 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Check: Unleashing Potentials for Self-Correction in Large Language Models
Feb 23, 2024



Large language models (LLMs) have made significant strides in reasoning capabilities, with ongoing efforts to refine their reasoning through self-correction. However, recent studies suggest that self-correction can be limited or even counterproductive without external accurate knowledge, raising questions about the limits and effectiveness of self-correction. In this paper, we aim to enhance LLM's self-checking capabilities by meticulously designing training data, thereby improving the accuracy of self-correction. We conduct a detailed analysis of error types in mathematical reasoning and develop a tailored prompt, termed "Step CoT Check". Then we construct a checking-correction dataset for training models. After integrating the original CoT data and checking-correction data for training, we observe that models could improve their self-checking capabilities, thereby enhancing their self-correction capacity and eliminating the need for external feedback or ground truth labels to ascertain the endpoint of correction. We compare the performance of models fine-tuned with the "Step CoT Check" prompt against those refined using other promps within the context of checking-correction data. The "Step CoT Check" outperforms the other two check formats in model with lager parameters, providing more precise feedback thus achieving a higher rate of correctness. For reproducibility, all the datasets and codes are provided in https://github.com/bammt/Learn-to-check.
DialCoT Meets PPO: Decomposing and Exploring Reasoning Paths in Smaller Language Models
Oct 23, 2023Chain-of-Thought (CoT) prompting has proven to be effective in enhancing the reasoning capabilities of Large Language Models (LLMs) with at least 100 billion parameters. However, it is ineffective or even detrimental when applied to reasoning tasks in Smaller Language Models (SLMs) with less than 10 billion parameters. To address this limitation, we introduce Dialogue-guided Chain-of-Thought (DialCoT) which employs a dialogue format to generate intermediate reasoning steps, guiding the model toward the final answer. Additionally, we optimize the model's reasoning path selection using the Proximal Policy Optimization (PPO) algorithm, further enhancing its reasoning capabilities. Our method offers several advantages compared to previous approaches. Firstly, we transform the process of solving complex reasoning questions by breaking them down into a series of simpler sub-questions, significantly reducing the task difficulty and making it more suitable for SLMs. Secondly, we optimize the model's reasoning path selection through the PPO algorithm. We conduct comprehensive experiments on four arithmetic reasoning datasets, demonstrating that our method achieves significant performance improvements compared to state-of-the-art competitors.
LiveChat: A Large-Scale Personalized Dialogue Dataset Automatically Constructed from Live Streaming
Jun 14, 2023



Open-domain dialogue systems have made promising progress in recent years. While the state-of-the-art dialogue agents are built upon large-scale text-based social media data and large pre-trained models, there is no guarantee these agents could also perform well in fast-growing scenarios, such as live streaming, due to the bounded transferability of pre-trained models and biased distributions of public datasets from Reddit and Weibo, etc. To improve the essential capability of responding and establish a benchmark in the live open-domain scenario, we introduce the LiveChat dataset, composed of 1.33 million real-life Chinese dialogues with almost 3800 average sessions across 351 personas and fine-grained profiles for each persona. LiveChat is automatically constructed by processing numerous live videos on the Internet and naturally falls within the scope of multi-party conversations, where the issues of Who says What to Whom should be considered. Therefore, we target two critical tasks of response modeling and addressee recognition and propose retrieval-based baselines grounded on advanced techniques. Experimental results have validated the positive effects of leveraging persona profiles and larger average sessions per persona. In addition, we also benchmark the transferability of advanced generation-based models on LiveChat and pose some future directions for current challenges.
Hierarchical Verbalizer for Few-Shot Hierarchical Text Classification
May 26, 2023Due to the complex label hierarchy and intensive labeling cost in practice, the hierarchical text classification (HTC) suffers a poor performance especially when low-resource or few-shot settings are considered. Recently, there is a growing trend of applying prompts on pre-trained language models (PLMs), which has exhibited effectiveness in the few-shot flat text classification tasks. However, limited work has studied the paradigm of prompt-based learning in the HTC problem when the training data is extremely scarce. In this work, we define a path-based few-shot setting and establish a strict path-based evaluation metric to further explore few-shot HTC tasks. To address the issue, we propose the hierarchical verbalizer ("HierVerb"), a multi-verbalizer framework treating HTC as a single- or multi-label classification problem at multiple layers and learning vectors as verbalizers constrained by hierarchical structure and hierarchical contrastive learning. In this manner, HierVerb fuses label hierarchy knowledge into verbalizers and remarkably outperforms those who inject hierarchy through graph encoders, maximizing the benefits of PLMs. Extensive experiments on three popular HTC datasets under the few-shot settings demonstrate that prompt with HierVerb significantly boosts the HTC performance, meanwhile indicating an elegant way to bridge the gap between the large pre-trained model and downstream hierarchical classification tasks. Our code and few-shot dataset are publicly available at https://github.com/1KE-JI/HierVerb.
Detecting Log Anomalies with Multi-Head Attention (LAMA)
Jan 07, 2021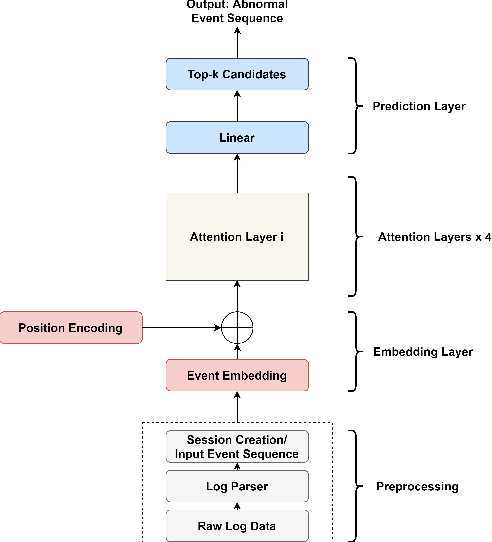

