 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoose Social-Interaction Recognition in Real-world Therapy Scenarios
Sep 30, 2024



The computer vision community has explored dyadic interactions for atomic actions such as pushing, carrying-object, etc. However, with the advancement in deep learning models, there is a need to explore more complex dyadic situations such as loose interactions. These are interactions where two people perform certain atomic activities to complete a global action irrespective of temporal synchronisation and physical engagement, like cooking-together for example. Analysing these types of dyadic-interactions has several useful applications in the medical domain for social-skills development and mental health diagnosis. To achieve this, we propose a novel dual-path architecture to capture the loose interaction between two individuals. Our model learns global abstract features from each stream via a CNNs backbone and fuses them using a new Global-Layer-Attention module based on a cross-attention strategy. We evaluate our model on real-world autism diagnoses such as our Loose-Interaction dataset, and the publicly available Autism dataset for loose interactions. Our network achieves baseline results on the Loose-Interaction and SOTA results on the Autism datasets. Moreover, we study different social interactions by experimenting on a publicly available dataset i.e. NTU-RGB+D (interactive classes from both NTU-60 and NTU-120). We have found that different interactions require different network designs. We also compare a slightly different version of our method by incorporating time information to address tight interactions achieving SOTA results.
VPN: Learning Video-Pose Embedding for Activities of Daily Living
Jul 06, 2020



In this paper, we focus on the spatio-temporal aspect of recognizing Activities of Daily Living (ADL). ADL have two specific properties (i) subtle spatio-temporal patterns and (ii) similar visual patterns varying with time. Therefore, ADL may look very similar and often necessitate to look at their fine-grained details to distinguish them. Because the recent spatio-temporal 3D ConvNets are too rigid to capture the subtle visual patterns across an action, we propose a novel Video-Pose Network: VPN. The 2 key components of this VPN are a spatial embedding and an attention network. The spatial embedding projects the 3D poses and RGB cues in a common semantic space. This enables the action recognition framework to learn better spatio-temporal features exploiting both modalities. In order to discriminate similar actions, the attention network provides two functionalities - (i) an end-to-end learnable pose backbone exploiting the topology of human body, and (ii) a coupler to provide joint spatio-temporal attention weights across a video. Experiments show that VPN outperforms the state-of-the-art results for action classification on a large scale human activity dataset: NTU-RGB+D 120, its subset NTU-RGB+D 60, a real-world challenging human activity dataset: Toyota Smarthome and a small scale human-object interaction dataset Northwestern UCLA.
Automatic Tracker Selection w.r.t Object Detection Performance
Apr 08, 2014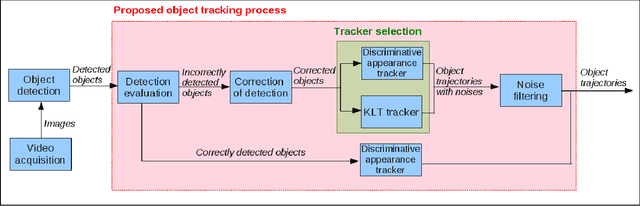
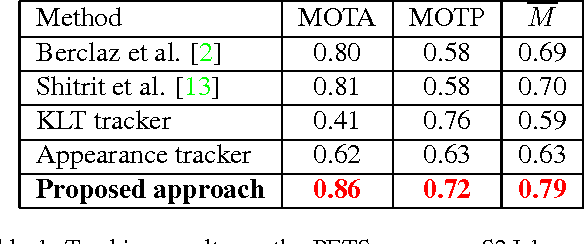

