 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK2-Think: A Parameter-Efficient Reasoning System
Sep 09, 2025K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.
Eigenspectrum Analysis of Neural Networks without Aspect Ratio Bias
Jun 06, 2025Diagnosing deep neural networks (DNNs) through the eigenspectrum of weight matrices has been an active area of research in recent years. At a high level, eigenspectrum analysis of DNNs involves measuring the heavytailness of the empirical spectral densities (ESD) of weight matrices. It provides insight into how well a model is trained and can guide decisions on assigning better layer-wise training hyperparameters. In this paper, we address a challenge associated with such eigenspectrum methods: the impact of the aspect ratio of weight matrices on estimated heavytailness metrics. We demonstrate that matrices of varying sizes (and aspect ratios) introduce a non-negligible bias in estimating heavytailness metrics, leading to inaccurate model diagnosis and layer-wise hyperparameter assignment. To overcome this challenge, we propose FARMS (Fixed-Aspect-Ratio Matrix Subsampling), a method that normalizes the weight matrices by subsampling submatrices with a fixed aspect ratio. Instead of measuring the heavytailness of the original ESD, we measure the average ESD of these subsampled submatrices. We show that measuring the heavytailness of these submatrices with the fixed aspect ratio can effectively mitigate the aspect ratio bias. We validate our approach across various optimization techniques and application domains that involve eigenspectrum analysis of weights, including image classification in computer vision (CV) models, scientific machine learning (SciML) model training, and large language model (LLM) pruning. Our results show that despite its simplicity, FARMS uniformly improves the accuracy of eigenspectrum analysis while enabling more effective layer-wise hyperparameter assignment in these application domains. In one of the LLM pruning experiments, FARMS reduces the perplexity of the LLaMA-7B model by 17.3% when compared with the state-of-the-art method.
OVERLORD: Ultimate Scaling of DataLoader for Multi-Source Large Foundation Model Training
Apr 14, 2025Modern frameworks for training large foundation models (LFMs) employ data loaders in a data parallel paradigm. While this design offers implementation simplicity, it introduces two fundamental challenges. First, due to the quadratic computational complexity of the attention operator, the non-uniform sample distribution over data-parallel ranks leads to a significant workload imbalance among loaders, which degrades the training efficiency. This paradigm also impedes the implementation of data mixing algorithms (e.g., curriculum learning) over different datasets. Second, to acquire a broad range of capability, LFMs training ingests data from diverse sources, each with distinct file access states. Colocating massive datasets within loader instances can easily exceed local pod memory capacity. Additionally, heavy sources with higher transformation latency require larger worker pools, further exacerbating memory consumption. We present OVERLORD, an industrial-grade distributed data loading architecture with three innovations: (1) A centralized and declarative data plane, which facilitates elastic data orchestration strategy, such as long-short context, multimodal, and curriculum learning; (2) Disaggregated multisource preprocessing through role-specific actors, i.e., Source Loaders and Data Constructors, leveraging autoscaling for Source Loaders towards heterogeneous and evolving source preprocessing cost; (3) Shadow Loaders with differential checkpointing for uninterrupted fault recovery. Deployed on production clusters scaling to multi-thousand GPU, OVERLORD achieves: (1) 4.5x end-to-end training throughput improvement, (2) a minimum 3.6x reduction in CPU memory usage, with further improvements to be added in later experiments.
Model Balancing Helps Low-data Training and Fine-tuning
Oct 16, 2024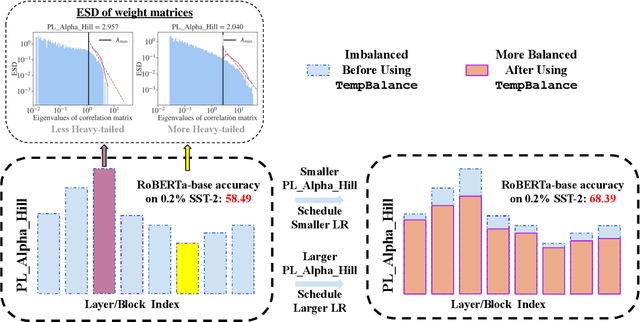

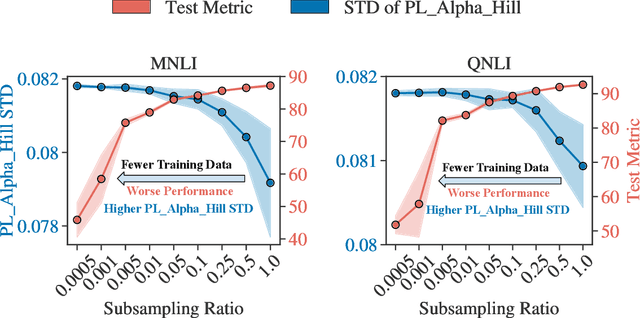
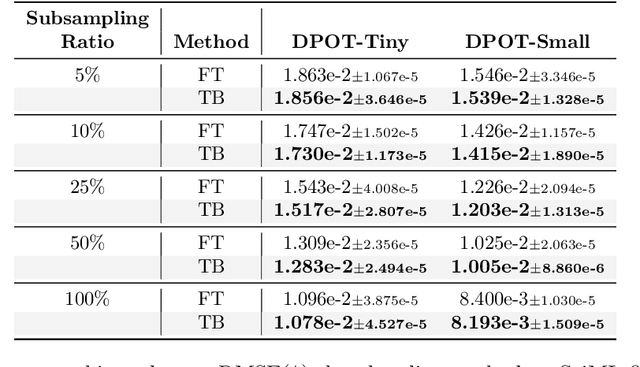
Recent advances in foundation models have emphasized the need to align pre-trained models with specialized domains using small, curated datasets. Studies on these foundation models underscore the importance of low-data training and fine-tuning. This topic, well-known in natural language processing (NLP), has also gained increasing attention in the emerging field of scientific machine learning (SciML). To address the limitations of low-data training and fine-tuning, we draw inspiration from Heavy-Tailed Self-Regularization (HT-SR) theory, analyzing the shape of empirical spectral densities (ESDs) and revealing an imbalance in training quality across different model layers. To mitigate this issue, we adapt a recently proposed layer-wise learning rate scheduler, TempBalance, which effectively balances training quality across layers and enhances low-data training and fine-tuning for both NLP and SciML tasks. Notably, TempBalance demonstrates increasing performance gains as the amount of available tuning data decreases. Comparative analyses further highlight the effectiveness of TempBalance and its adaptability as an "add-on" method for improving model performance.