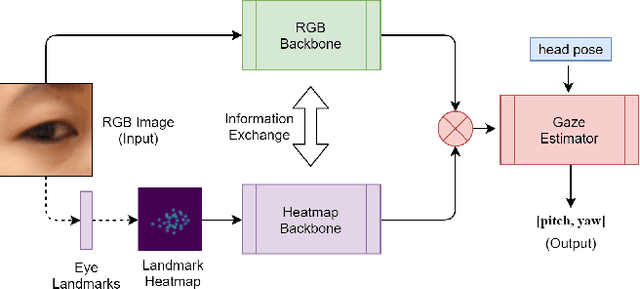
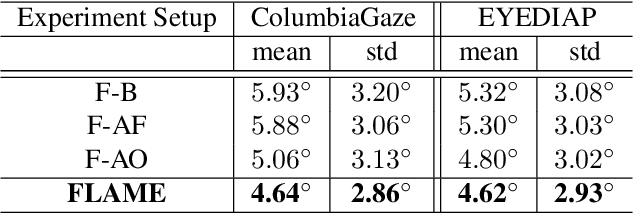
3D gaze estimation is about predicting the line of sight of a person in 3D space. Person-independent models for the same lack precision due to anatomical differences of subjects, whereas person-specific calibrated techniques add strict constraints on scalability. To overcome these issues, we propose a novel technique, Facial Landmark Heatmap Activated Multimodal Gaze Estimation (FLAME), as a way of combining eye anatomical information using eye landmark heatmaps to obtain precise gaze estimation without any person-specific calibration. Our evaluation demonstrates a competitive performance of about 10% improvement on benchmark datasets ColumbiaGaze and EYEDIAP. We also conduct an ablation study to validate our method.