 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization in Task-oriented Dialogues with Workflows and Action Plans
Jun 02, 2023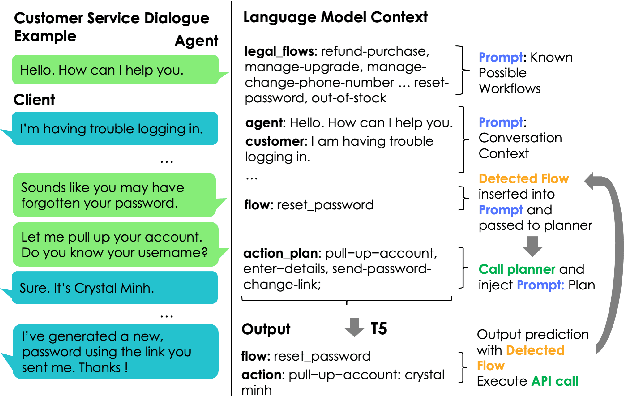

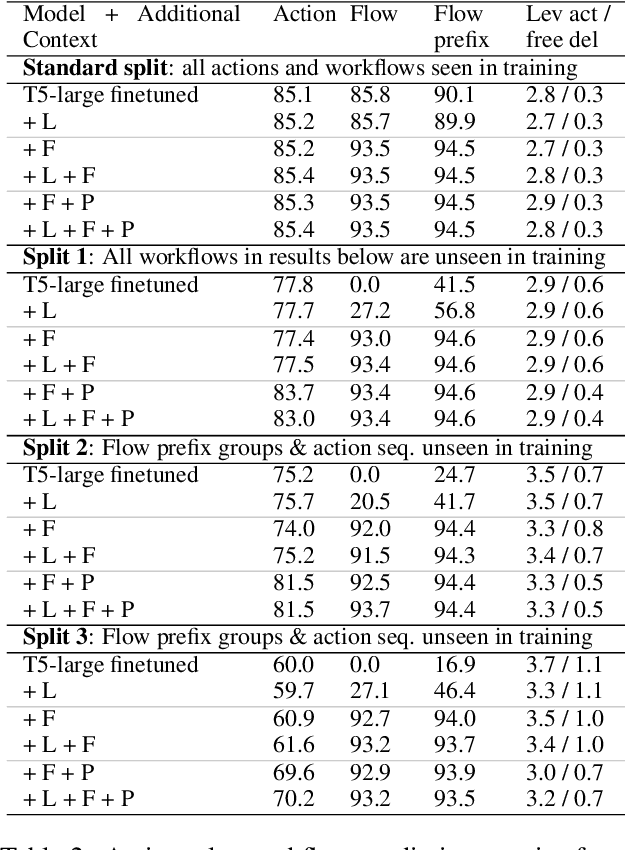
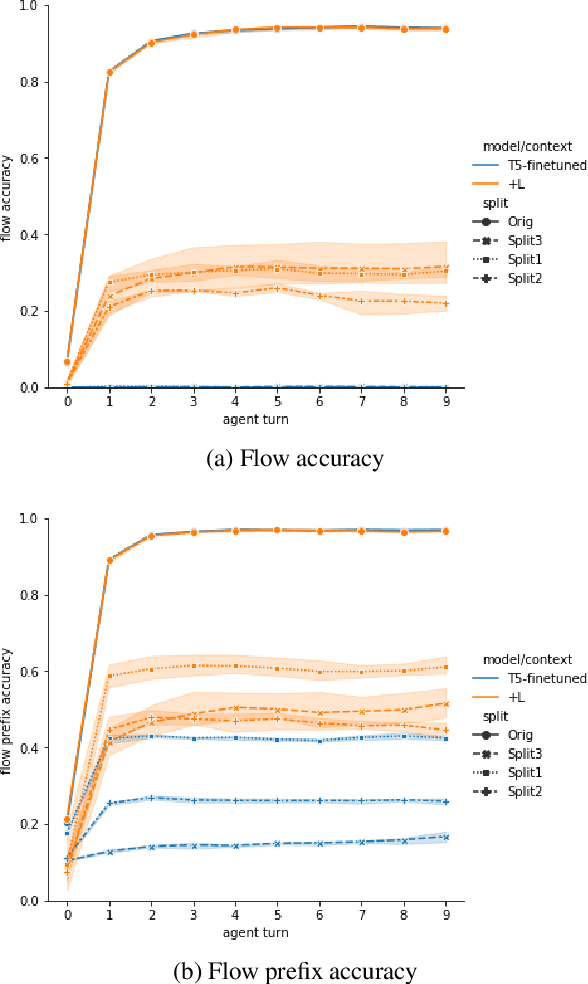
Task-oriented dialogue is difficult in part because it involves understanding user intent, collecting information from the user, executing API calls, and generating helpful and fluent responses. However, for complex tasks one must also correctly do all of these things over multiple steps, and in a specific order. While large pre-trained language models can be fine-tuned end-to-end to create multi-step task-oriented dialogue agents that generate fluent text, our experiments confirm that this approach alone cannot reliably perform new multi-step tasks that are unseen during training. To address these limitations, we augment the dialogue contexts given to \textmd{text2text} transformers with known \textit{valid workflow names} and \textit{action plans}. Action plans consist of sequences of actions required to accomplish a task, and are encoded as simple sequences of keywords (e.g. verify-identity, pull-up-account, reset-password, etc.). We perform extensive experiments on the Action-Based Conversations Dataset (ABCD) with T5-small, base and large models, and show that such models: a) are able to more readily generalize to unseen workflows by following the provided plan, and b) are able to generalize to executing unseen actions if they are provided in the plan. In contrast, models are unable to fully accomplish new multi-step tasks when they are not provided action plan information, even when given new valid workflow names.
Workflow Discovery from Dialogues in the Low Data Regime
May 24, 2022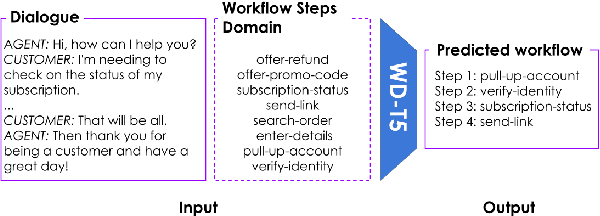

