 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Experts Guided by Gaussian Splatters Matters: A new Approach to Weakly-Supervised Video Anomaly Detection
Aug 08, 2025Video Anomaly Detection (VAD) is a challenging task due to the variability of anomalous events and the limited availability of labeled data. Under the Weakly-Supervised VAD (WSVAD) paradigm, only video-level labels are provided during training, while predictions are made at the frame level. Although state-of-the-art models perform well on simple anomalies (e.g., explosions), they struggle with complex real-world events (e.g., shoplifting). This difficulty stems from two key issues: (1) the inability of current models to address the diversity of anomaly types, as they process all categories with a shared model, overlooking category-specific features; and (2) the weak supervision signal, which lacks precise temporal information, limiting the ability to capture nuanced anomalous patterns blended with normal events. To address these challenges, we propose Gaussian Splatting-guided Mixture of Experts (GS-MoE), a novel framework that employs a set of expert models, each specialized in capturing specific anomaly types. These experts are guided by a temporal Gaussian splatting loss, enabling the model to leverage temporal consistency and enhance weak supervision. The Gaussian splatting approach encourages a more precise and comprehensive representation of anomalies by focusing on temporal segments most likely to contain abnormal events. The predictions from these specialized experts are integrated through a mixture-of-experts mechanism to model complex relationships across diverse anomaly patterns. Our approach achieves state-of-the-art performance, with a 91.58% AUC on the UCF-Crime dataset, and demonstrates superior results on XD-Violence and MSAD datasets. By leveraging category-specific expertise and temporal guidance, GS-MoE sets a new benchmark for VAD under weak supervision.
From Multimodal to Unimodal Attention in Transformers using Knowledge Distillation
Oct 19, 2021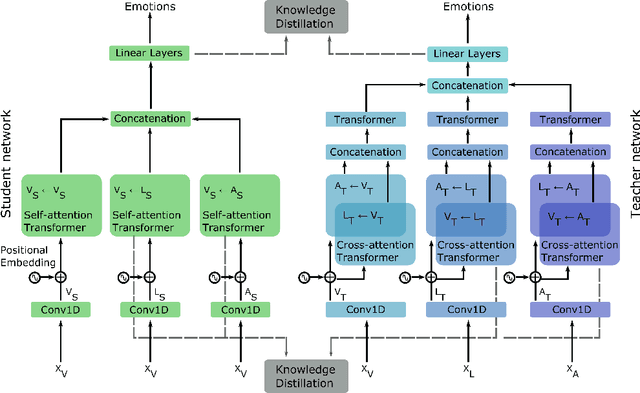
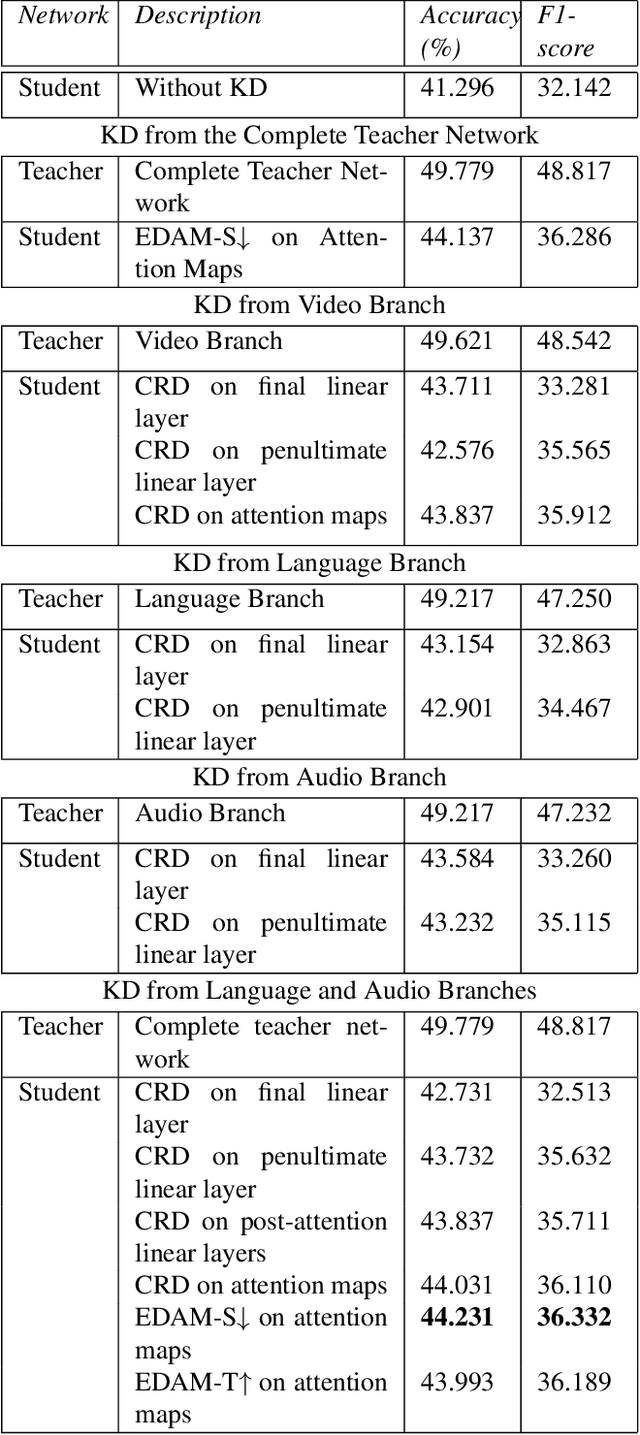
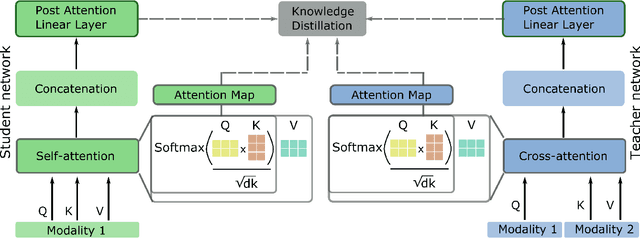

