 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeeling Machines: Ethics, Culture, and the Rise of Emotional AI
Jun 14, 2025This paper explores the growing presence of emotionally responsive artificial intelligence through a critical and interdisciplinary lens. Bringing together the voices of early-career researchers from multiple fields, it explores how AI systems that simulate or interpret human emotions are reshaping our interactions in areas such as education, healthcare, mental health, caregiving, and digital life. The analysis is structured around four central themes: the ethical implications of emotional AI, the cultural dynamics of human-machine interaction, the risks and opportunities for vulnerable populations, and the emerging regulatory, design, and technical considerations. The authors highlight the potential of affective AI to support mental well-being, enhance learning, and reduce loneliness, as well as the risks of emotional manipulation, over-reliance, misrepresentation, and cultural bias. Key challenges include simulating empathy without genuine understanding, encoding dominant sociocultural norms into AI systems, and insufficient safeguards for individuals in sensitive or high-risk contexts. Special attention is given to children, elderly users, and individuals with mental health challenges, who may interact with AI in emotionally significant ways. However, there remains a lack of cognitive or legal protections which are necessary to navigate such engagements safely. The report concludes with ten recommendations, including the need for transparency, certification frameworks, region-specific fine-tuning, human oversight, and longitudinal research. A curated supplementary section provides practical tools, models, and datasets to support further work in this domain.
REACT 2025: the Third Multiple Appropriate Facial Reaction Generation Challenge
May 22, 2025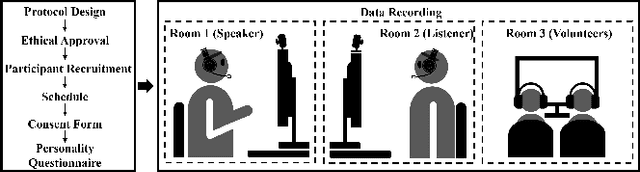

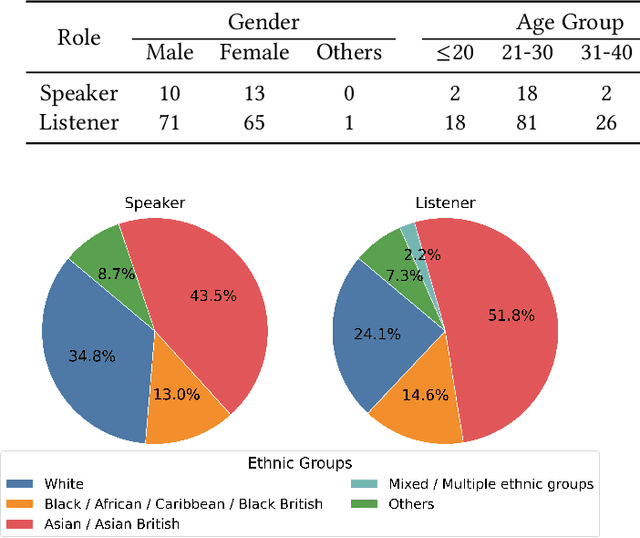
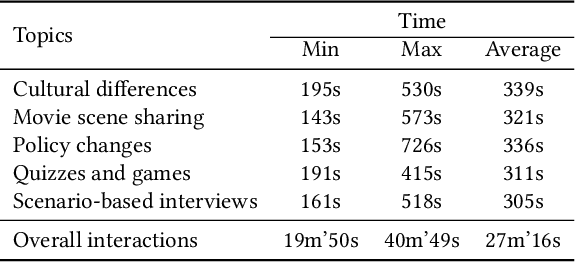
In dyadic interactions, a broad spectrum of human facial reactions might be appropriate for responding to each human speaker behaviour. Following the successful organisation of the REACT 2023 and REACT 2024 challenges, we are proposing the REACT 2025 challenge encouraging the development and benchmarking of Machine Learning (ML) models that can be used to generate multiple appropriate, diverse, realistic and synchronised