 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Multimodal to Unimodal Attention in Transformers using Knowledge Distillation
Paper and Code
Oct 19, 2021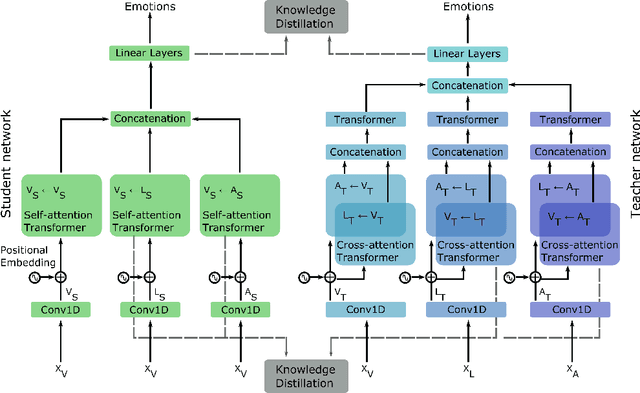
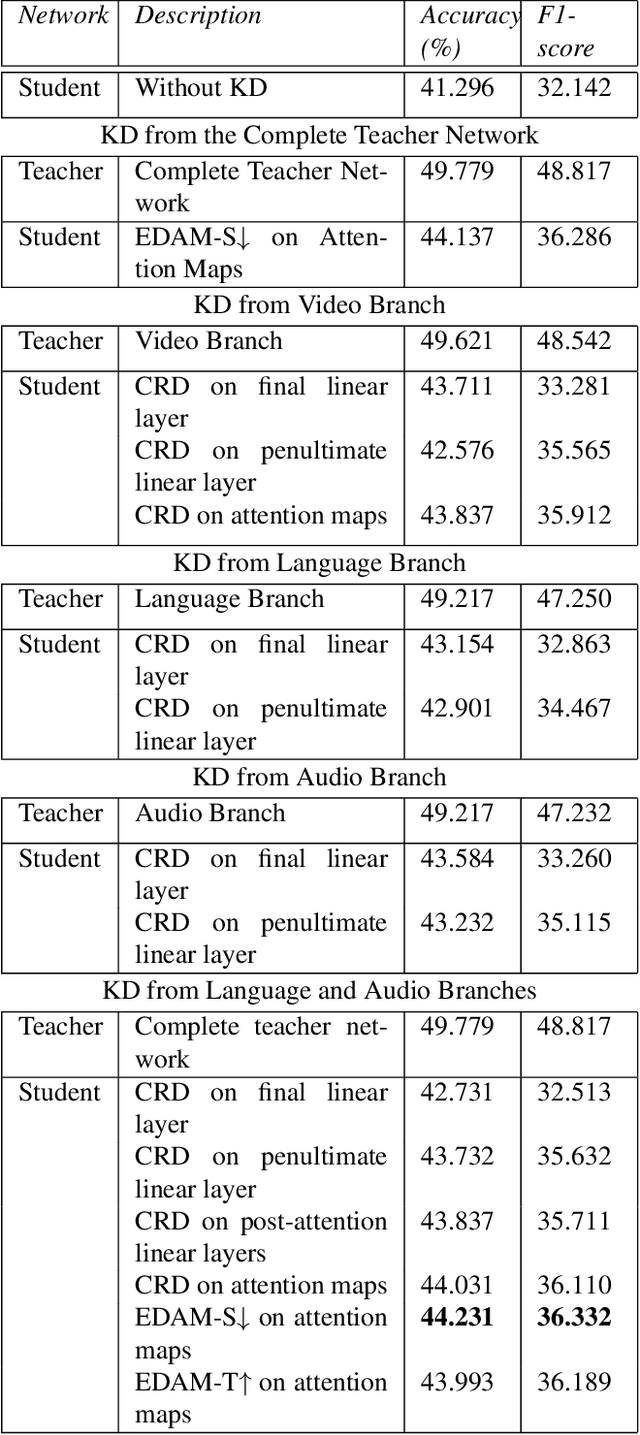
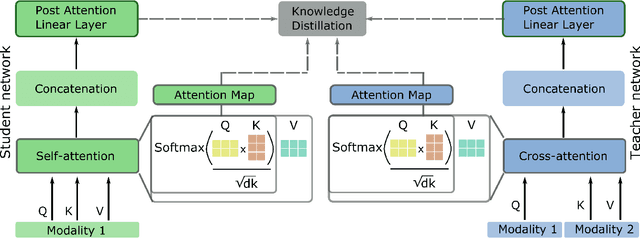

Multimodal Deep Learning has garnered much interest, and transformers have triggered novel approaches, thanks to the cross-attention mechanism. Here we propose an approach to deal with two key existing challenges: the high computational resource demanded and the issue of missing modalities. We introduce for the first time the concept of knowledge distillation in transformers to use only one modality at inference time. We report a full study analyzing multiple student-teacher configurations, levels at which distillation is applied, and different methodologies. With the best configuration, we improved the state-of-the-art accuracy by 3%, we reduced the number of parameters by 2.5 times and the inference time by 22%. Such performance-computation tradeoff can be exploited in many applications and we aim at opening a new research area where the deployment of complex models with limited resources is demanded.