Multimodal Deep Learning has garnered much interest, and transformers have triggered novel approaches, thanks to the cross-attention mechanism. Here we propose an approach to deal with two key existing challenges: the high computational resource demanded and the issue of missing modalities. We introduce for the first time the concept of knowledge distillation in transformers to use only one modality at inference time. We report a full study analyzing multiple student-teacher configurations, levels at which distillation is applied, and different methodologies. With the best configuration, we improved the state-of-the-art accuracy by 3%, we reduced the number of parameters by 2.5 times and the inference time by 22%. Such performance-computation tradeoff can be exploited in many applications and we aim at opening a new research area where the deployment of complex models with limited resources is demanded.
FLAME: Facial Landmark Heatmap Activated Multimodal Gaze Estimation
Oct 10, 2021

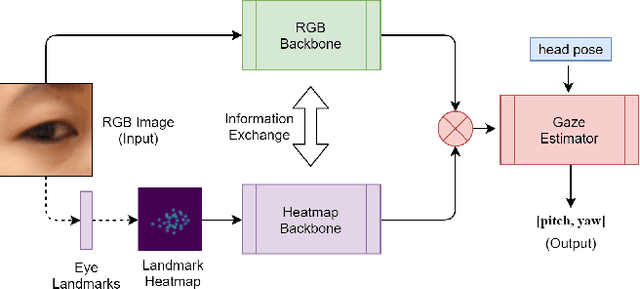
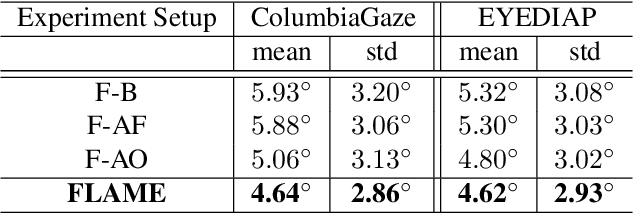
3D gaze estimation is about predicting the line of sight of a person in 3D space. Person-independent models for the same lack precision due to anatomical differences of subjects, whereas person-specific calibrated techniques add strict constraints on scalability. To overcome these issues, we propose a novel technique, Facial Landmark Heatmap Activated Multimodal Gaze Estimation (FLAME), as a way of combining eye anatomical information using eye landmark heatmaps to obtain precise gaze estimation without any person-specific calibration. Our evaluation demonstrates a competitive performance of about 10% improvement on benchmark datasets ColumbiaGaze and EYEDIAP. We also conduct an ablation study to validate our method.
One-class Autoencoder Approach for Optimal Electrode Set-up Identification in Wearable EEG Event Monitoring
Apr 13, 2021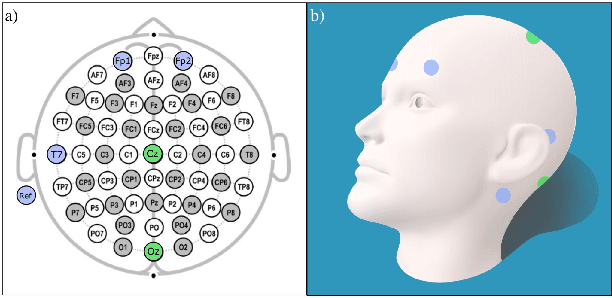
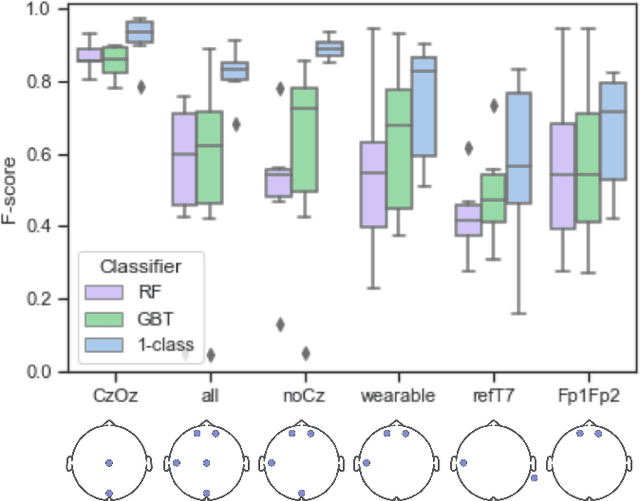