human-style facial reactions expressed by human listeners in response to an input stimulus (i.e., audio-visual behaviours expressed by their corresponding speakers). As a key of the challenge, we provide challenge participants with the first natural and large-scale multi-modal MAFRG dataset (called MARS) recording 137 human-human dyadic interactions containing a total of 2856 interaction sessions covering five different topics. In addition, this paper also presents the challenge guidelines and the performance of our baselines on the two proposed sub-challenges: Offline MAFRG and Online MAFRG, respectively. The challenge baseline code is publicly available at https://github.com/reactmultimodalchallenge/baseline_react2025
REACT 2024: the Second Multiple Appropriate Facial Reaction Generation Challenge
Jan 10, 2024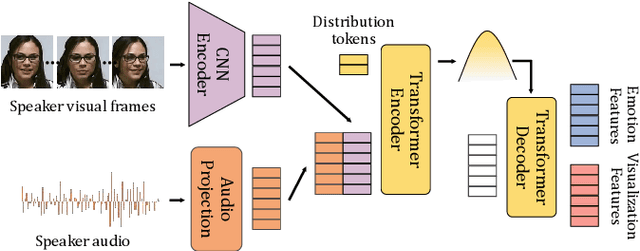
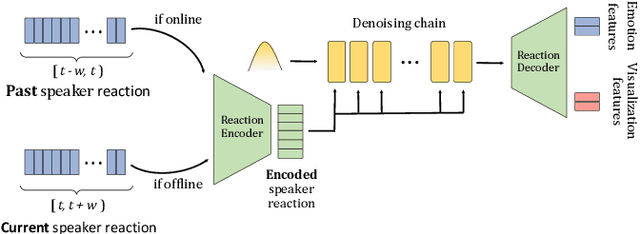
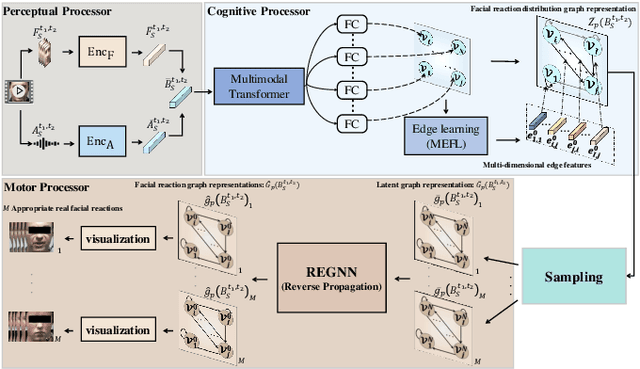
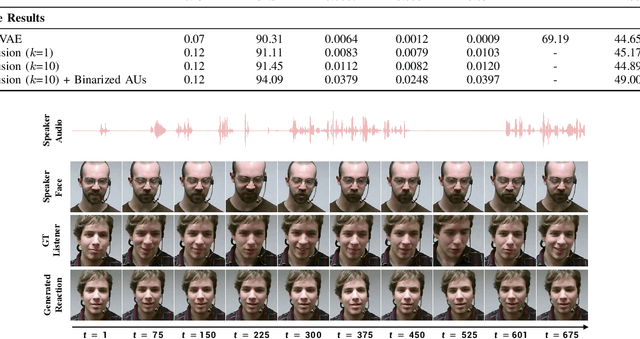
In dyadic interactions, humans communicate their intentions and state of mind using verbal and non-verbal cues, where multiple different facial reactions might be appropriate in response to a specific speaker behaviour. Then, how to develop a machine learning (ML) model that can automatically generate multiple appropriate, diverse, realistic and synchronised human facial reactions from an previously unseen speaker behaviour is a challenging task. Following the successful organisation of the first REACT challenge (REACT 2023), this edition of the challenge (REACT 2024) employs a subset used by the previous challenge, which contains segmented 30-secs dyadic interaction clips originally recorded as part of the NOXI and RECOLA datasets, encouraging participants to develop and benchmark Machine Learning (ML) models that can generate multiple appropriate facial reactions (including facial image sequences and their attributes) given an input conversational partner's stimulus under various dyadic video conference scenarios. This paper presents: (i) the guidelines of the REACT 2024 challenge; (ii) the dataset utilized in the challenge; and (iii) the performance of the baseline systems on the two proposed sub-challenges: Offline Multiple Appropriate Facial Reaction Generation and Online Multiple Appropriate Facial Reaction Generation, respectively. The challenge baseline code is publicly available at https://github.com/reactmultimodalchallenge/baseline_react2024.