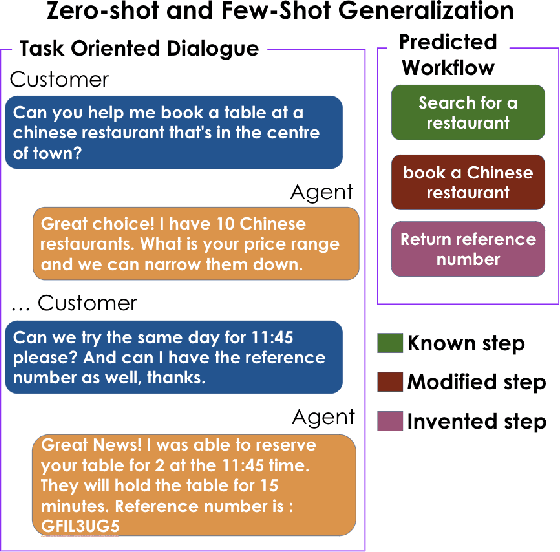

Text-based dialogues are now widely used to solve real-world problems. In cases where solution strategies are already known, they can sometimes be codified into workflows and used to guide humans or artificial agents through the task of helping clients. We are interested in the situation where a formal workflow may not yet exist, but we wish to discover the steps of actions that have been taken to resolve problems. We examine a novel transformer-based approach for this situation and we present experiments where we summarize dialogues in the Action-Based Conversations Dataset (ABCD) with workflows. Since the ABCD dialogues were generated using known workflows to guide agents we can evaluate our ability to extract such workflows using ground truth sequences of action steps, organized as workflows. We propose and evaluate an approach that conditions models on the set of allowable action steps and we show that using this strategy we can improve workflow discovery (WD) performance. Our conditioning approach also improves zero-shot and few-shot WD performance when transferring learned models to entirely new domains (i.e. the MultiWOZ setting). Further, a modified variant of our architecture achieves state-of-the-art performance on the related but different problems of Action State Tracking (AST) and Cascading Dialogue Success (CDS) on the ABCD.
Sex, drugs, and violence
Aug 11, 2016



Automatically detecting inappropriate content can be a difficult NLP task, requiring understanding context and innuendo, not just identifying specific keywords. Due to the large quantity of online user-generated content, automatic detection is becoming increasingly necessary. We take a largely unsupervised approach using a large corpus of narratives from a community-based self-publishing website and a small segment of crowd-sourced annotations. We explore topic modelling using latent Dirichlet allocation (and a variation), and use these to regress appropriateness ratings, effectively automating rating for suitability. The results suggest that certain topics inferred may be useful in detecting latent inappropriateness -- yielding recall up to 96% and low regression errors.