A limiting factor towards the wide routine use of wearables devices for continuous healthcare monitoring is their cumbersome and obtrusive nature. This is particularly true for electroencephalography (EEG) recordings, which require the placement of multiple electrodes in contact with the scalp. In this work, we propose to identify the optimal wearable EEG electrode set-up, in terms of minimal number of electrodes, comfortable location and performance, for EEG-based event detection and monitoring. By relying on the demonstrated power of autoencoder (AE) networks to learn latent representations from high-dimensional data, our proposed strategy trains an AE architecture in a one-class classification setup with different electrode set-ups as input data. The resulting models are assessed using the F-score and the best set-up is chosen according to the established optimal criteria. Using alpha wave detection as use case, we demonstrate that the proposed method allows to detect an alpha state from an optimal set-up consisting of electrodes in the forehead and behind the ear, with an average F-score of 0.78. Our results suggest that a learning-based approach can be used to enable the design and implementation of optimized wearable devices for real-life healthcare monitoring.
Automatic Tracker Selection w.r.t Object Detection Performance
Apr 08, 2014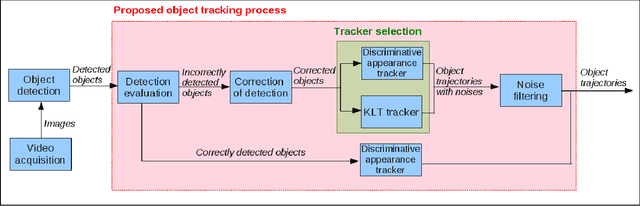
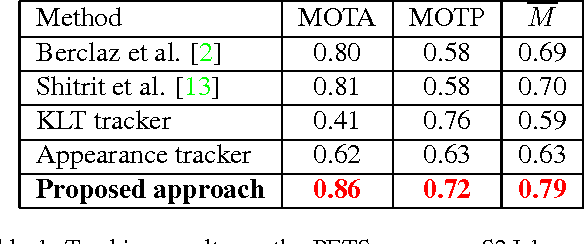

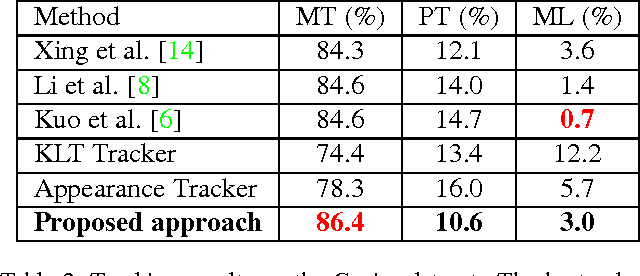
The tracking algorithm performance depends on video content. This paper presents a new multi-object tracking approach which is able to cope with video content variations. First the object detection is improved using Kanade- Lucas-Tomasi (KLT) feature tracking. Second, for each mobile object, an appropriate tracker is selected among a KLT-based tracker and a discriminative appearance-based tracker. This selection is supported by an online tracking evaluation. The approach has been experimented on three public video datasets. The experimental results show a better performance of the proposed approach compared to recent state of the art trackers.
Online Tracking Parameter Adaptation based on Evaluation
Jul 22, 2013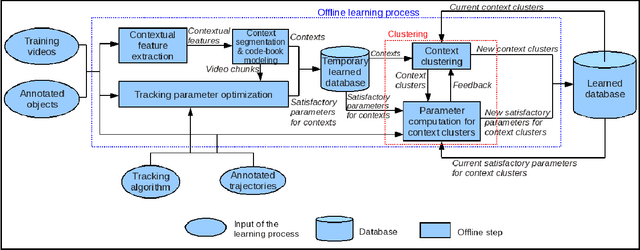