REACT2023: the first Multi-modal Multiple Appropriate Facial Reaction Generation Challenge
Jun 11, 2023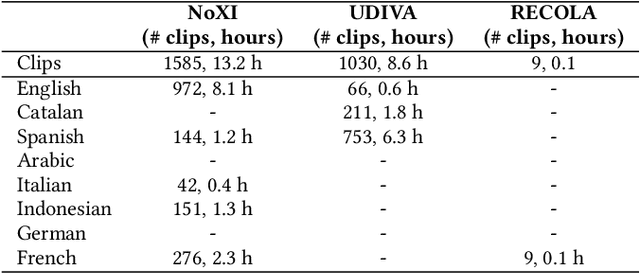
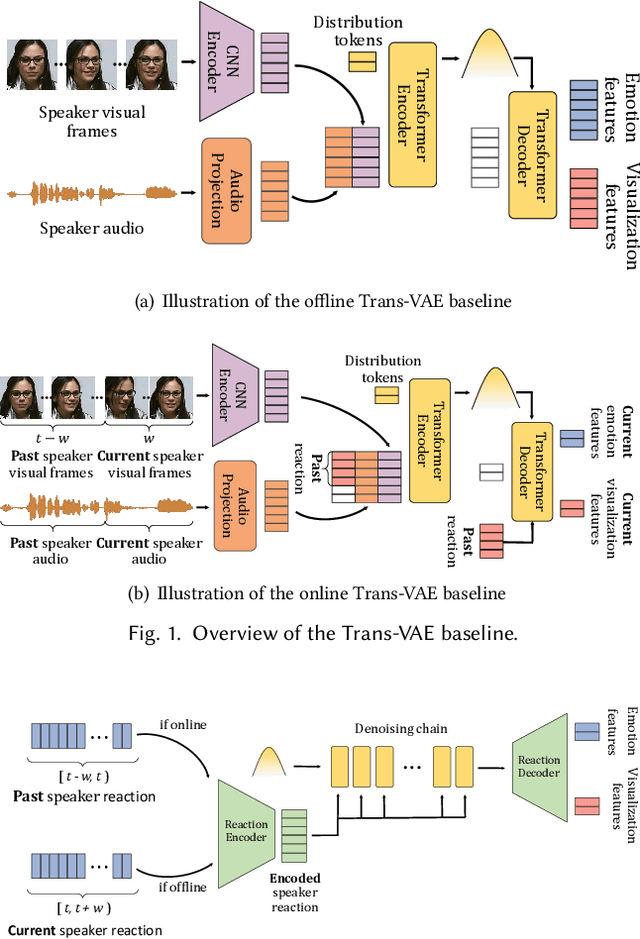
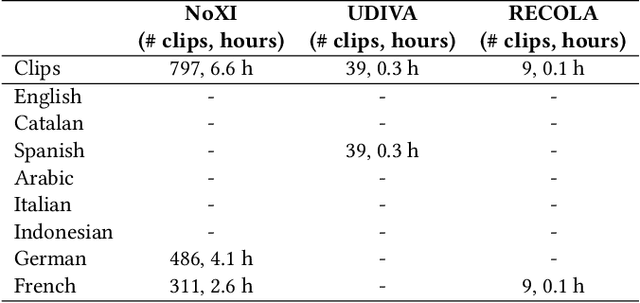
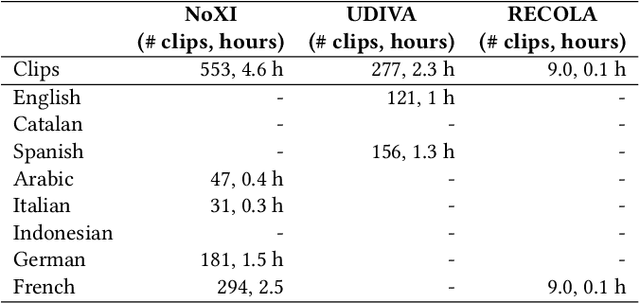
The Multi-modal Multiple Appropriate Facial Reaction Generation Challenge (REACT2023) is the first competition event focused on evaluating multimedia processing and machine learning techniques for generating human-appropriate facial reactions in various dyadic interaction scenarios, with all participants competing strictly under the same conditions. The goal of the challenge is to provide the first benchmark test set for multi-modal information processing and to foster collaboration among the audio, visual, and audio-visual affective computing communities, to compare the relative merits of the approaches to automatic appropriate facial reaction generation under different spontaneous dyadic interaction conditions. This paper presents: (i) novelties, contributions and guidelines of the REACT2023 challenge; (ii) the dataset utilized in the challenge; and (iii) the performance of baseline systems on the two proposed sub-challenges: Offline Multiple Appropriate Facial Reaction Generation and Online Multiple Appropriate Facial Reaction Generation, respectively. The challenge baseline code is publicly available at \url{https://github.com/reactmultimodalchallenge/baseline_react2023}.