 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebateBench: A Challenging Long Context Reasoning Benchmark For Large Language Models
Feb 10, 2025
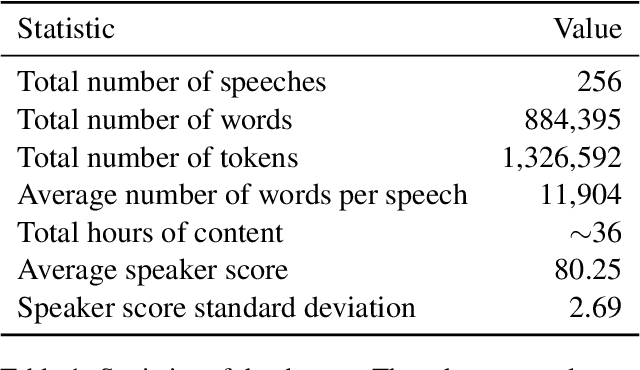
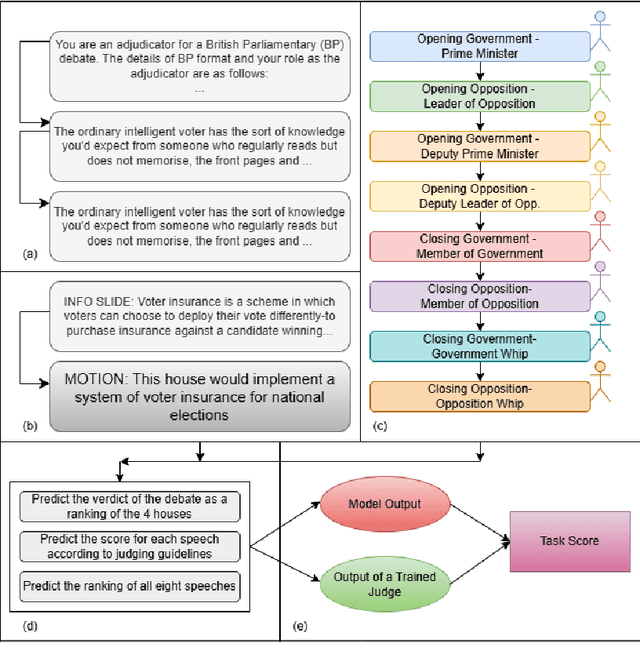
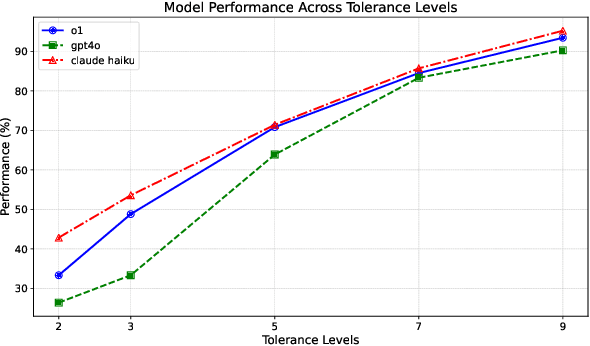
We introduce DebateBench, a novel dataset consisting of an extensive collection of transcripts and metadata from some of the world's most prestigious competitive debates. The dataset consists of British Parliamentary debates from prestigious debating tournaments on diverse topics, annotated with detailed speech-level scores and house rankings sourced from official adjudication data. We curate 256 speeches across 32 debates with each debate being over 1 hour long with each input being an average of 32,000 tokens. Designed to capture long-context, large-scale reasoning tasks, DebateBench provides a benchmark for evaluating modern large language models (LLMs) on their ability to engage in argumentation, deliberation, and alignment with human experts. To do well on DebateBench, the LLMs must perform in-context learning to understand the rules and evaluation criteria of the debates, then analyze 8 seven minute long speeches and reason about the arguments presented by all speakers to give the final results. Our preliminary evaluation using GPT o1, GPT-4o, and Claude Haiku, shows that LLMs struggle to perform well on DebateBench, highlighting the need to develop more sophisticated techniques for improving their performance.
Balancing the Scales: Enhancing Fairness in Facial Expression Recognition with Latent Alignment
Oct 25, 2024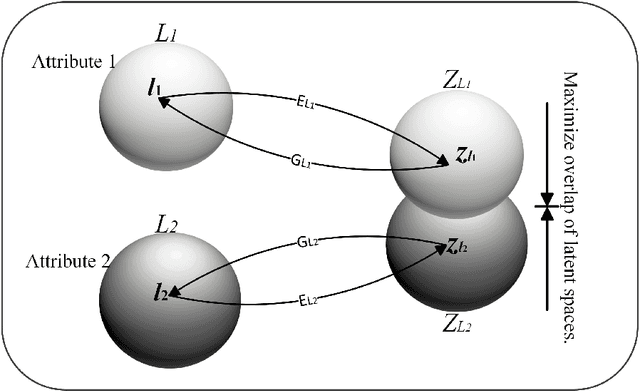
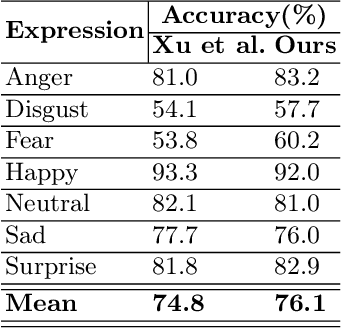
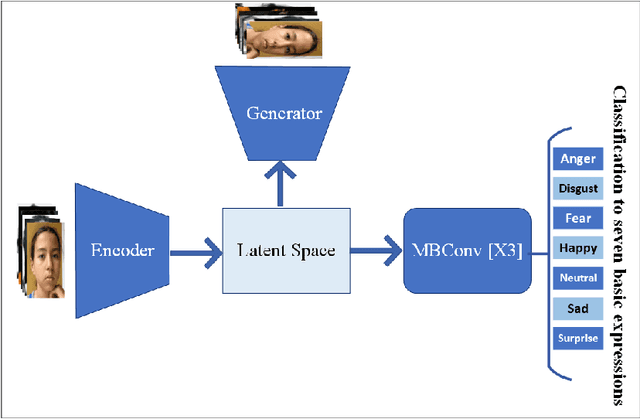
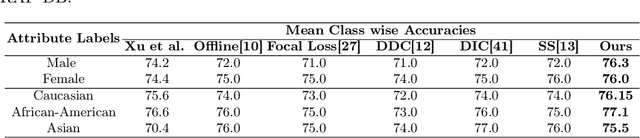
Automatically recognizing emotional intent using facial expression has been a thoroughly investigated topic in the realm of computer vision. Facial Expression Recognition (FER), being a supervised learning task, relies heavily on substantially large data exemplifying various socio-cultural demographic attributes. Over the past decade, several real-world in-the-wild FER datasets that have been proposed were collected through crowd-sourcing or web-scraping. However, most of these practically used datasets employ a manual annotation methodology for labeling emotional intent, which inherently propagates individual demographic biases. Moreover, these datasets also lack an equitable representation of various socio-cultural demographic groups, thereby inducing a class imbalance. Bias analysis and its mitigation have been investigated across multiple domains and problem settings, however, in the FER domain, this is a relatively lesser explored area. This work leverages representation learning based on latent spaces to mitigate bias in facial expression recognition systems, thereby enhancing a deep learning model's fairness and overall accuracy.