 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Topic Modeling Techniques for Categorizing Software Vulnerabilities
Jul 04, 2026The increasing complexity and frequency of software vulnerabilities demand efficient methods to analyze and prioritize threats. Traditional approaches often fail to process the vast amount of unstructured textual data effectively, highlighting the need for advanced solutions. This study leverages state-of-the-art topic modeling techniques powered by large language models (LLMs) to extract meaningful insights from the 'Threat' feature of a software vulnerability dataset. Models such as BERTopic, Top2Vec, CombinedTM, Llama2 with BERTopic, and Mixtral are utilized, along with dimensionality reduction and clustering methods like UMAP, PCA, HDBSCAN, and DBSCAN. By uncovering latent patterns and generating interpretable clusters, this research enhances threat prioritization and decision-making in cybersecurity. The findings support scalable and automated solutions for vulnerability management, contributing to improved security practices.
Robust Deepfake Detection, NTIRE 2026 Challenge: Report
Apr 27, 2026Robustness is a long-overlooked problem in deepfake detection. However, detection performance is nearly worthless in the real world if it suffers under exposure to even slight image degradation. In addition to weaker degradations that can accidentally occur in the image processing pipeline, there is another risk of malicious deepfakes that specifically introduce degradations, purposefully exploiting the detector's weaknesses in that regard. Here, we present an overview of the NTIRE 2026 Robust Deepfake Detection Challenge, which specifically addresses that problem. Participants were tasked with building a detector that would later be tested on an unknown test-set, which included both common and uncommon degradations of various strengths. With a total number of 337 participants and 57 submissions to the final leaderboard, the first edition of the challenge was well received. To ensure the reliability of the results, participants were given only 24h to complete the test run with no labels provided, limiting the possibility of training on the test data. Furthermore, the top solutions were scored on a private test-set to detect any such overfitting. This report presents the competition setting, dataset preparation, as well as details and performance of methods. Top methods rely on large foundation models, ensembles, and degradation training to combine generality and robustness.
DebateBench: A Challenging Long Context Reasoning Benchmark For Large Language Models
Feb 10, 2025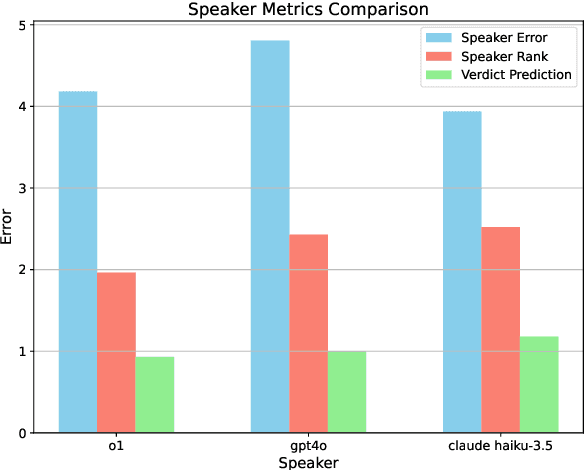
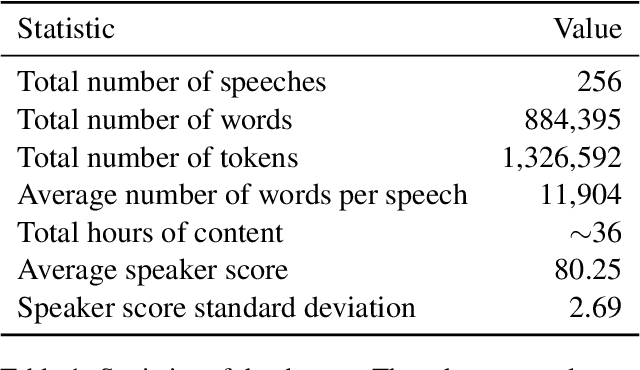
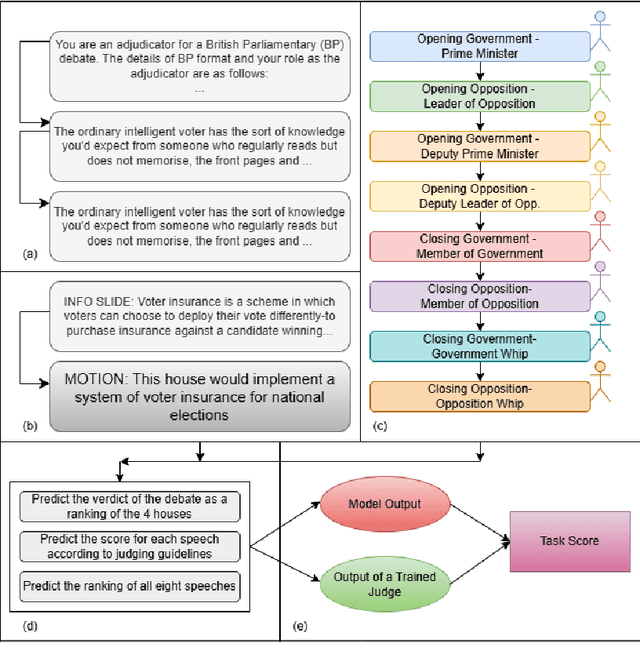
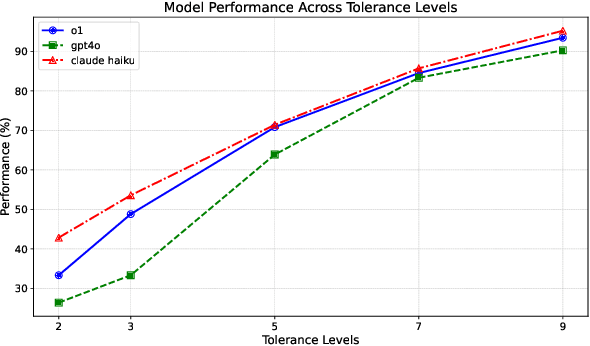