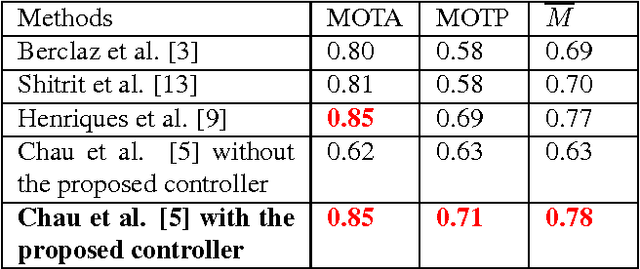
Parameter tuning is a common issue for many tracking algorithms. In order to solve this problem, this paper proposes an online parameter tuning to adapt a tracking algorithm to various scene contexts. In an offline training phase, this approach learns how to tune the tracker parameters to cope with different contexts. In the online control phase, once the tracking quality is evaluated as not good enough, the proposed approach computes the current context and tunes the tracking parameters using the learned values. The experimental results show that the proposed approach improves the performance of the tracking algorithm and outperforms recent state of the art trackers. This paper brings two contributions: (1) an online tracking evaluation, and (2) a method to adapt online tracking parameters to scene contexts.
Automatic Parameter Adaptation for Multi-object Tracking
May 13, 2013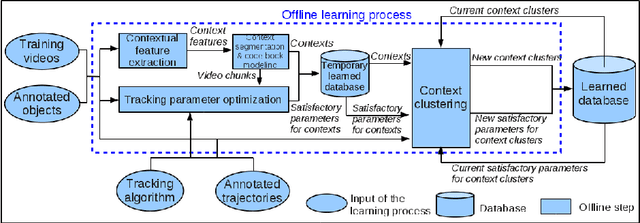

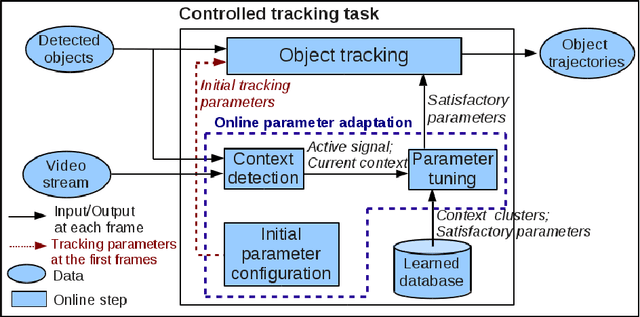

Object tracking quality usually depends on video context (e.g. object occlusion level, object density). In order to decrease this dependency, this paper presents a learning approach to adapt the tracker parameters to the context variations. In an offline phase, satisfactory tracking parameters are learned for video context clusters. In the online control phase, once a context change is detected, the tracking parameters are tuned using the learned values. The experimental results show that the proposed approach outperforms the recent trackers in state of the art. This paper brings two contributions: (1) a classification method of video sequences to learn offline tracking parameters, (2) a new method to tune online tracking parameters using tracking context.
Object Tracking in Videos: Approaches and Issues
Apr 18, 2013


