 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARL: Encouraging Diverse Answers for General Reasoning without Verifiers
Jan 21, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has demonstrated promising gains in enhancing the reasoning capabilities of large language models. However, its dependence on domain-specific verifiers significantly restricts its applicability to open and general domains. Recent efforts such as RLPR have extended RLVR to general domains, enabling training on broader datasets and achieving improvements over RLVR. However, a notable limitation of these methods is their tendency to overfit to reference answers, which constrains the model's ability to generate diverse outputs. This limitation is particularly pronounced in open-ended tasks such as writing, where multiple plausible answers exist. To address this, we propose DARL, a simple yet effective reinforcement learning framework that encourages the generation of diverse answers within a controlled deviation range from the reference while preserving alignment with it. Our framework is fully compatible with existing general reinforcement learning methods and can be seamlessly integrated without additional verifiers. Extensive experiments on thirteen benchmarks demonstrate consistent improvements in reasoning performance. Notably, DARL surpasses RLPR, achieving average gains of 1.3 points on six reasoning benchmarks and 9.5 points on seven general benchmarks, highlighting its effectiveness in improving both reasoning accuracy and output diversity.
How Well Do Large Reasoning Models Translate? A Comprehensive Evaluation for Multi-Domain Machine Translation
May 26, 2025Large language models (LLMs) have demonstrated strong performance in general-purpose machine translation, but their effectiveness in complex, domain-sensitive translation tasks remains underexplored. Recent advancements in Large Reasoning Models (LRMs), raise the question of whether structured reasoning can enhance translation quality across diverse domains. In this work, we compare the performance of LRMs with traditional LLMs across 15 representative domains and four translation directions. Our evaluation considers various factors, including task difficulty, input length, and terminology density. We use a combination of automatic metrics and an enhanced MQM-based evaluation hierarchy to assess translation quality. Our findings show that LRMs consistently outperform traditional LLMs in semantically complex domains, especially in long-text and high-difficulty translation scenarios. Moreover, domain-adaptive prompting strategies further improve performance by better leveraging the reasoning capabilities of LRMs. These results highlight the potential of structured reasoning in MDMT tasks and provide valuable insights for optimizing translation systems in domain-sensitive contexts.
Coreference Augmentation for Multi-Domain Task-Oriented Dialogue State Tracking
Jun 16, 2021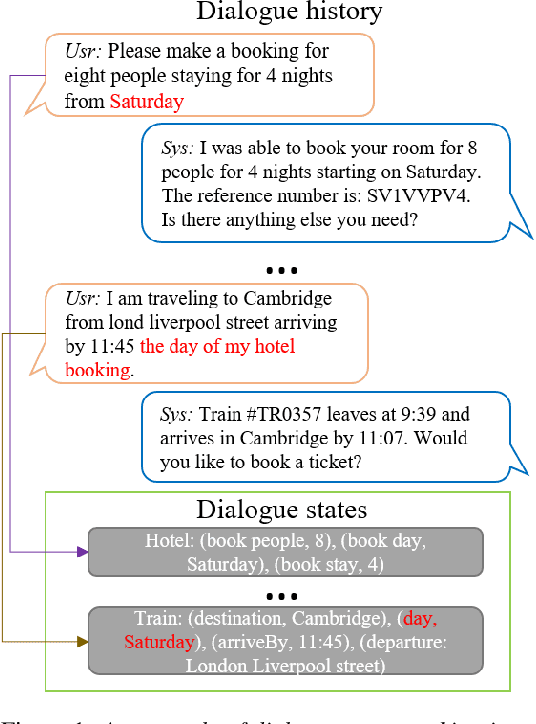
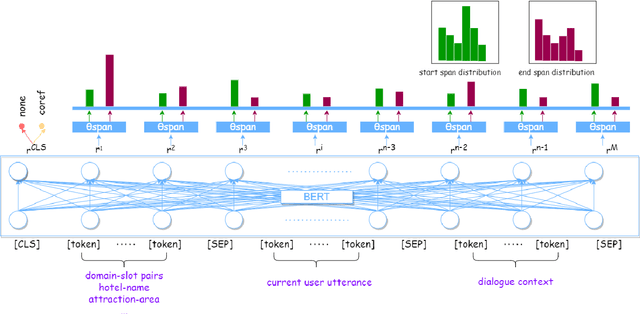
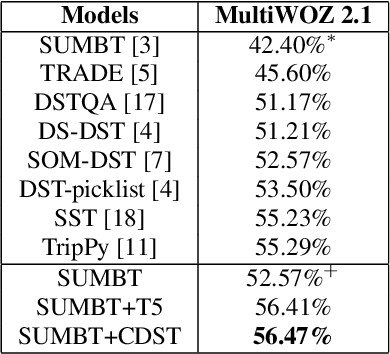
Dialogue State Tracking (DST), which is the process of inferring user goals by estimating belief states given the dialogue history, plays a critical role in task-oriented dialogue systems. A coreference phenomenon observed in multi-turn conversations is not addressed by existing DST models, leading to sub-optimal performances. In this paper, we propose Coreference Dialogue State Tracker (CDST) that explicitly models the coreference feature. In particular, at each turn, the proposed model jointly predicts the coreferred domain-slot pair and extracts the coreference values from the dialogue context. Experimental results on MultiWOZ 2.1 dataset show that the proposed model achieves the state-of-the-art joint goal accuracy of 56.47%.