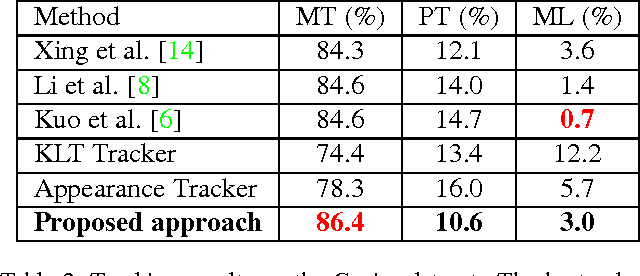
The tracking algorithm performance depends on video content. This paper presents a new multi-object tracking approach which is able to cope with video content variations. First the object detection is improved using Kanade- Lucas-Tomasi (KLT) feature tracking. Second, for each mobile object, an appropriate tracker is selected among a KLT-based tracker and a discriminative appearance-based tracker. This selection is supported by an online tracking evaluation. The approach has been experimented on three public video datasets. The experimental results show a better performance of the proposed approach compared to recent state of the art trackers.
Online Tracking Parameter Adaptation based on Evaluation
Jul 22, 2013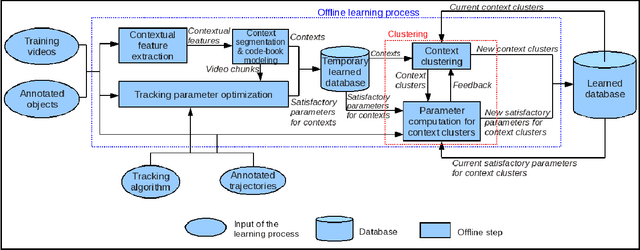


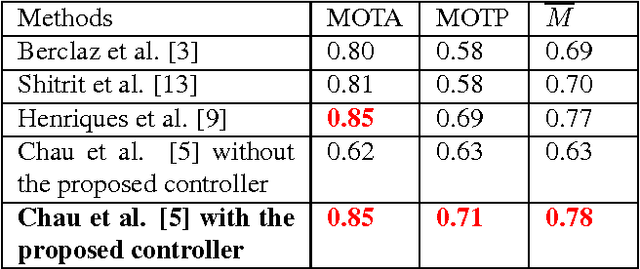
Parameter tuning is a common issue for many tracking algorithms. In order to solve this problem, this paper proposes an online parameter tuning to adapt a tracking algorithm to various scene contexts. In an offline training phase, this approach learns how to tune the tracker parameters to cope with different contexts. In the online control phase, once the tracking quality is evaluated as not good enough, the proposed approach computes the current context and tunes the tracking parameters using the learned values. The experimental results show that the proposed approach improves the performance of the tracking algorithm and outperforms recent state of the art trackers. This paper brings two contributions: (1) an online tracking evaluation, and (2) a method to adapt online tracking parameters to scene contexts.
Automatic Parameter Adaptation for Multi-object Tracking
May 13, 2013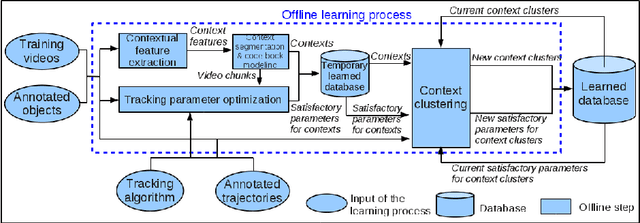

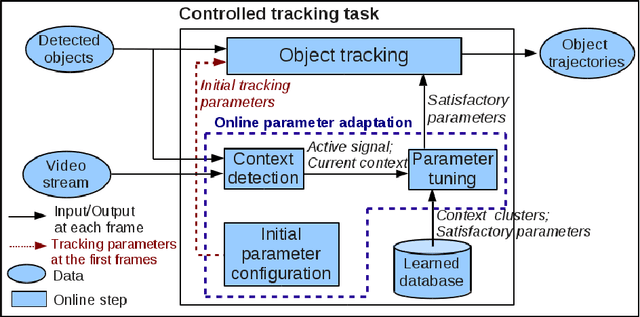

Object tracking quality usually depends on video context (e.g. object occlusion level, object density). In order to decrease this dependency, this paper presents a learning approach to adapt the tracker parameters to the context variations. In an offline phase, satisfactory tracking parameters are learned for video context clusters. In the online control phase, once a context change is detected, the tracking parameters are tuned using the learned values. The experimental results show that the proposed approach outperforms the recent trackers in state of the art. This paper brings two contributions: (1) a classification method of video sequences to learn offline tracking parameters, (2) a new method to tune online tracking parameters using tracking context.
Object Tracking in Videos: Approaches and Issues
Apr 18, 2013