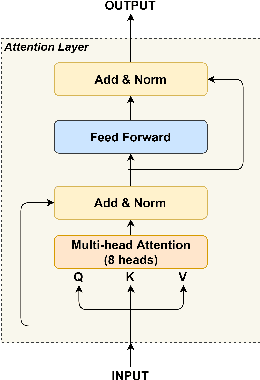
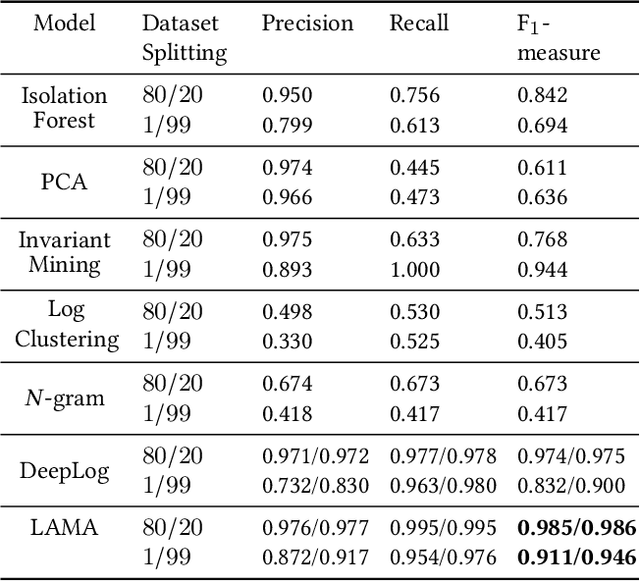
Anomaly detection is a crucial and challenging subject that has been studied within diverse research areas. In this work, we explore the task of log anomaly detection (especially computer system logs and user behavior logs) by analyzing logs' sequential information. We propose LAMA, a multi-head attention based sequential model to process log streams as template activity (event) sequences. A next event prediction task is applied to train the model for anomaly detection. Extensive empirical studies demonstrate that our new model outperforms existing log anomaly detection methods including statistical and deep learning methodologies, which validate the effectiveness of our proposed method in learning sequence patterns of log data.
MultiWOZ 2.3: A multi-domain task-oriented dataset enhanced with annotation corrections and co-reference annotation
Oct 12, 2020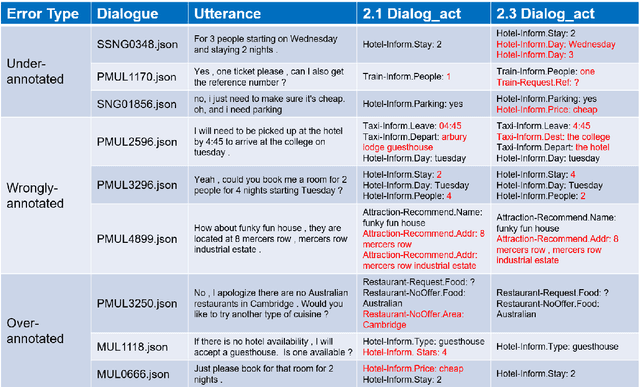
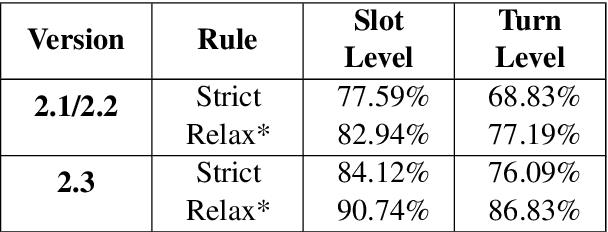

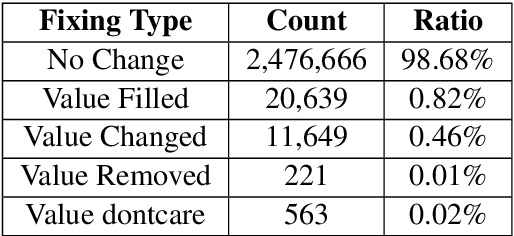
Task-oriented dialogue systems have made unprecedented progress with multiple state-of-the-art (SOTA) models underpinned by a number of publicly available MultiWOZ datasets. Dialogue state annotations are error-prone, leading to sub-optimal performance. Various efforts have been put in rectifying the annotation errors presented in the original MultiWOZ dataset. In this paper, we introduce MultiWOZ 2.3, in which we differentiate incorrect annotations in dialogue acts from dialogue states, identifying a lack of co-reference when publishing the updated dataset. To ensure consistency between dialogue acts and dialogue states, we implement co-reference features and unify annotations of dialogue acts and dialogue states. We update the state of the art performance of natural language understanding and dialog state tracking on MultiWOZ 2.3, where the results show significant improvements than on previous versions of MultiWOZ datasets (2.0-2.2).