MultiWOZ 2.3: A multi-domain task-oriented dataset enhanced with annotation corrections and co-reference annotation
Oct 12, 2020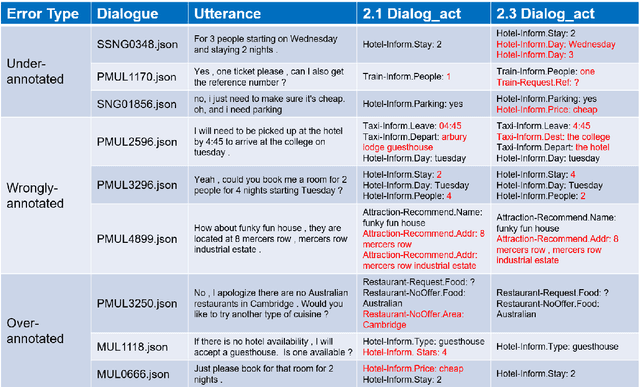
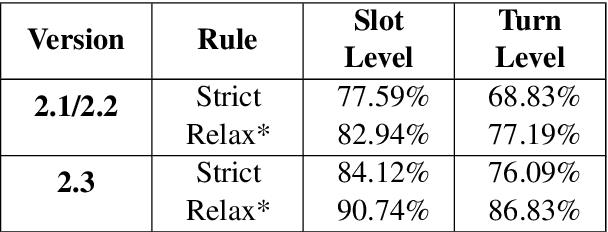

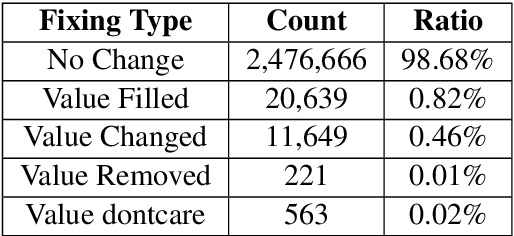
Task-oriented dialogue systems have made unprecedented progress with multiple state-of-the-art (SOTA) models underpinned by a number of publicly available MultiWOZ datasets. Dialogue state annotations are error-prone, leading to sub-optimal performance. Various efforts have been put in rectifying the annotation errors presented in the original MultiWOZ dataset. In this paper, we introduce MultiWOZ 2.3, in which we differentiate incorrect annotations in dialogue acts from dialogue states, identifying a lack of co-reference when publishing the updated dataset. To ensure consistency between dialogue acts and dialogue states, we implement co-reference features and unify annotations of dialogue acts and dialogue states. We update the state of the art performance of natural language understanding and dialog state tracking on MultiWOZ 2.3, where the results show significant improvements than on previous versions of MultiWOZ datasets (2.0-2.2).
Dictionary-based Data Augmentation for Cross-Domain Neural Machine Translation
Apr 06, 2020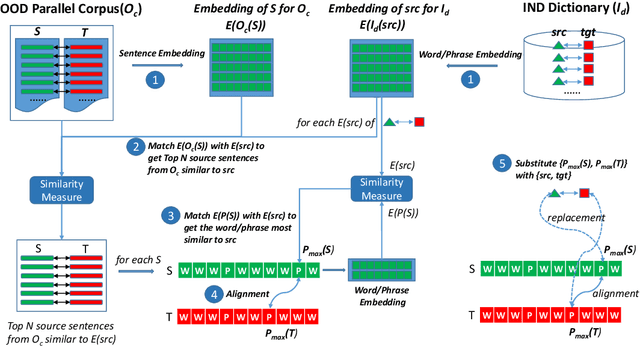
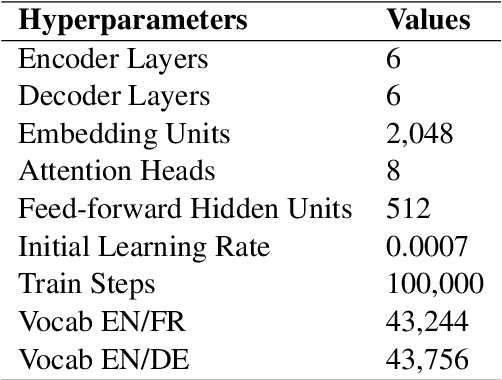

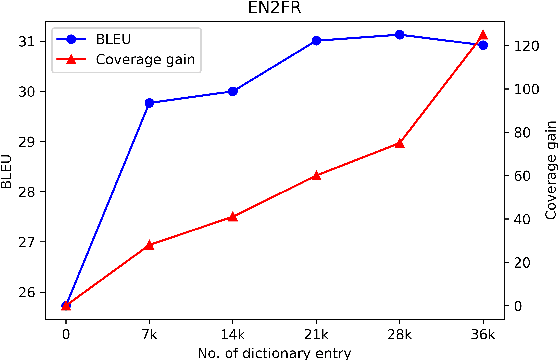
Existing data augmentation approaches for neural machine translation (NMT) have predominantly relied on back-translating in-domain (IND) monolingual corpora. These methods suffer from issues associated with a domain information gap, which leads to translation errors for low frequency and out-of-vocabulary terminology. This paper proposes a dictionary-based data augmentation (DDA) method for cross-domain NMT. DDA synthesizes a domain-specific dictionary with general domain corpora to automatically generate a large-scale pseudo-IND parallel corpus. The generated pseudo-IND data can be used to enhance a general domain trained baseline. The experiments show that the DDA-enhanced NMT models demonstrate consistent significant improvements, outperforming the baseline models by 3.75-11.53 BLEU. The proposed method is also able to further improve the performance of the back-translation based and IND-finetuned NMT models. The improvement is associated with the enhanced domain coverage produced by DDA.