We introduce DebateBench, a novel dataset consisting of an extensive collection of transcripts and metadata from some of the world's most prestigious competitive debates. The dataset consists of British Parliamentary debates from prestigious debating tournaments on diverse topics, annotated with detailed speech-level scores and house rankings sourced from official adjudication data. We curate 256 speeches across 32 debates with each debate being over 1 hour long with each input being an average of 32,000 tokens. Designed to capture long-context, large-scale reasoning tasks, DebateBench provides a benchmark for evaluating modern large language models (LLMs) on their ability to engage in argumentation, deliberation, and alignment with human experts. To do well on DebateBench, the LLMs must perform in-context learning to understand the rules and evaluation criteria of the debates, then analyze 8 seven minute long speeches and reason about the arguments presented by all speakers to give the final results. Our preliminary evaluation using GPT o1, GPT-4o, and Claude Haiku, shows that LLMs struggle to perform well on DebateBench, highlighting the need to develop more sophisticated techniques for improving their performance.
Emergent Stack Representations in Modeling Counter Languages Using Transformers
Feb 03, 2025Transformer architectures are the backbone of most modern language models, but understanding the inner workings of these models still largely remains an open problem. One way that research in the past has tackled this problem is by isolating the learning capabilities of these architectures by training them over well-understood classes of formal languages. We extend this literature by analyzing models trained over counter languages, which can be modeled using counter variables. We train transformer models on 4 counter languages, and equivalently formulate these languages using stacks, whose depths can be understood as the counter values. We then probe their internal representations for stack depths at each input token to show that these models when trained as next token predictors learn stack-like representations. This brings us closer to understanding the algorithmic details of how transformers learn languages and helps in circuit discovery.
What Matters in Autonomous Driving Anomaly Detection: A Weakly Supervised Horizon
Aug 10, 2024Video anomaly detection (VAD) in autonomous driving scenario is an important task, however it involves several challenges due to the ego-centric views and moving camera. Due to this, it remains largely under-explored. While recent developments in weakly-supervised VAD methods have shown remarkable progress in detecting critical real-world anomalies in static camera scenario, the development and validation of such methods are yet to be explored for moving camera VAD. This is mainly due to existing datasets like DoTA not following training pre-conditions of weakly-supervised learning. In this paper, we aim to promote weakly-supervised method development for autonomous driving VAD. We reorganize the DoTA dataset and aim to validate recent powerful weakly-supervised VAD methods on moving camera scenarios. Further, we provide a detailed analysis of what modifications on state-of-the-art methods can significantly improve the detection performance. Towards this, we propose a "feature transformation block" and through experimentation we show that our propositions can empower existing weakly-supervised VAD methods significantly in improving the VAD in autonomous driving. Our codes/dataset/demo will be released at github.com/ut21/WSAD-Driving