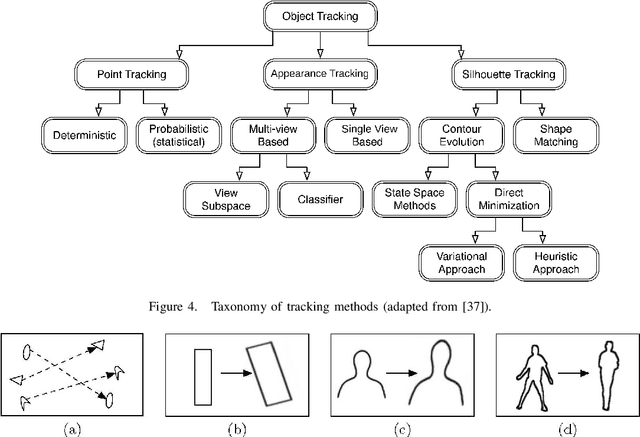
Mobile object tracking has an important role in the computer vision applications. In this paper, we use a tracked target-based taxonomy to present the object tracking algorithms. The tracked targets are divided into three categories: points of interest, appearance and silhouette of mobile objects. Advantages and limitations of the tracking approaches are also analyzed to find the future directions in the object tracking domain.
A multi-feature tracking algorithm enabling adaptation to context variations
Dec 06, 2011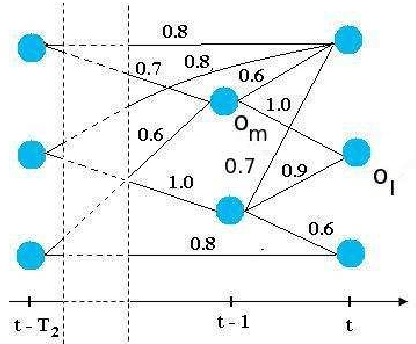