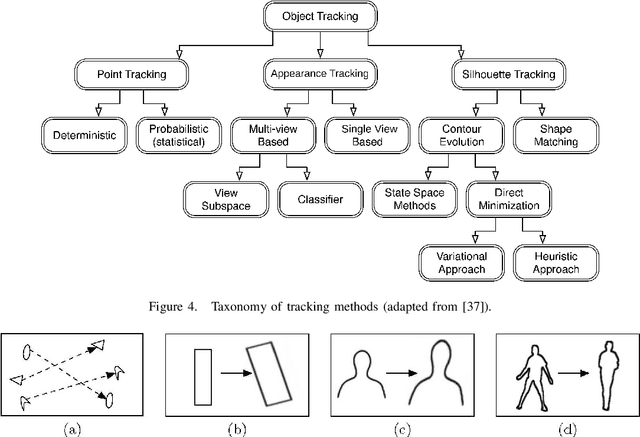
Mobile object tracking has an important role in the computer vision applications. In this paper, we use a tracked target-based taxonomy to present the object tracking algorithms. The tracked targets are divided into three categories: points of interest, appearance and silhouette of mobile objects. Advantages and limitations of the tracking approaches are also analyzed to find the future directions in the object tracking domain.
A generic framework for video understanding applied to group behavior recognition
Jun 22, 2012


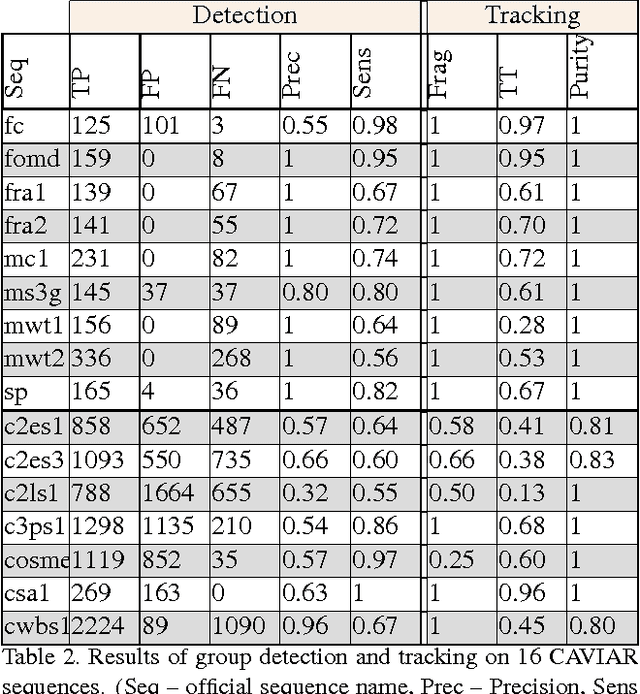
This paper presents an approach to detect and track groups of people in video-surveillance applications, and to automatically recognize their behavior. This method keeps track of individuals moving together by maintaining a spacial and temporal group coherence. First, people are individually detected and tracked. Second, their trajectories are analyzed over a temporal window and clustered using the Mean-Shift algorithm. A coherence value describes how well a set of people can be described as a group. Furthermore, we propose a formal event description language. The group events recognition approach is successfully validated on 4 camera views from 3 datasets: an airport, a subway, a shopping center corridor and an entrance hall.
* (20/03/2012)
A multi-feature tracking algorithm enabling adaptation to context variations
Dec 06, 2011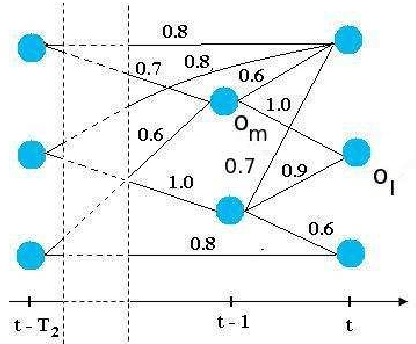



We propose in this paper a tracking algorithm which is able to adapt itself to different scene contexts. A feature pool is used to compute the matching score between two detected objects. This feature pool includes 2D, 3D displacement distances, 2D sizes, color histogram, histogram of oriented gradient (HOG), color covariance and dominant color. An offline learning process is proposed to search for useful features and to estimate their weights for each context. In the online tracking process, a temporal window is defined to establish the links between the detected objects. This enables to find the object trajectories even if the objects are misdetected in some frames. A trajectory filter is proposed to remove noisy trajectories. Experimentation on different contexts is shown. The proposed tracker has been tested in videos belonging to three public datasets and to the Caretaker European project. The experimental results prove the effect of the proposed feature weight learning, and the robustness of the proposed tracker compared to some methods in the state of the art. The contributions of our approach over the state of the art trackers are: (i) a robust tracking algorithm based on a feature pool, (ii) a supervised learning scheme to learn feature weights for each context, (iii) a new method to quantify the reliability of HOG descriptor, (iv) a combination of color covariance and dominant color features with spatial pyramid distance to manage the case of object occlusion.