 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Controlled Reevaluation of Coreference Resolution Models
Paper and Code

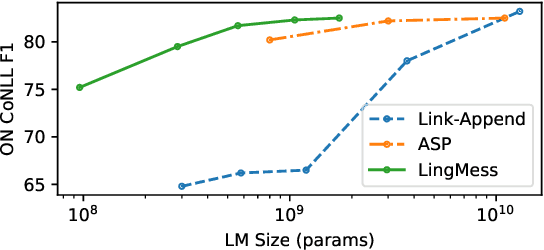
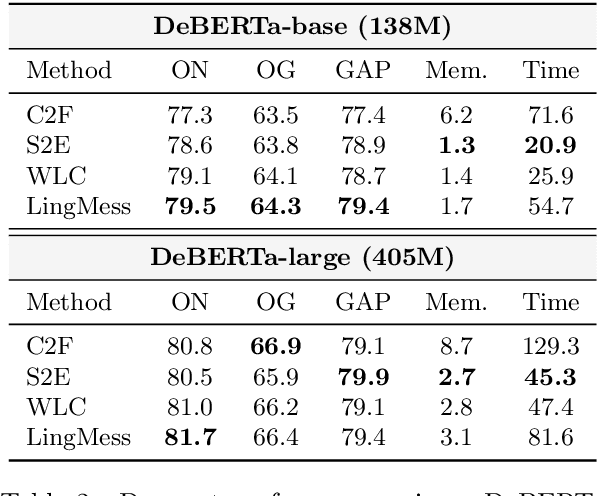

All state-of-the-art coreference resolution (CR) models involve finetuning a pretrained language model. Whether the superior performance of one CR model over another is due to the choice of language model or other factors, such as the task-specific architecture, is difficult or impossible to determine due to lack of a standardized experimental setup. To resolve this ambiguity, we systematically evaluate five CR models and control for certain design decisions including the pretrained language model used by each. When controlling for language model size, encoder-based CR models outperform more recent decoder-based models in terms of both accuracy and inference speed. Surprisingly, among encoder-based CR models, more recent models are not always more accurate, and the oldest CR model that we test generalizes the best to out-of-domain textual genres. We conclude that controlling for the choice of language model reduces most, but not all, of the increase in F1 score reported in the past five years.