We propose in this paper a tracking algorithm which is able to adapt itself to different scene contexts. A feature pool is used to compute the matching score between two detected objects. This feature pool includes 2D, 3D displacement distances, 2D sizes, color histogram, histogram of oriented gradient (HOG), color covariance and dominant color. An offline learning process is proposed to search for useful features and to estimate their weights for each context. In the online tracking process, a temporal window is defined to establish the links between the detected objects. This enables to find the object trajectories even if the objects are misdetected in some frames. A trajectory filter is proposed to remove noisy trajectories. Experimentation on different contexts is shown. The proposed tracker has been tested in videos belonging to three public datasets and to the Caretaker European project. The experimental results prove the effect of the proposed feature weight learning, and the robustness of the proposed tracker compared to some methods in the state of the art. The contributions of our approach over the state of the art trackers are: (i) a robust tracking algorithm based on a feature pool, (ii) a supervised learning scheme to learn feature weights for each context, (iii) a new method to quantify the reliability of HOG descriptor, (iv) a combination of color covariance and dominant color features with spatial pyramid distance to manage the case of object occlusion.
Robust Mobile Object Tracking Based on Multiple Feature Similarity and Trajectory Filtering
Jun 14, 2011
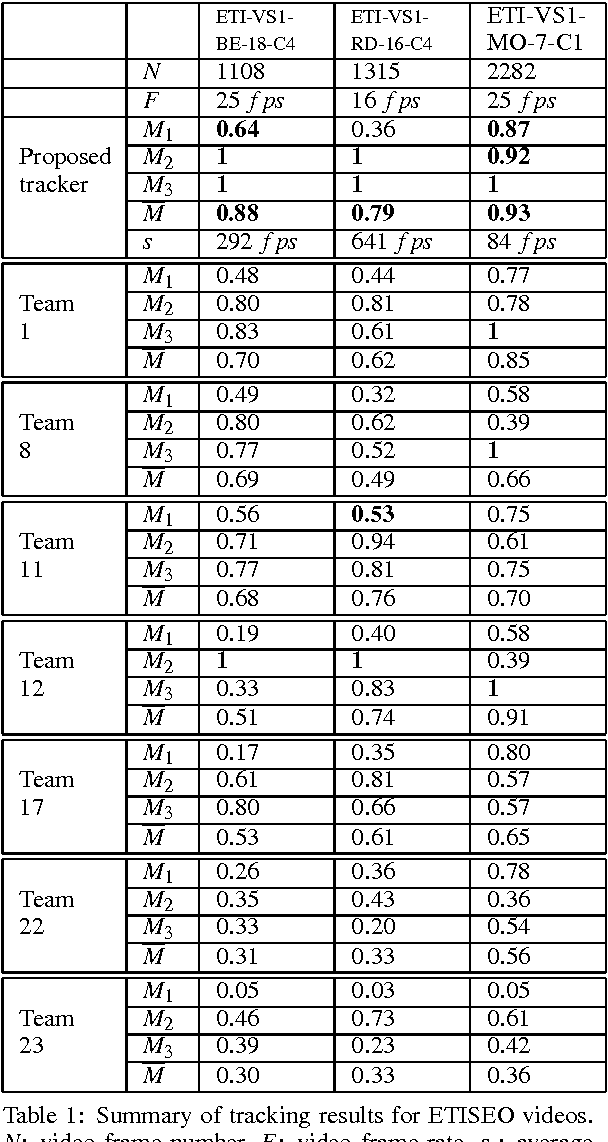
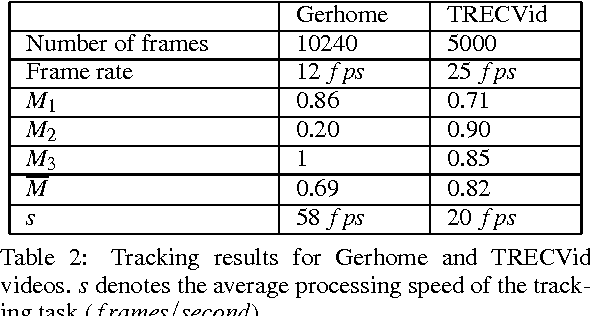
This paper presents a new algorithm to track mobile objects in different scene conditions. The main idea of the proposed tracker includes estimation, multi-features similarity measures and trajectory filtering. A feature set (distance, area, shape ratio, color histogram) is defined for each tracked object to search for the best matching object. Its best matching object and its state estimated by the Kalman filter are combined to update position and size of the tracked object. However, the mobile object trajectories are usually fragmented because of occlusions and misdetections. Therefore, we also propose a trajectory filtering, named global tracker, aims at removing the noisy trajectories and fusing the fragmented trajectories belonging to a same mobile object. The method has been tested with five videos of different scene conditions. Three of them are provided by the ETISEO benchmarking project (http://www-sop.inria.fr/orion/ETISEO) in which the proposed tracker performance has been compared with other seven tracking algorithms. The advantages of our approach over the existing state of the art ones are: (i) no prior knowledge information is required (e.g. no calibration and no contextual models are needed), (ii) the tracker is more reliable by combining multiple feature similarities, (iii) the tracker can perform in different scene conditions: single/several mobile objects, weak/strong illumination, indoor/outdoor scenes, (iv) a trajectory filtering is defined and applied to improve the tracker performance, (v) the tracker performance outperforms many algorithms of the state of the art.
Repairing People Trajectories Based on Point Clustering
Jul 02, 2010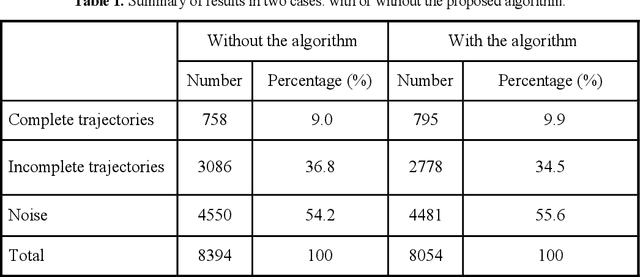

This paper presents a method for improving any object tracking algorithm based on machine learning. During the training phase, important trajectory features are extracted which are then used to calculate a confidence value of trajectory. The positions at which objects are usually lost and found are clustered in order to construct the set of 'lost zones' and 'found zones' in the scene. Using these zones, we construct a triplet set of zones i.e. three zones: In/Out zone (zone where an object can enter or exit the scene), 'lost zone' and 'found zone'. Thanks to these triplets, during the testing phase, we can repair the erroneous trajectories according to which triplet they are most likely to belong to. The advantage of our approach over the existing state of the art approaches is that (i) this method does not depend on a predefined contextual scene, (ii) we exploit the semantic of the scene and (iii) we have proposed a method to filter out noisy trajectories based on their confidence value.