 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccidentBlip2: Accident Detection With Multi-View MotionBlip2
Apr 19, 2024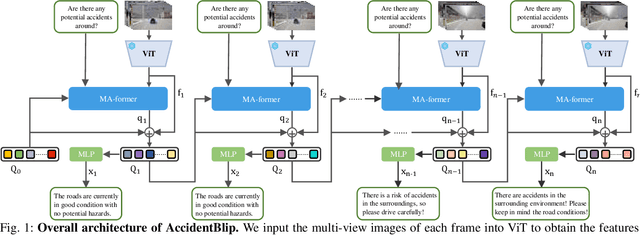
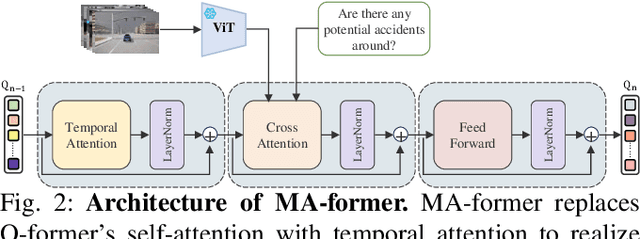
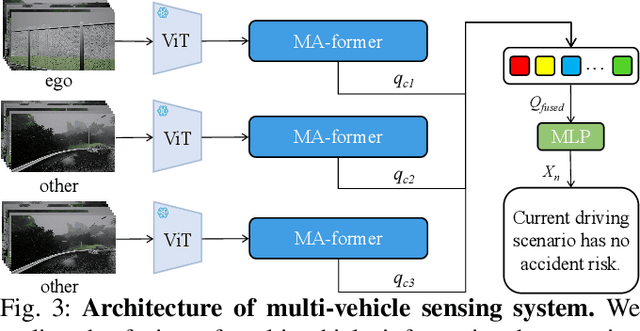

Multimodal Large Language Models (MLLMs) have shown outstanding capabilities in many areas of multimodal reasoning. Therefore, we use the reasoning ability of Multimodal Large Language Models for environment description and scene understanding in complex transportation environments. In this paper, we propose AccidentBlip2, a multimodal large language model that can predict in real time whether an accident risk will occur. Our approach involves feature extraction based on the temporal scene of the six-view surround view graphs and temporal inference using the temporal blip framework through the vision transformer. We then input the generated temporal token into the MLLMs for inference to determine whether an accident will occur or not. Since AccidentBlip2 does not rely on any BEV images and LiDAR, the number of inference parameters and the inference cost of MLLMs can be significantly reduced, and it also does not incur a large training overhead during training. AccidentBlip2 outperforms existing solutions on the DeepAccident dataset and can also provide a reference solution for end-to-end automated driving accident prediction.