 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebateBench: A Challenging Long Context Reasoning Benchmark For Large Language Models
Paper and Code
Feb 10, 2025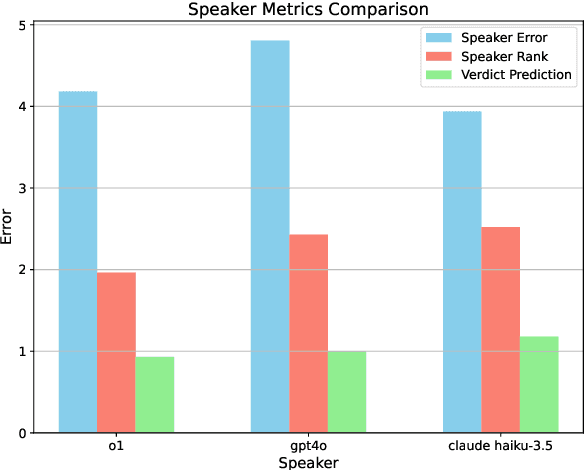
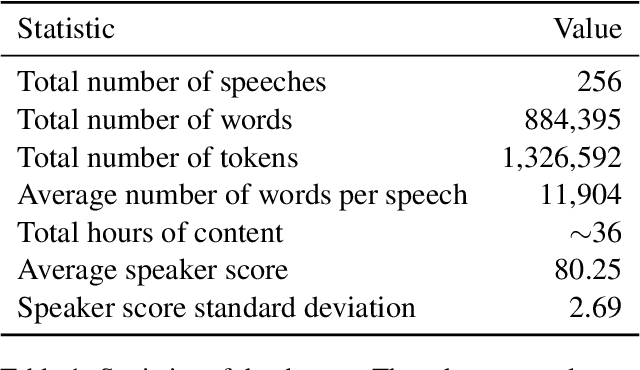
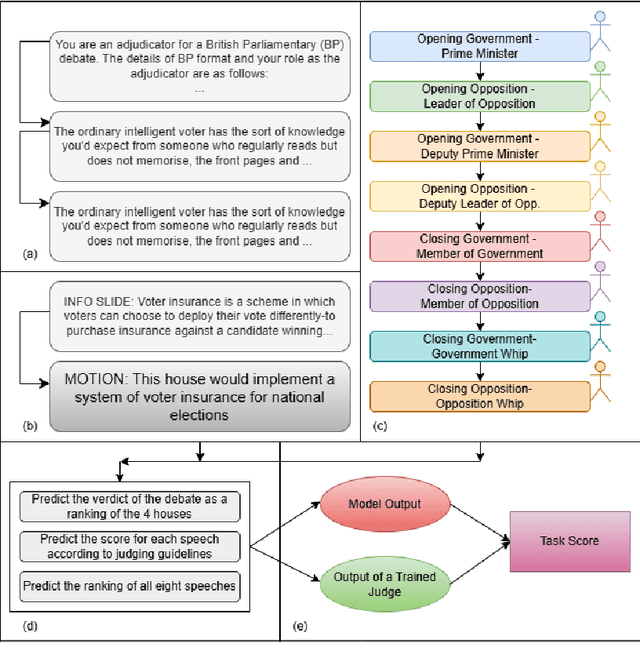
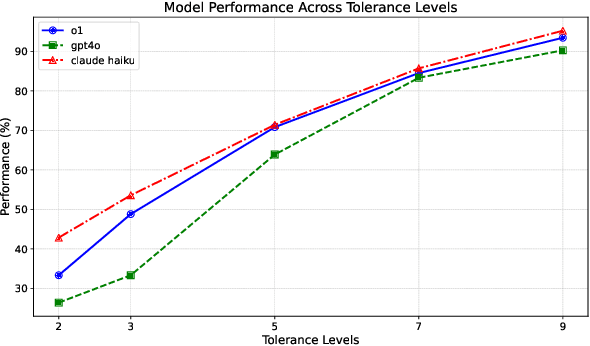
We introduce DebateBench, a novel dataset consisting of an extensive collection of transcripts and metadata from some of the world's most prestigious competitive debates. The dataset consists of British Parliamentary debates from prestigious debating tournaments on diverse topics, annotated with detailed speech-level scores and house rankings sourced from official adjudication data. We curate 256 speeches across 32 debates with each debate being over 1 hour long with each input being an average of 32,000 tokens. Designed to capture long-context, large-scale reasoning tasks, DebateBench provides a benchmark for evaluating modern large language models (LLMs) on their ability to engage in argumentation, deliberation, and alignment with human experts. To do well on DebateBench, the LLMs must perform in-context learning to understand the rules and evaluation criteria of the debates, then analyze 8 seven minute long speeches and reason about the arguments presented by all speakers to give the final results. Our preliminary evaluation using GPT o1, GPT-4o, and Claude Haiku, shows that LLMs struggle to perform well on DebateBench, highlighting the need to develop more sophisticated techniques for improving their performance.